 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
iOSPointMapper: RealTime Pedestrian and Accessibility Mapping with Mobile AI
Dec 26, 2025Accurate, up-to-date sidewalk data is essential for building accessible and inclusive pedestrian infrastructure, yet current approaches to data collection are often costly, fragmented, and difficult to scale. We introduce iOSPointMapper, a mobile application that enables real-time, privacy-conscious sidewalk mapping on the ground, using recent-generation iPhones and iPads. The system leverages on-device semantic segmentation, LiDAR-based depth estimation, and fused GPS/IMU data to detect and localize sidewalk-relevant features such as traffic signs, traffic lights and poles. To ensure transparency and improve data quality, iOSPointMapper incorporates a user-guided annotation interface for validating system outputs before submission. Collected data is anonymized and transmitted to the Transportation Data Exchange Initiative (TDEI), where it integrates seamlessly with broader multimodal transportation datasets. Detailed evaluations of the system's feature detection and spatial mapping performance reveal the application's potential for enhanced pedestrian mapping. Together, these capabilities offer a scalable and user-centered approach to closing critical data gaps in pedestrian
Efficient Speculative Decoding for Llama at Scale: Challenges and Solutions
Aug 11, 2025Speculative decoding is a standard method for accelerating the inference speed of large language models. However, scaling it for production environments poses several engineering challenges, including efficiently implementing different operations (e.g., tree attention and multi-round speculative decoding) on GPU. In this paper, we detail the training and inference optimization techniques that we have implemented to enable EAGLE-based speculative decoding at a production scale for Llama models. With these changes, we achieve a new state-of-the-art inference latency for Llama models. For example, Llama4 Maverick decodes at a speed of about 4 ms per token (with a batch size of one) on 8 NVIDIA H100 GPUs, which is 10% faster than the previously best known method. Furthermore, for EAGLE-based speculative decoding, our optimizations enable us to achieve a speed-up for large batch sizes between 1.4x and 2.0x at production scale.
TiC-LM: A Web-Scale Benchmark for Time-Continual LLM Pretraining
Apr 02, 2025Large Language Models (LLMs) trained on historical web data inevitably become outdated. We investigate evaluation strategies and update methods for LLMs as new data becomes available. We introduce a web-scale dataset for time-continual pretraining of LLMs derived from 114 dumps of Common Crawl (CC) - orders of magnitude larger than previous continual language modeling benchmarks. We also design time-stratified evaluations across both general CC data and specific domains (Wikipedia, StackExchange, and code documentation) to assess how well various continual learning methods adapt to new data while retaining past knowledge. Our findings demonstrate that, on general CC data, autoregressive meta-schedules combined with a fixed-ratio replay of older data can achieve comparable held-out loss to re-training from scratch, while requiring significantly less computation (2.6x). However, the optimal balance between incorporating new data and replaying old data differs as replay is crucial to avoid forgetting on generic web data but less so on specific domains.
From Dense to Dynamic: Token-Difficulty Driven MoEfication of Pre-Trained LLMs
Feb 17, 2025Training large language models (LLMs) for different inference constraints is computationally expensive, limiting control over efficiency-accuracy trade-offs. Moreover, once trained, these models typically process tokens uniformly, regardless of their complexity, leading to static and inflexible behavior. In this paper, we introduce a post-training optimization framework, DynaMoE, that adapts a pre-trained dense LLM to a token-difficulty-driven Mixture-of-Experts model with minimal fine-tuning cost. This adaptation makes the model dynamic, with sensitivity control to customize the balance between efficiency and accuracy. DynaMoE features a token-difficulty-aware router that predicts the difficulty of tokens and directs them to the appropriate sub-networks or experts, enabling larger experts to handle more complex tokens and smaller experts to process simpler ones. Our experiments demonstrate that DynaMoE can generate a range of adaptive model variants of the existing trained LLM with a single fine-tuning step, utilizing only $10B$ tokens, a minimal cost compared to the base model's training. Each variant offers distinct trade-offs between accuracy and performance. Compared to the baseline post-training optimization framework, Flextron, our method achieves similar aggregated accuracy across downstream tasks, despite using only $\frac{1}{9}\text{th}$ of their fine-tuning cost.
Efficient Vision-Language Models by Summarizing Visual Tokens into Compact Registers
Oct 17, 2024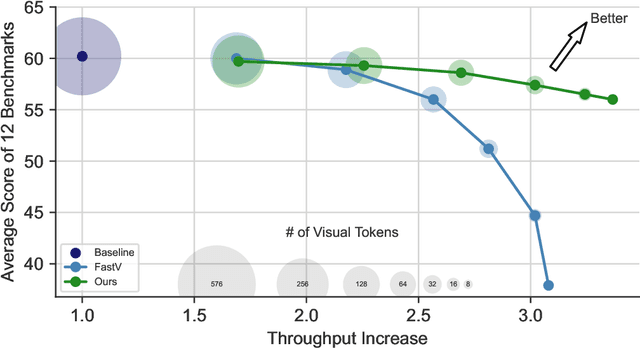
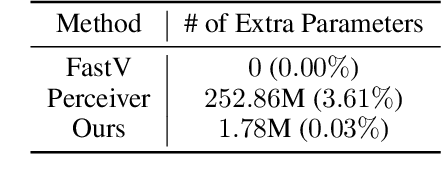
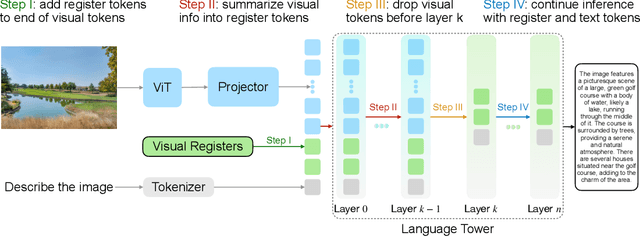
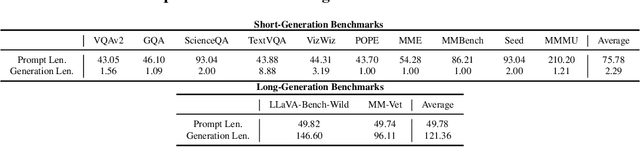
Recent advancements in vision-language models (VLMs) have expanded their potential for real-world applications, enabling these models to perform complex reasoning on images. In the widely used fully autoregressive transformer-based models like LLaVA, projected visual tokens are prepended to textual tokens. Oftentimes, visual tokens are significantly more than prompt tokens, resulting in increased computational overhead during both training and inference. In this paper, we propose Visual Compact Token Registers (Victor), a method that reduces the number of visual tokens by summarizing them into a smaller set of register tokens. Victor adds a few learnable register tokens after the visual tokens and summarizes the visual information into these registers using the first few layers in the language tower of VLMs. After these few layers, all visual tokens are discarded, significantly improving computational efficiency for both training and inference. Notably, our method is easy to implement and requires a small number of new trainable parameters with minimal impact on model performance. In our experiment, with merely 8 visual registers--about 1% of the original tokens--Victor shows less than a 4% accuracy drop while reducing the total training time by 43% and boosting the inference throughput by 3.3X.
CtrlSynth: Controllable Image Text Synthesis for Data-Efficient Multimodal Learning
Oct 15, 2024Pretraining robust vision or multimodal foundation models (e.g., CLIP) relies on large-scale datasets that may be noisy, potentially misaligned, and have long-tail distributions. Previous works have shown promising results in augmenting datasets by generating synthetic samples. However, they only support domain-specific ad hoc use cases (e.g., either image or text only, but not both), and are limited in data diversity due to a lack of fine-grained control over the synthesis process. In this paper, we design a \emph{controllable} image-text synthesis pipeline, CtrlSynth, for data-efficient and robust multimodal learning. The key idea is to decompose the visual semantics of an image into basic elements, apply user-specified control policies (e.g., remove, add, or replace operations), and recompose them to synthesize images or texts. The decompose and recompose feature in CtrlSynth allows users to control data synthesis in a fine-grained manner by defining customized control policies to manipulate the basic elements. CtrlSynth leverages the capabilities of pretrained foundation models such as large language models or diffusion models to reason and recompose basic elements such that synthetic samples are natural and composed in diverse ways. CtrlSynth is a closed-loop, training-free, and modular framework, making it easy to support different pretrained models. With extensive experiments on 31 datasets spanning different vision and vision-language tasks, we show that CtrlSynth substantially improves zero-shot classification, image-text retrieval, and compositional reasoning performance of CLIP models.
SeedLM: Compressing LLM Weights into Seeds of Pseudo-Random Generators
Oct 14, 2024



Large Language Models (LLMs) have transformed natural language processing, but face significant challenges in widespread deployment due to their high runtime cost. In this paper, we introduce SeedLM, a novel post-training compression method that uses seeds of pseudo-random generators to encode and compress model weights. Specifically, for each block of weights, we find a seed that is fed into a Linear Feedback Shift Register (LFSR) during inference to efficiently generate a random matrix. This matrix is then linearly combined with compressed coefficients to reconstruct the weight block. SeedLM reduces memory access and leverages idle compute cycles during inference, effectively speeding up memory-bound tasks by trading compute for fewer memory accesses. Unlike state-of-the-art compression methods that rely on calibration data, our approach is data-free and generalizes well across diverse tasks. Our experiments with Llama 3 70B, which is particularly challenging to compress, show that SeedLM achieves significantly better zero-shot accuracy retention at 4- and 3-bit than state-of-the-art techniques, while maintaining performance comparable to FP16 baselines. Additionally, FPGA-based tests demonstrate that 4-bit SeedLM, as model size increases to 70B, approaches a 4x speed-up over an FP16 Llama 2/3 baseline.
KV Prediction for Improved Time to First Token
Oct 10, 2024



Inference with transformer-based language models begins with a prompt processing step. In this step, the model generates the first output token and stores the KV cache needed for future generation steps. This prompt processing step can be computationally expensive, taking 10s of seconds or more for billion-parameter models on edge devices when prompt lengths or batch sizes rise. This degrades user experience by introducing significant latency into the model's outputs. To reduce the time spent producing the first output (known as the ``time to first token'', or TTFT) of a pretrained model, we introduce a novel method called KV Prediction. In our method, a small auxiliary model is used to process the prompt and produce an approximation of the KV cache used by a base model. This approximated KV cache is then used with the base model for autoregressive generation without the need to query the auxiliary model again. We demonstrate that our method produces a pareto-optimal efficiency-accuracy trade-off when compared to baselines. On TriviaQA, we demonstrate relative accuracy improvements in the range of $15\%-50\%$ across a range of TTFT FLOPs budgets. We also demonstrate accuracy improvements of up to $30\%$ on HumanEval python code completion at fixed TTFT FLOPs budgets. Additionally, we benchmark models on an Apple M2 Pro CPU and demonstrate that our improvement in FLOPs translates to a TTFT speedup on hardware. We release our code at https://github.com/apple/corenet/tree/main/projects/kv-prediction .
PathwayBench: Assessing Routability of Pedestrian Pathway Networks Inferred from Multi-City Imagery
Jul 23, 2024



Applications to support pedestrian mobility in urban areas require a complete, and routable graph representation of the built environment. Globally available information, including aerial imagery provides a scalable source for constructing these path networks, but the associated learning problem is challenging: Relative to road network pathways, pedestrian network pathways are narrower, more frequently disconnected, often visually and materially variable in smaller areas, and their boundaries are broken up by driveway incursions, alleyways, marked or unmarked crossings through roadways. Existing algorithms to extract pedestrian pathway network graphs are inconsistently evaluated and tend to ignore routability, making it difficult to assess utility for mobility applications: Even if all path segments are available, discontinuities could dramatically and arbitrarily shift the overall path taken by a pedestrian. In this paper, we describe a first standard benchmark for the pedestrian pathway graph extraction problem, comprising the largest available dataset equipped with manually vetted ground truth annotations (covering $3,000 km^2$ land area in regions from 8 cities), and a family of evaluation metrics centering routability and downstream utility. By partitioning the data into polygons at the scale of individual intersections, we compute local routability as an efficient proxy for global routability. We consider multiple measures of polygon-level routability and compare predicted measures with ground truth to construct evaluation metrics. Using these metrics, we show that this benchmark can surface strengths and weaknesses of existing methods that are hidden by simple edge-counting metrics over single-region datasets used in prior work, representing a challenging, high-impact problem in computer vision and machine learning.