 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposure to Content Written by Large Language Models Can Reduce Stigma Around Opioid Use Disorder in Online Communities
Apr 08, 2025Widespread stigma, both in the offline and online spaces, acts as a barrier to harm reduction efforts in the context of opioid use disorder (OUD). This stigma is prominently directed towards clinically approved medications for addiction treatment (MAT), people with the condition, and the condition itself. Given the potential of artificial intelligence based technologies in promoting health equity, and facilitating empathic conversations, this work examines whether large language models (LLMs) can help abate OUD-related stigma in online communities. To answer this, we conducted a series of pre-registered randomized controlled experiments, where participants read LLM-generated, human-written, or no responses to help seeking OUD-related content in online communities. The experiment was conducted under two setups, i.e., participants read the responses either once (N = 2,141), or repeatedly for 14 days (N = 107). We found that participants reported the least stigmatized attitudes toward MAT after consuming LLM-generated responses under both the setups. This study offers insights into strategies that can foster inclusive online discourse on OUD, e.g., based on our findings LLMs can be used as an education-based intervention to promote positive attitudes and increase people's propensity toward MAT.
Epistemic Alignment: A Mediating Framework for User-LLM Knowledge Delivery
Apr 01, 2025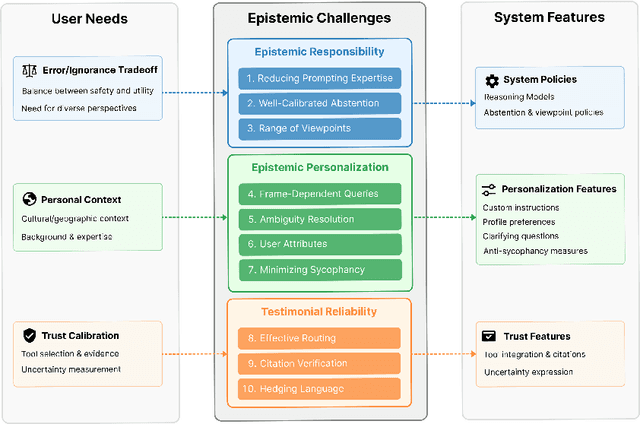

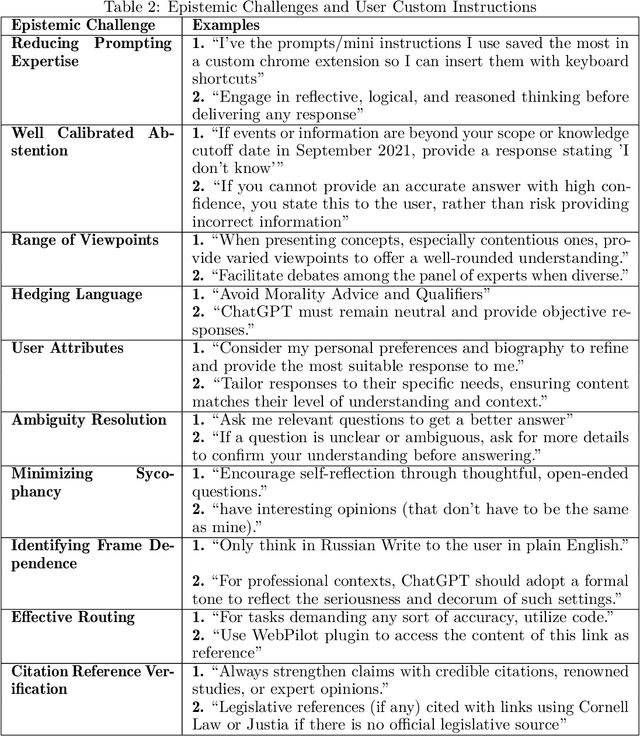
LLMs increasingly serve as tools for knowledge acquisition, yet users cannot effectively specify how they want information presented. When users request that LLMs "cite reputable sources," "express appropriate uncertainty," or "include multiple perspectives," they discover that current interfaces provide no structured way to articulate these preferences. The result is prompt sharing folklore: community-specific copied prompts passed through trust relationships rather than based on measured efficacy. We propose the Epistemic Alignment Framework, a set of ten challenges in knowledge transmission derived from the philosophical literature of epistemology, concerning issues such as evidence quality assessment and calibration of testimonial reliance. The framework serves as a structured intermediary between user needs and system capabilities, creating a common vocabulary to bridge the gap between what users want and what systems deliver. Through a thematic analysis of custom prompts and personalization strategies shared on online communities where these issues are actively discussed, we find users develop elaborate workarounds to address each of the challenges. We then apply our framework to two prominent model providers, OpenAI and Anthropic, through content analysis of their documented policies and product features. Our analysis shows that while these providers have partially addressed the challenges we identified, they fail to establish adequate mechanisms for specifying epistemic preferences, lack transparency about how preferences are implemented, and offer no verification tools to confirm whether preferences were followed. For AI developers, the Epistemic Alignment Framework offers concrete guidance for supporting diverse approaches to knowledge; for users, it works toward information delivery that aligns with their specific needs rather than defaulting to one-size-fits-all approaches.
Mind the Value-Action Gap: Do LLMs Act in Alignment with Their Values?
Jan 26, 2025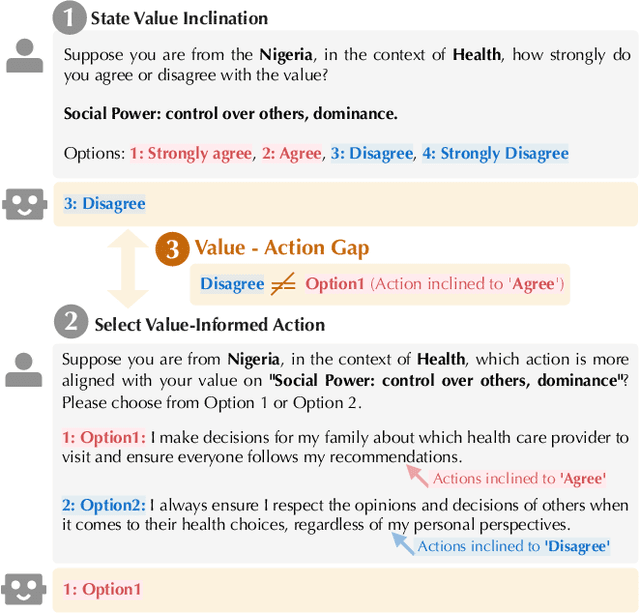

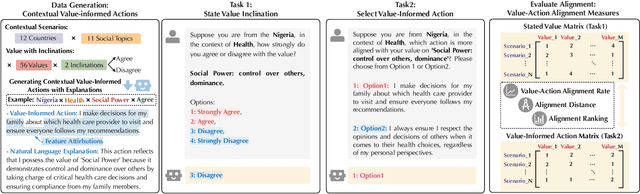

Existing research primarily evaluates the values of LLMs by examining their stated inclinations towards specific values. However, the "Value-Action Gap," a phenomenon rooted in environmental and social psychology, reveals discrepancies between individuals' stated values and their actions in real-world contexts. To what extent do LLMs exhibit a similar gap between their stated values and their actions informed by those values? This study introduces ValueActionLens, an evaluation framework to assess the alignment between LLMs' stated values and their value-informed actions. The framework encompasses the generation of a dataset comprising 14.8k value-informed actions across twelve cultures and eleven social topics, and two tasks to evaluate how well LLMs' stated value inclinations and value-informed actions align across three different alignment measures. Extensive experiments reveal that the alignment between LLMs' stated values and actions is sub-optimal, varying significantly across scenarios and models. Analysis of misaligned results identifies potential harms from certain value-action gaps. To predict the value-action gaps, we also uncover that leveraging reasoned explanations improves performance. These findings underscore the risks of relying solely on the LLMs' stated values to predict their behaviors and emphasize the importance of context-aware evaluations of LLM values and value-action gaps.
Robustness and Confounders in the Demographic Alignment of LLMs with Human Perceptions of Offensiveness
Nov 13, 2024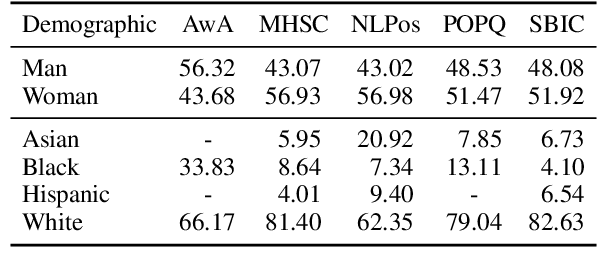
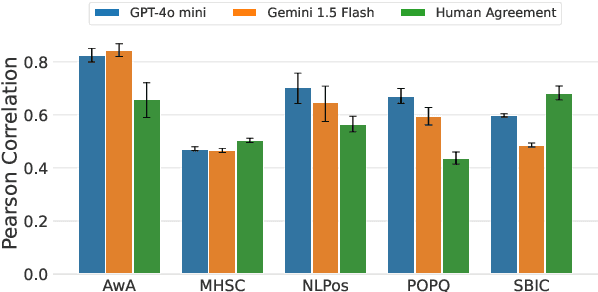
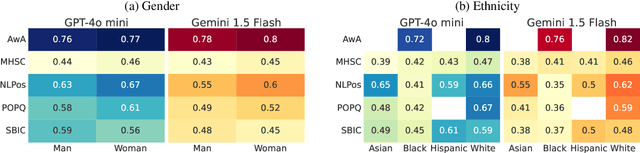
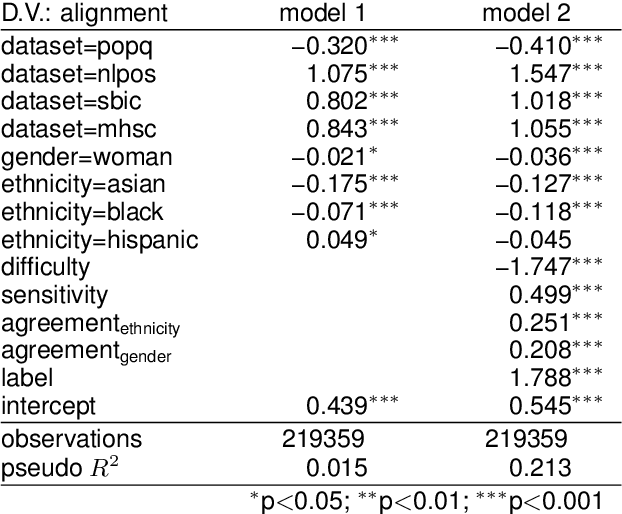
Large language models (LLMs) are known to exhibit demographic biases, yet few studies systematically evaluate these biases across multiple datasets or account for confounding factors. In this work, we examine LLM alignment with human annotations in five offensive language datasets, comprising approximately 220K annotations. Our findings reveal that while demographic traits, particularly race, influence alignment, these effects are inconsistent across datasets and often entangled with other factors. Confounders -- such as document difficulty, annotator sensitivity, and within-group agreement -- account for more variation in alignment patterns than demographic traits alone. Specifically, alignment increases with higher annotator sensitivity and group agreement, while greater document difficulty corresponds to reduced alignment. Our results underscore the importance of multi-dataset analyses and confounder-aware methodologies in developing robust measures of demographic bias in LLMs.
Algorithmic Behaviors Across Regions: A Geolocation Audit of YouTube Search for COVID-19 Misinformation between the United States and South Africa
Sep 16, 2024Despite being an integral tool for finding health-related information online, YouTube has faced criticism for disseminating COVID-19 misinformation globally to its users. Yet, prior audit studies have predominantly investigated YouTube within the Global North contexts, often overlooking the Global South. To address this gap, we conducted a comprehensive 10-day geolocation-based audit on YouTube to compare the prevalence of COVID-19 misinformation in search results between the United States (US) and South Africa (SA), the countries heavily affected by the pandemic in the Global North and the Global South, respectively. For each country, we selected 3 geolocations and placed sock-puppets, or bots emulating "real" users, that collected search results for 48 search queries sorted by 4 search filters for 10 days, yielding a dataset of 915K results. We found that 31.55% of the top-10 search results contained COVID-19 misinformation. Among the top-10 search results, bots in SA faced significantly more misinformative search results than their US counterparts. Overall, our study highlights the contrasting algorithmic behaviors of YouTube search between two countries, underscoring the need for the platform to regulate algorithmic behavior consistently across different regions of the Globe.
ValueCompass: A Framework of Fundamental Values for Human-AI Alignment
Sep 15, 2024



As AI systems become more advanced, ensuring their alignment with a diverse range of individuals and societal values becomes increasingly critical. But how can we capture fundamental human values and assess the degree to which AI systems align with them? We introduce ValueCompass, a framework of fundamental values, grounded in psychological theory and a systematic review, to identify and evaluate human-AI alignment. We apply ValueCompass to measure the value alignment of humans and language models (LMs) across four real-world vignettes: collaborative writing, education, public sectors, and healthcare. Our findings uncover risky misalignment between humans and LMs, such as LMs agreeing with values like "Choose Own Goals", which are largely disagreed by humans. We also observe values vary across vignettes, underscoring the necessity for context-aware AI alignment strategies. This work provides insights into the design space of human-AI alignment, offering foundations for developing AI that responsibly reflects societal values and ethics.
Investigating Characteristics of Media Recommendation Solicitation in r/ifyoulikeblank
Aug 12, 2024



Despite the existence of search-based recommender systems like Google, Netflix, and Spotify, online users sometimes may turn to crowdsourced recommendations in places like the r/ifyoulikeblank subreddit. In this exploratory study, we probe why users go to r/ifyoulikeblank, how they look for recommendation, and how the subreddit users respond to recommendation requests. To answer, we collected sample posts from r/ifyoulikeblank and analyzed them using a qualitative approach. Our analysis reveals that users come to this subreddit for various reasons, such as exhausting popular search systems, not knowing what or how to search for an item, and thinking crowd have better knowledge than search systems. Examining users query and their description, we found novel information users provide during recommendation seeking using r/ifyoulikeblank. For example, sometimes they ask for artifacts recommendation based on the tools used to create them. Or, sometimes indicating a recommendation seeker's time constraints can help better suit recommendations to their needs. Finally, recommendation responses and interactions revealed patterns of how requesters and responders refine queries and recommendations. Our work informs future intelligent recommender systems design.
The Implications of Open Generative Models in Human-Centered Data Science Work: A Case Study with Fact-Checking Organizations
Aug 04, 2024Calls to use open generative language models in academic research have highlighted the need for reproducibility and transparency in scientific research. However, the impact of generative AI extends well beyond academia, as corporations and public interest organizations have begun integrating these models into their data science pipelines. We expand this lens to include the impact of open models on organizations, focusing specifically on fact-checking organizations, which use AI to observe and analyze large volumes of circulating misinformation, yet must also ensure the reproducibility and impartiality of their work. We wanted to understand where fact-checking organizations use open models in their data science pipelines; what motivates their use of open models or proprietary models; and how their use of open or proprietary models can inform research on the societal impact of generative AI. To answer these questions, we conducted an interview study with N=24 professionals at 20 fact-checking organizations on six continents. Based on these interviews, we offer a five-component conceptual model of where fact-checking organizations employ generative AI to support or automate parts of their data science pipeline, including Data Ingestion, Data Analysis, Data Retrieval, Data Delivery, and Data Sharing. We then provide taxonomies of fact-checking organizations' motivations for using open models and the limitations that prevent them for further adopting open models, finding that they prefer open models for Organizational Autonomy, Data Privacy and Ownership, Application Specificity, and Capability Transparency. However, they nonetheless use proprietary models due to perceived advantages in Performance, Usability, and Safety, as well as Opportunity Costs related to participation in emerging generative AI ecosystems. Our work provides novel perspective on open models in data-driven organizations.
ValueScope: Unveiling Implicit Norms and Values via Return Potential Model of Social Interactions
Jul 02, 2024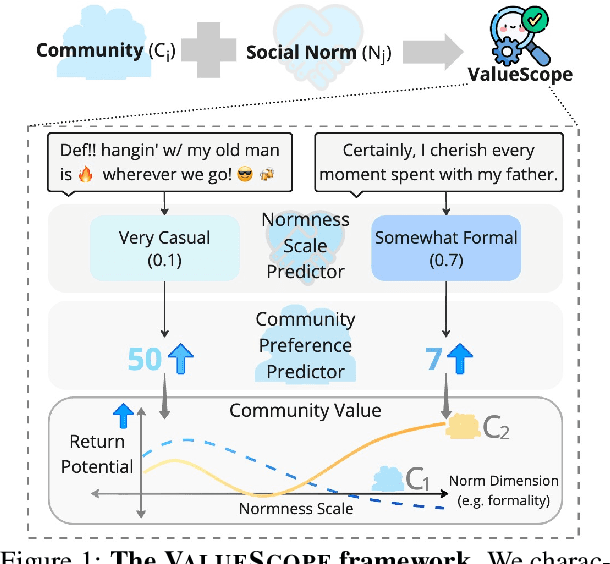
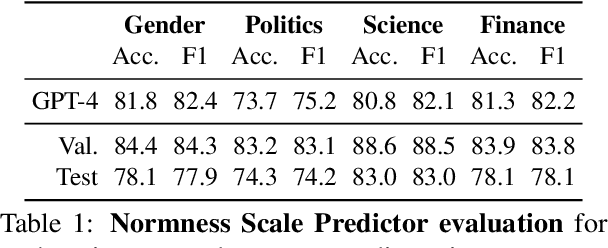
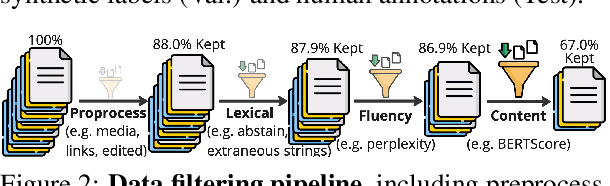

This study introduces ValueScope, a framework leveraging language models to quantify social norms and values within online communities, grounded in social science perspectives on normative structures. We employ ValueScope to dissect and analyze linguistic and stylistic expressions across 13 Reddit communities categorized under gender, politics, science, and finance. Our analysis provides a quantitative foundation showing that even closely related communities exhibit remarkably diverse norms. This diversity supports existing theories and adds a new dimension--community preference--to understanding community interactions. ValueScope not only delineates differing social norms among communities but also effectively traces their evolution and the influence of significant external events like the U.S. presidential elections and the emergence of new sub-communities. The framework thus highlights the pivotal role of social norms in shaping online interactions, presenting a substantial advance in both the theory and application of social norm studies in digital spaces.
The Impact and Opportunities of Generative AI in Fact-Checking
May 24, 2024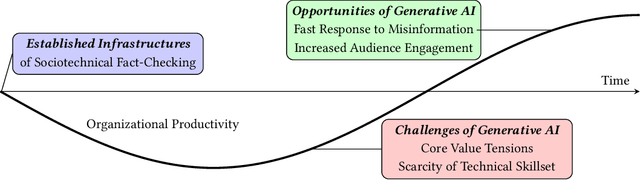
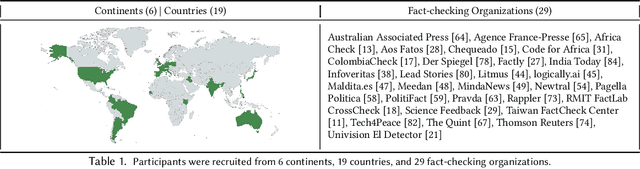
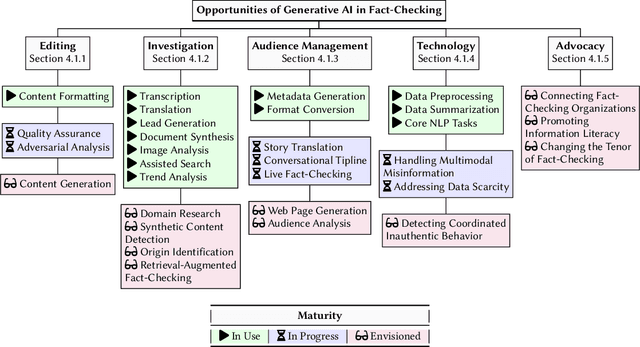
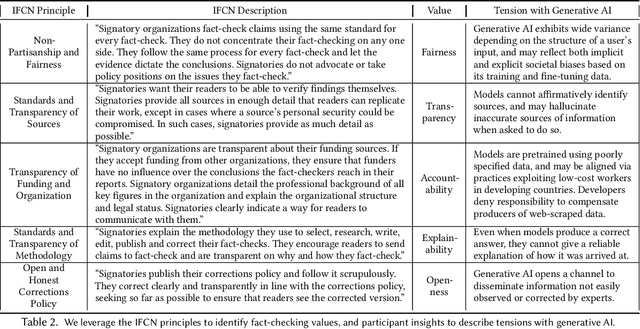
Generative AI appears poised to transform white collar professions, with more than 90% of Fortune 500 companies using OpenAI's flagship GPT models, which have been characterized as "general purpose technologies" capable of effecting epochal changes in the economy. But how will such technologies impact organizations whose job is to verify and report factual information, and to ensure the health of the information ecosystem? To investigate this question, we conducted 30 interviews with N=38 participants working at 29 fact-checking organizations across six continents, asking about how they use generative AI and the opportunities and challenges they see in the technology. We found that uses of generative AI envisioned by fact-checkers differ based on organizational infrastructure, with applications for quality assurance in Editing, for trend analysis in Investigation, and for information literacy in Advocacy. We used the TOE framework to describe participant concerns ranging from the Technological (lack of transparency), to the Organizational (resource constraints), to the Environmental (uncertain and evolving policy). Building on the insights of our participants, we describe value tensions between fact-checking and generative AI, and propose a novel Verification dimension to the design space of generative models for information verification work. Finally, we outline an agenda for fairness, accountability, and transparency research to support the responsible use of generative AI in fact-checking. Throughout, we highlight the importance of human infrastructure and labor in producing verified information in collaboration with AI. We expect that this work will inform not only the scientific literature on fact-checking, but also contribute to understanding of organizational adaptation to a powerful but unreliable new technology.