 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysical probes expose and alleviate chemical-environment collapse in molecular representations
May 11, 2026Nuclear magnetic resonance (NMR) spectroscopy provides an experimental readout of local chemical environments, but its use in molecular representation learning has been constrained by heterogeneous data and incomplete atom-level assignments. Here we construct complementary high-fidelity experimental and computational 13C NMR resources, which reveal a recurrent form of representational collapse: atoms that are equivalent in molecular topology can remain experimentally distinct in their real chemical environments, whereas explicit 3D descriptions are further limited by static conformations in dynamic regimes. To alleviate this bottleneck, we develop CLAIM (Contrastive Learning for Atom-to-molecule Inference of Molecular NMR), a framework that aligns efficient topological molecular inputs with atom-resolved NMR observables. Through hierarchical chemical priors and cross-level contrastive learning, CLAIM restores lost chemical resolution and markedly improves atom-level molecule-spectrum retrieval. CLAIM remains robust in flexible and tautomeric systems for 13C NMR prediction, improves stereoisomer discrimination without explicit 3D modelling, and transfers to broader molecular property tasks including ADMET prediction and fluorescence estimation. These results establish physically grounded spectral alignment as an effective strategy for alleviating chemical-environment collapse and for guiding experimentally grounded molecular representation learning.
Copyright Detective: A Forensic System to Evidence LLMs Flickering Copyright Leakage Risks
Feb 05, 2026We present Copyright Detective, the first interactive forensic system for detecting, analyzing, and visualizing potential copyright risks in LLM outputs. The system treats copyright infringement versus compliance as an evidence discovery process rather than a static classification task due to the complex nature of copyright law. It integrates multiple detection paradigms, including content recall testing, paraphrase-level similarity analysis, persuasive jailbreak probing, and unlearning verification, within a unified and extensible framework. Through interactive prompting, response collection, and iterative workflows, our system enables systematic auditing of verbatim memorization and paraphrase-level leakage, supporting responsible deployment and transparent evaluation of LLM copyright risks even with black-box access.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
VicSim: Enhancing Victim Simulation with Emotional and Linguistic Fidelity
Jan 06, 2025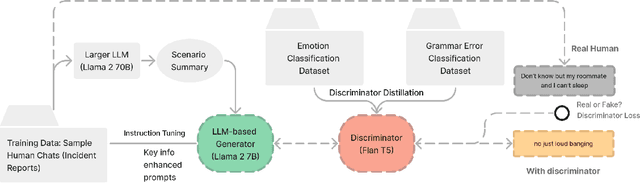



Scenario-based training has been widely adopted in many public service sectors. Recent advancements in Large Language Models (LLMs) have shown promise in simulating diverse personas to create these training scenarios. However, little is known about how LLMs can be developed to simulate victims for scenario-based training purposes. In this paper, we introduce VicSim (victim simulator), a novel model that addresses three key dimensions of user simulation: informational faithfulness, emotional dynamics, and language style (e.g., grammar usage). We pioneer the integration of scenario-based victim modeling with GAN-based training workflow and key-information-based prompting, aiming to enhance the realism of simulated victims. Our adversarial training approach teaches the discriminator to recognize grammar and emotional cues as reliable indicators of synthetic content. According to evaluations by human raters, the VicSim model outperforms GPT-4 in terms of human-likeness.
ValueCompass: A Framework of Fundamental Values for Human-AI Alignment
Sep 15, 2024



As AI systems become more advanced, ensuring their alignment with a diverse range of individuals and societal values becomes increasingly critical. But how can we capture fundamental human values and assess the degree to which AI systems align with them? We introduce ValueCompass, a framework of fundamental values, grounded in psychological theory and a systematic review, to identify and evaluate human-AI alignment. We apply ValueCompass to measure the value alignment of humans and language models (LMs) across four real-world vignettes: collaborative writing, education, public sectors, and healthcare. Our findings uncover risky misalignment between humans and LMs, such as LMs agreeing with values like "Choose Own Goals", which are largely disagreed by humans. We also observe values vary across vignettes, underscoring the necessity for context-aware AI alignment strategies. This work provides insights into the design space of human-AI alignment, offering foundations for developing AI that responsibly reflects societal values and ethics.
Social Life Simulation for Non-Cognitive Skills Learning
May 01, 2024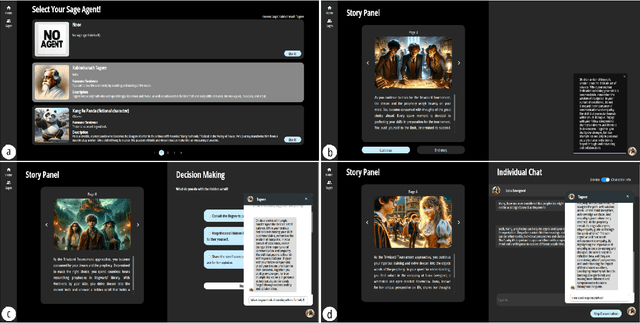
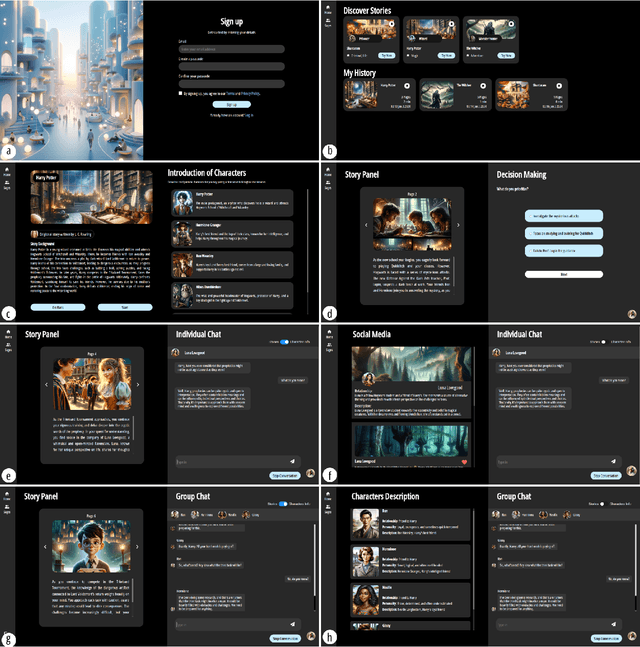
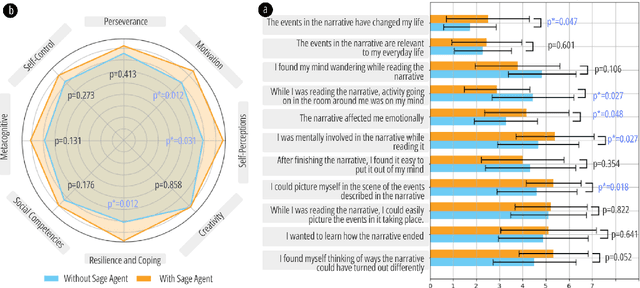
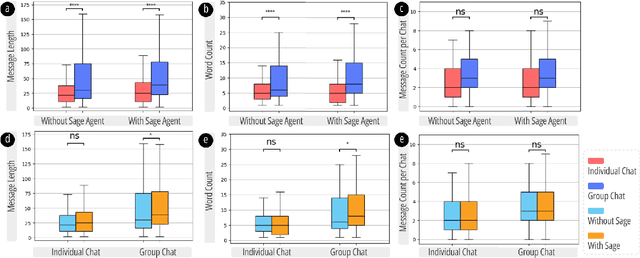
Non-cognitive skills are crucial for personal and social life well-being, and such skill development can be supported by narrative-based (e.g., storytelling) technologies. While generative AI enables interactive and role-playing storytelling, little is known about how users engage with and perceive the use of AI in social life simulation for non-cognitive skills learning. To this end, we introduced SimuLife++, an interactive platform enabled by a large language model (LLM). The system allows users to act as protagonists, creating stories with one or multiple AI-based characters in diverse social scenarios. In particular, we expanded the Human-AI interaction to a Human-AI-AI collaboration by including a sage agent, who acts as a bystander to provide users with more insightful perspectives on their choices and conversations. Through a within-subject user study, we found that the inclusion of the sage agent significantly enhanced narrative immersion, according to the narrative transportation scale, leading to more messages, particularly in group chats. Participants' interactions with the sage agent were also associated with significantly higher scores in their perceived motivation, self-perceptions, and resilience and coping, indicating positive impacts on non-cognitive skills reflection. Participants' interview results further explained the sage agent's aid in decision-making, solving ethical dilemmas, and problem-solving; on the other hand, they suggested improvements in user control and balanced responses from multiple characters. We provide design implications on the application of generative AI in narrative solutions for non-cognitive skill development in broader social contexts.
Reference-based Metrics Disprove Themselves in Question Generation
Mar 18, 2024Reference-based metrics such as BLEU and BERTScore are widely used to evaluate question generation (QG). In this study, on QG benchmarks such as SQuAD and HotpotQA, we find that using human-written references cannot guarantee the effectiveness of the reference-based metrics. Most QG benchmarks have only one reference; we replicated the annotation process and collect another reference. A good metric was expected to grade a human-validated question no worse than generated questions. However, the results of reference-based metrics on our newly collected reference disproved the metrics themselves. We propose a reference-free metric consisted of multi-dimensional criteria such as naturalness, answerability, and complexity, utilizing large language models. These criteria are not constrained to the syntactic or semantic of a single reference question, and the metric does not require a diverse set of references. Experiments reveal that our metric accurately distinguishes between high-quality questions and flawed ones, and achieves state-of-the-art alignment with human judgment.
The Self 2.0: How AI-Enhanced Self-Clones Transform Self-Perception and Improve Presentation Skills
Oct 23, 2023This study explores the impact of AI-generated digital self-clones on improving online presentation skills. We carried out a mixed-design experiment involving 44 international students, comparing self-recorded videos (control) with self-clone videos (AI group) for English presentation practice. The AI videos utilized voice cloning, face swapping, lip-sync, and body-language simulation to refine participants' original presentations in terms of repetition, filler words, and pronunciation. Machine-rated scores indicated enhancements in speech performance for both groups. Though the groups didn't significantly differ, the AI group exhibited a heightened depth of reflection, self-compassion, and a meaningful transition from a corrective to an enhancive approach to self-critique. Within the AI group, congruence between self-perception and AI self-clones resulted in diminished speech anxiety and increased enjoyment. Our findings recommend the ethical employment of digital self-clones to enhance the emotional and cognitive facets of skill development.
Synergizing Human-AI Agency: A Guide of 23 Heuristics for Service Co-Creation with LLM-Based Agents
Oct 23, 2023



This empirical study serves as a primer for interested service providers to determine if and how Large Language Models (LLMs) technology will be integrated for their practitioners and the broader community. We investigate the mutual learning journey of non-AI experts and AI through CoAGent, a service co-creation tool with LLM-based agents. Engaging in a three-stage participatory design processes, we work with with 23 domain experts from public libraries across the U.S., uncovering their fundamental challenges of integrating AI into human workflows. Our findings provide 23 actionable "heuristics for service co-creation with AI", highlighting the nuanced shared responsibilities between humans and AI. We further exemplar 9 foundational agency aspects for AI, emphasizing essentials like ownership, fair treatment, and freedom of expression. Our innovative approach enriches the participatory design model by incorporating AI as crucial stakeholders and utilizing AI-AI interaction to identify blind spots. Collectively, these insights pave the way for synergistic and ethical human-AI co-creation in service contexts, preparing for workforce ecosystems where AI coexists.