 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Semantic Segmentation Evaluation for Explainability and Model Selection
Paper and Code
Jan 21, 2021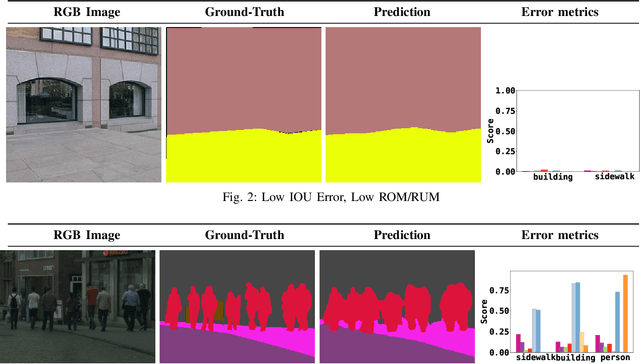
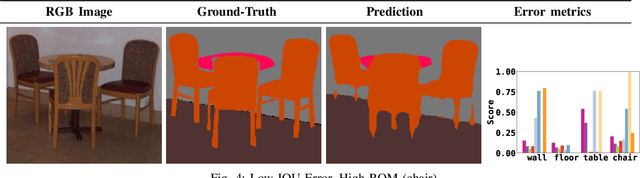


Semantic segmentation aims to robustly predict coherent class labels for entire regions of an image. It is a scene understanding task that powers real-world applications (e.g., autonomous navigation). One important application, the use of imagery for automated semantic understanding of pedestrian environments, provides remote mapping of accessibility features in street environments. This application (and others like it) require detailed geometric information of geographical objects. Semantic segmentation is a prerequisite for this task since it maps contiguous regions of the same class as single entities. Importantly, semantic segmentation uses like ours are not pixel-wise outcomes; however, most of their quantitative evaluation metrics (e.g., mean Intersection Over Union) are based on pixel-wise similarities to a ground-truth, which fails to emphasize over- and under-segmentation properties of a segmentation model. Here, we introduce a new metric to assess region-based over- and under-segmentation. We analyze and compare it to other metrics, demonstrating that the use of our metric lends greater explainability to semantic segmentation model performance in real-world applications.