 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiOSPointMapper: RealTime Pedestrian and Accessibility Mapping with Mobile AI
Dec 26, 2025Accurate, up-to-date sidewalk data is essential for building accessible and inclusive pedestrian infrastructure, yet current approaches to data collection are often costly, fragmented, and difficult to scale. We introduce iOSPointMapper, a mobile application that enables real-time, privacy-conscious sidewalk mapping on the ground, using recent-generation iPhones and iPads. The system leverages on-device semantic segmentation, LiDAR-based depth estimation, and fused GPS/IMU data to detect and localize sidewalk-relevant features such as traffic signs, traffic lights and poles. To ensure transparency and improve data quality, iOSPointMapper incorporates a user-guided annotation interface for validating system outputs before submission. Collected data is anonymized and transmitted to the Transportation Data Exchange Initiative (TDEI), where it integrates seamlessly with broader multimodal transportation datasets. Detailed evaluations of the system's feature detection and spatial mapping performance reveal the application's potential for enhanced pedestrian mapping. Together, these capabilities offer a scalable and user-centered approach to closing critical data gaps in pedestrian
Can Large Language Models Integrate Spatial Data? Empirical Insights into Reasoning Strengths and Computational Weaknesses
Aug 07, 2025



We explore the application of large language models (LLMs) to empower domain experts in integrating large, heterogeneous, and noisy urban spatial datasets. Traditional rule-based integration methods are unable to cover all edge cases, requiring manual verification and repair. Machine learning approaches require collecting and labeling of large numbers of task-specific samples. In this study, we investigate the potential of LLMs for spatial data integration. Our analysis first considers how LLMs reason about environmental spatial relationships mediated by human experience, such as between roads and sidewalks. We show that while LLMs exhibit spatial reasoning capabilities, they struggle to connect the macro-scale environment with the relevant computational geometry tasks, often producing logically incoherent responses. But when provided relevant features, thereby reducing dependence on spatial reasoning, LLMs are able to generate high-performing results. We then adapt a review-and-refine method, which proves remarkably effective in correcting erroneous initial responses while preserving accurate responses. We discuss practical implications of employing LLMs for spatial data integration in real-world contexts and outline future research directions, including post-training, multi-modal integration methods, and support for diverse data formats. Our findings position LLMs as a promising and flexible alternative to traditional rule-based heuristics, advancing the capabilities of adaptive spatial data integration.
Towards Zero-Shot Annotation of the Built Environment with Vision-Language Models (Vision Paper)
Aug 01, 2024Equitable urban transportation applications require high-fidelity digital representations of the built environment: not just streets and sidewalks, but bike lanes, marked and unmarked crossings, curb ramps and cuts, obstructions, traffic signals, signage, street markings, potholes, and more. Direct inspections and manual annotations are prohibitively expensive at scale. Conventional machine learning methods require substantial annotated training data for adequate performance. In this paper, we consider vision language models as a mechanism for annotating diverse urban features from satellite images, reducing the dependence on human annotation to produce large training sets. While these models have achieved impressive results in describing common objects in images captured from a human perspective, their training sets are less likely to include strong signals for esoteric features in the built environment, and their performance in these settings is therefore unclear. We demonstrate proof-of-concept combining a state-of-the-art vision language model and variants of a prompting strategy that asks the model to consider segmented elements independently of the original image. Experiments on two urban features -- stop lines and raised tables -- show that while direct zero-shot prompting correctly annotates nearly zero images, the pre-segmentation strategies can annotate images with near 40% intersection-over-union accuracy. We describe how these results inform a new research agenda in automatic annotation of the built environment to improve equity, accessibility, and safety at broad scale and in diverse environments.
PathwayBench: Assessing Routability of Pedestrian Pathway Networks Inferred from Multi-City Imagery
Jul 23, 2024



Applications to support pedestrian mobility in urban areas require a complete, and routable graph representation of the built environment. Globally available information, including aerial imagery provides a scalable source for constructing these path networks, but the associated learning problem is challenging: Relative to road network pathways, pedestrian network pathways are narrower, more frequently disconnected, often visually and materially variable in smaller areas, and their boundaries are broken up by driveway incursions, alleyways, marked or unmarked crossings through roadways. Existing algorithms to extract pedestrian pathway network graphs are inconsistently evaluated and tend to ignore routability, making it difficult to assess utility for mobility applications: Even if all path segments are available, discontinuities could dramatically and arbitrarily shift the overall path taken by a pedestrian. In this paper, we describe a first standard benchmark for the pedestrian pathway graph extraction problem, comprising the largest available dataset equipped with manually vetted ground truth annotations (covering $3,000 km^2$ land area in regions from 8 cities), and a family of evaluation metrics centering routability and downstream utility. By partitioning the data into polygons at the scale of individual intersections, we compute local routability as an efficient proxy for global routability. We consider multiple measures of polygon-level routability and compare predicted measures with ground truth to construct evaluation metrics. Using these metrics, we show that this benchmark can surface strengths and weaknesses of existing methods that are hidden by simple edge-counting metrics over single-region datasets used in prior work, representing a challenging, high-impact problem in computer vision and machine learning.
OASIS: Automated Assessment of Urban Pedestrian Paths at Scale
Mar 04, 2023



The inspection of the Public Right of Way (PROW) for accessibility barriers is necessary for monitoring and maintaining the built environment for communities' walkability, rollability, safety, active transportation, and sustainability. However, an inspection of the PROW, by surveyors or crowds, is laborious, inconsistent, costly, and unscalable. The core of smart city developments involves the application of information technologies toward municipal assets assessment and management. Sidewalks, in comparison to automobile roads, have not been regularly integrated into information systems to optimize or inform civic services. We develop an Open Automated Sidewalks Inspection System (OASIS), a free and open-source automated mapping system, to extract sidewalk network data using mobile physical devices. OASIS leverages advances in neural networks, image sensing, location-based methods, and compact hardware to perform sidewalk segmentation and mapping along with the identification of barriers to generate a GIS pedestrian transportation layer that is available for routing as well as analytic and operational reports. We describe a prototype system trained and tested with imagery collected in real-world settings, alongside human surveyors who are part of the local transit pathway review team. Pilots show promising precision and recall for path mapping (0.94, 0.98 respectively). Moreover, surveyor teams' functional efficiency increased in the field. By design, OASIS takes adoption aspects into consideration to ensure the system could be easily integrated with governmental pathway review teams' workflows, and that the outcome data would be interoperable with public data commons.
APE: An Open and Shared Annotated Dataset for Learning Urban Pedestrian Path Networks
Mar 04, 2023Inferring the full transportation network, including sidewalks and cycleways, is crucial for many automated systems, including autonomous driving, multi-modal navigation, trip planning, mobility simulations, and freight management. Many transportation decisions can be informed based on an accurate pedestrian network, its interactions, and connectivity with the road networks of other modes of travel. A connected pedestrian path network is vital to transportation activities, as sidewalks and crossings connect pedestrians to other modes of transportation. However, information about these paths' location and connectivity is often missing or inaccurate in city planning systems and wayfinding applications, causing severe information gaps and errors for planners and pedestrians. This work begins to address this problem at scale by introducing a novel dataset of aerial satellite imagery, street map imagery, and rasterized annotations of sidewalks, crossings, and corner bulbs in urban cities. The dataset spans $2,700 km^2$ land area, covering select regions from $6$ different cities. It can be used for various learning tasks related to segmenting and understanding pedestrian environments. We also present an end-to-end process for inferring a connected pedestrian path network map using street network information and our proposed dataset. The process features the use of a multi-input segmentation network trained on our dataset to predict important classes in the pedestrian environment and then generate a connected pedestrian path network. Our results demonstrate that the dataset is sufficiently large to train common segmentation models yielding accurate, robust pedestrian path networks.
Rethinking Semantic Segmentation Evaluation for Explainability and Model Selection
Jan 21, 2021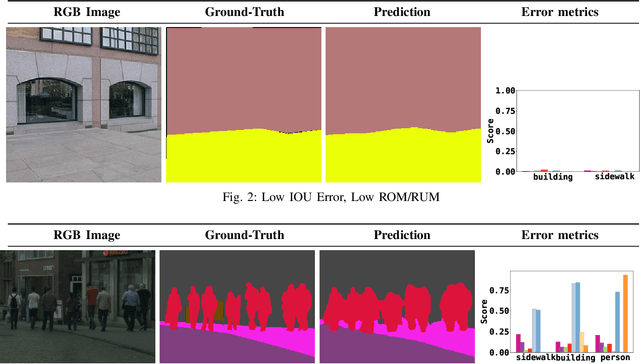
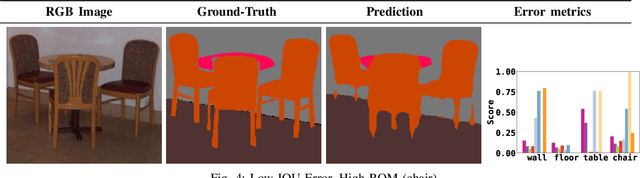


Semantic segmentation aims to robustly predict coherent class labels for entire regions of an image. It is a scene understanding task that powers real-world applications (e.g., autonomous navigation). One important application, the use of imagery for automated semantic understanding of pedestrian environments, provides remote mapping of accessibility features in street environments. This application (and others like it) require detailed geometric information of geographical objects. Semantic segmentation is a prerequisite for this task since it maps contiguous regions of the same class as single entities. Importantly, semantic segmentation uses like ours are not pixel-wise outcomes; however, most of their quantitative evaluation metrics (e.g., mean Intersection Over Union) are based on pixel-wise similarities to a ground-truth, which fails to emphasize over- and under-segmentation properties of a segmentation model. Here, we introduce a new metric to assess region-based over- and under-segmentation. We analyze and compare it to other metrics, demonstrating that the use of our metric lends greater explainability to semantic segmentation model performance in real-world applications.
ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation
Jul 25, 2018



We introduce a fast and efficient convolutional neural network, ESPNet, for semantic segmentation of high resolution images under resource constraints. ESPNet is based on a new convolutional module, efficient spatial pyramid (ESP), which is efficient in terms of computation, memory, and power. ESPNet is 22 times faster (on a standard GPU) and 180 times smaller than the state-of-the-art semantic segmentation network PSPNet, while its category-wise accuracy is only 8% less. We evaluated ESPNet on a variety of semantic segmentation datasets including Cityscapes, PASCAL VOC, and a breast biopsy whole slide image dataset. Under the same constraints on memory and computation, ESPNet outperforms all the current efficient CNN networks such as MobileNet, ShuffleNet, and ENet on both standard metrics and our newly introduced performance metrics that measure efficiency on edge devices. Our network can process high resolution images at a rate of 112 and 9 frames per second on a standard GPU and edge device, respectively.