 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Integrate Spatial Data? Empirical Insights into Reasoning Strengths and Computational Weaknesses
Aug 07, 2025



We explore the application of large language models (LLMs) to empower domain experts in integrating large, heterogeneous, and noisy urban spatial datasets. Traditional rule-based integration methods are unable to cover all edge cases, requiring manual verification and repair. Machine learning approaches require collecting and labeling of large numbers of task-specific samples. In this study, we investigate the potential of LLMs for spatial data integration. Our analysis first considers how LLMs reason about environmental spatial relationships mediated by human experience, such as between roads and sidewalks. We show that while LLMs exhibit spatial reasoning capabilities, they struggle to connect the macro-scale environment with the relevant computational geometry tasks, often producing logically incoherent responses. But when provided relevant features, thereby reducing dependence on spatial reasoning, LLMs are able to generate high-performing results. We then adapt a review-and-refine method, which proves remarkably effective in correcting erroneous initial responses while preserving accurate responses. We discuss practical implications of employing LLMs for spatial data integration in real-world contexts and outline future research directions, including post-training, multi-modal integration methods, and support for diverse data formats. Our findings position LLMs as a promising and flexible alternative to traditional rule-based heuristics, advancing the capabilities of adaptive spatial data integration.
Fragments to Facts: Partial-Information Fragment Inference from LLMs
May 20, 2025Large language models (LLMs) can leak sensitive training data through memorization and membership inference attacks. Prior work has primarily focused on strong adversarial assumptions, including attacker access to entire samples or long, ordered prefixes, leaving open the question of how vulnerable LLMs are when adversaries have only partial, unordered sample information. For example, if an attacker knows a patient has "hypertension," under what conditions can they query a model fine-tuned on patient data to learn the patient also has "osteoarthritis?" In this paper, we introduce a more general threat model under this weaker assumption and show that fine-tuned LLMs are susceptible to these fragment-specific extraction attacks. To systematically investigate these attacks, we propose two data-blind methods: (1) a likelihood ratio attack inspired by methods from membership inference, and (2) a novel approach, PRISM, which regularizes the ratio by leveraging an external prior. Using examples from both medical and legal settings, we show that both methods are competitive with a data-aware baseline classifier that assumes access to labeled in-distribution data, underscoring their robustness.
Epistemic Alignment: A Mediating Framework for User-LLM Knowledge Delivery
Apr 01, 2025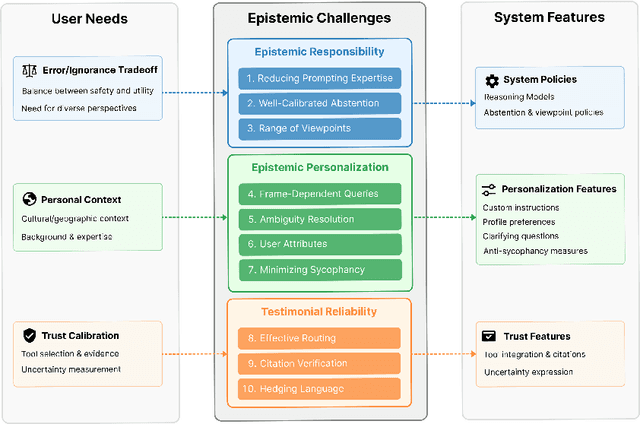

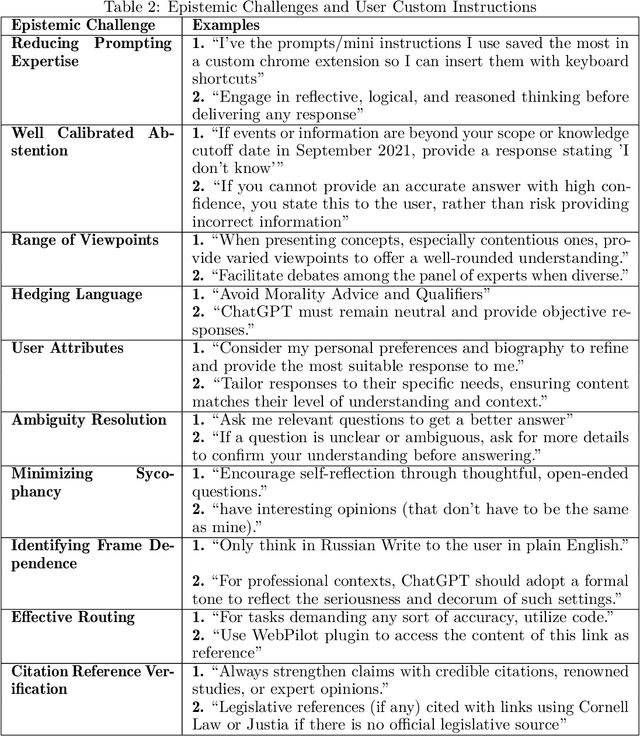
LLMs increasingly serve as tools for knowledge acquisition, yet users cannot effectively specify how they want information presented. When users request that LLMs "cite reputable sources," "express appropriate uncertainty," or "include multiple perspectives," they discover that current interfaces provide no structured way to articulate these preferences. The result is prompt sharing folklore: community-specific copied prompts passed through trust relationships rather than based on measured efficacy. We propose the Epistemic Alignment Framework, a set of ten challenges in knowledge transmission derived from the philosophical literature of epistemology, concerning issues such as evidence quality assessment and calibration of testimonial reliance. The framework serves as a structured intermediary between user needs and system capabilities, creating a common vocabulary to bridge the gap between what users want and what systems deliver. Through a thematic analysis of custom prompts and personalization strategies shared on online communities where these issues are actively discussed, we find users develop elaborate workarounds to address each of the challenges. We then apply our framework to two prominent model providers, OpenAI and Anthropic, through content analysis of their documented policies and product features. Our analysis shows that while these providers have partially addressed the challenges we identified, they fail to establish adequate mechanisms for specifying epistemic preferences, lack transparency about how preferences are implemented, and offer no verification tools to confirm whether preferences were followed. For AI developers, the Epistemic Alignment Framework offers concrete guidance for supporting diverse approaches to knowledge; for users, it works toward information delivery that aligns with their specific needs rather than defaulting to one-size-fits-all approaches.
Know Your Limits: A Survey of Abstention in Large Language Models
Aug 08, 2024



Abstention, the refusal of large language models (LLMs) to provide an answer, is increasingly recognized for its potential to mitigate hallucinations and enhance safety in LLM systems. In this survey, we introduce a framework to examine abstention from three perspectives: the query, the model, and human values. We organize the literature on abstention methods, benchmarks, and evaluation metrics using this framework, and discuss merits and limitations of prior work. We further identify and motivate areas for future work, centered around whether abstention can be achieved as a meta-capability that transcends specific tasks or domains, while still providing opportunities to optimize abstention abilities based on context.
Representation Bias of Adolescents in AI: A Bilingual, Bicultural Study
Aug 04, 2024Popular and news media often portray teenagers with sensationalism, as both a risk to society and at risk from society. As AI begins to absorb some of the epistemic functions of traditional media, we study how teenagers in two countries speaking two languages: 1) are depicted by AI, and 2) how they would prefer to be depicted. Specifically, we study the biases about teenagers learned by static word embeddings (SWEs) and generative language models (GLMs), comparing these with the perspectives of adolescents living in the U.S. and Nepal. We find English-language SWEs associate teenagers with societal problems, and more than 50% of the 1,000 words most associated with teenagers in the pretrained GloVe SWE reflect such problems. Given prompts about teenagers, 30% of outputs from GPT2-XL and 29% from LLaMA-2-7B GLMs discuss societal problems, most commonly violence, but also drug use, mental illness, and sexual taboo. Nepali models, while not free of such associations, are less dominated by social problems. Data from workshops with N=13 U.S. adolescents and N=18 Nepalese adolescents show that AI presentations are disconnected from teenage life, which revolves around activities like school and friendship. Participant ratings of how well 20 trait words describe teens are decorrelated from SWE associations, with Pearson's r=.02, n.s. in English FastText and r=.06, n.s. in GloVe; and r=.06, n.s. in Nepali FastText and r=-.23, n.s. in GloVe. U.S. participants suggested AI could fairly present teens by highlighting diversity, while Nepalese participants centered positivity. Participants were optimistic that, if it learned from adolescents, rather than media sources, AI could help mitigate stereotypes. Our work offers an understanding of the ways SWEs and GLMs misrepresent a developmentally vulnerable group and provides a template for less sensationalized characterization.
Dataset Scale and Societal Consistency Mediate Facial Impression Bias in Vision-Language AI
Aug 04, 2024Multimodal AI models capable of associating images and text hold promise for numerous domains, ranging from automated image captioning to accessibility applications for blind and low-vision users. However, uncertainty about bias has in some cases limited their adoption and availability. In the present work, we study 43 CLIP vision-language models to determine whether they learn human-like facial impression biases, and we find evidence that such biases are reflected across three distinct CLIP model families. We show for the first time that the the degree to which a bias is shared across a society predicts the degree to which it is reflected in a CLIP model. Human-like impressions of visually unobservable attributes, like trustworthiness and sexuality, emerge only in models trained on the largest dataset, indicating that a better fit to uncurated cultural data results in the reproduction of increasingly subtle social biases. Moreover, we use a hierarchical clustering approach to show that dataset size predicts the extent to which the underlying structure of facial impression bias resembles that of facial impression bias in humans. Finally, we show that Stable Diffusion models employing CLIP as a text encoder learn facial impression biases, and that these biases intersect with racial biases in Stable Diffusion XL-Turbo. While pretrained CLIP models may prove useful for scientific studies of bias, they will also require significant dataset curation when intended for use as general-purpose models in a zero-shot setting.
ML-EAT: A Multilevel Embedding Association Test for Interpretable and Transparent Social Science
Aug 04, 2024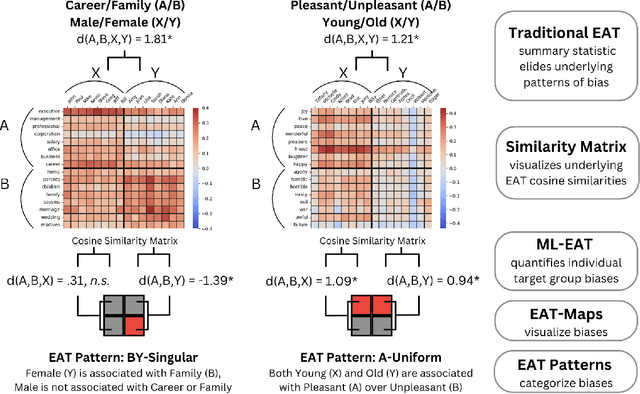
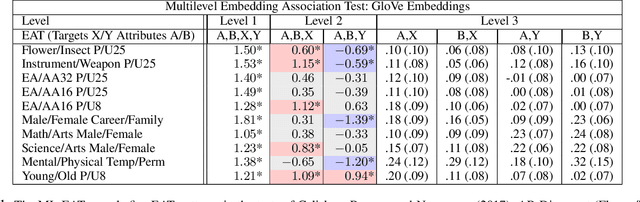
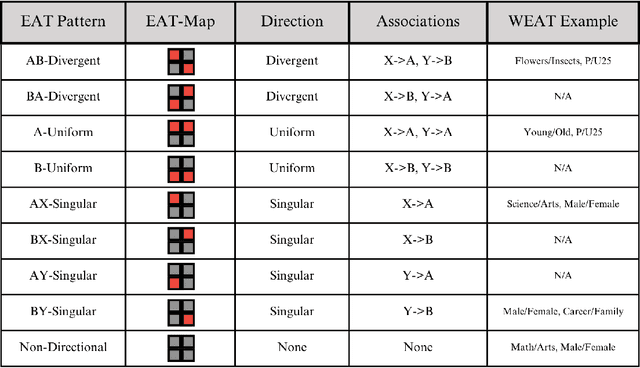
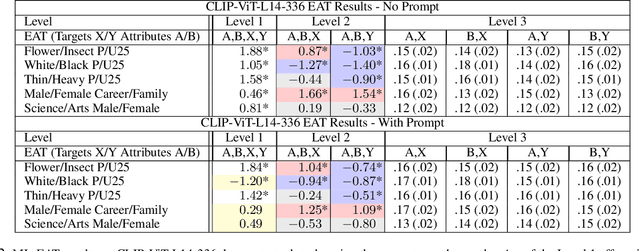
This research introduces the Multilevel Embedding Association Test (ML-EAT), a method designed for interpretable and transparent measurement of intrinsic bias in language technologies. The ML-EAT addresses issues of ambiguity and difficulty in interpreting the traditional EAT measurement by quantifying bias at three levels of increasing granularity: the differential association between two target concepts with two attribute concepts; the individual effect size of each target concept with two attribute concepts; and the association between each individual target concept and each individual attribute concept. Using the ML-EAT, this research defines a taxonomy of EAT patterns describing the nine possible outcomes of an embedding association test, each of which is associated with a unique EAT-Map, a novel four-quadrant visualization for interpreting the ML-EAT. Empirical analysis of static and diachronic word embeddings, GPT-2 language models, and a CLIP language-and-image model shows that EAT patterns add otherwise unobservable information about the component biases that make up an EAT; reveal the effects of prompting in zero-shot models; and can also identify situations when cosine similarity is an ineffective metric, rendering an EAT unreliable. Our work contributes a method for rendering bias more observable and interpretable, improving the transparency of computational investigations into human minds and societies.
Towards Zero-Shot Annotation of the Built Environment with Vision-Language Models (Vision Paper)
Aug 01, 2024Equitable urban transportation applications require high-fidelity digital representations of the built environment: not just streets and sidewalks, but bike lanes, marked and unmarked crossings, curb ramps and cuts, obstructions, traffic signals, signage, street markings, potholes, and more. Direct inspections and manual annotations are prohibitively expensive at scale. Conventional machine learning methods require substantial annotated training data for adequate performance. In this paper, we consider vision language models as a mechanism for annotating diverse urban features from satellite images, reducing the dependence on human annotation to produce large training sets. While these models have achieved impressive results in describing common objects in images captured from a human perspective, their training sets are less likely to include strong signals for esoteric features in the built environment, and their performance in these settings is therefore unclear. We demonstrate proof-of-concept combining a state-of-the-art vision language model and variants of a prompting strategy that asks the model to consider segmented elements independently of the original image. Experiments on two urban features -- stop lines and raised tables -- show that while direct zero-shot prompting correctly annotates nearly zero images, the pre-segmentation strategies can annotate images with near 40% intersection-over-union accuracy. We describe how these results inform a new research agenda in automatic annotation of the built environment to improve equity, accessibility, and safety at broad scale and in diverse environments.
The Art of Refusal: A Survey of Abstention in Large Language Models
Jul 25, 2024Abstention, the refusal of large language models (LLMs) to provide an answer, is increasingly recognized for its potential to mitigate hallucinations and enhance safety in building LLM systems. In this survey, we introduce a framework to examine abstention behavior from three perspectives: the query, the model, and human values. We review the literature on abstention methods (categorized based on the development stages of LLMs), benchmarks, and evaluation metrics, and discuss the merits and limitations of prior work. We further identify and motivate areas for future research, such as encouraging the study of abstention as a meta-capability across tasks and customizing abstention abilities based on context. In doing so, we aim to broaden the scope and impact of abstention methodologies in AI systems.
PathwayBench: Assessing Routability of Pedestrian Pathway Networks Inferred from Multi-City Imagery
Jul 23, 2024



Applications to support pedestrian mobility in urban areas require a complete, and routable graph representation of the built environment. Globally available information, including aerial imagery provides a scalable source for constructing these path networks, but the associated learning problem is challenging: Relative to road network pathways, pedestrian network pathways are narrower, more frequently disconnected, often visually and materially variable in smaller areas, and their boundaries are broken up by driveway incursions, alleyways, marked or unmarked crossings through roadways. Existing algorithms to extract pedestrian pathway network graphs are inconsistently evaluated and tend to ignore routability, making it difficult to assess utility for mobility applications: Even if all path segments are available, discontinuities could dramatically and arbitrarily shift the overall path taken by a pedestrian. In this paper, we describe a first standard benchmark for the pedestrian pathway graph extraction problem, comprising the largest available dataset equipped with manually vetted ground truth annotations (covering $3,000 km^2$ land area in regions from 8 cities), and a family of evaluation metrics centering routability and downstream utility. By partitioning the data into polygons at the scale of individual intersections, we compute local routability as an efficient proxy for global routability. We consider multiple measures of polygon-level routability and compare predicted measures with ground truth to construct evaluation metrics. Using these metrics, we show that this benchmark can surface strengths and weaknesses of existing methods that are hidden by simple edge-counting metrics over single-region datasets used in prior work, representing a challenging, high-impact problem in computer vision and machine learning.