 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Vision-Language Models by Summarizing Visual Tokens into Compact Registers
Oct 17, 2024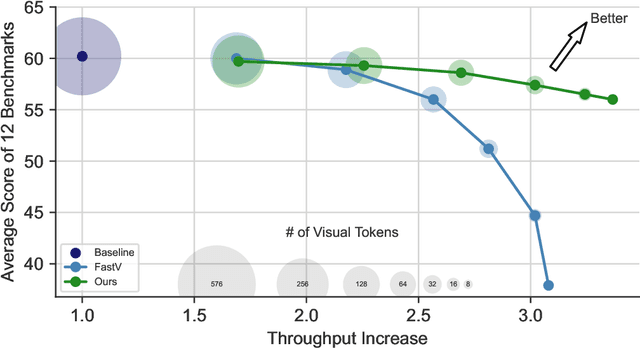
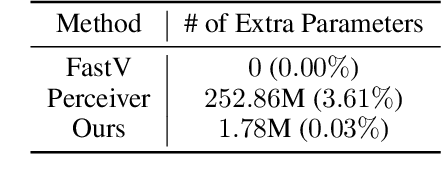
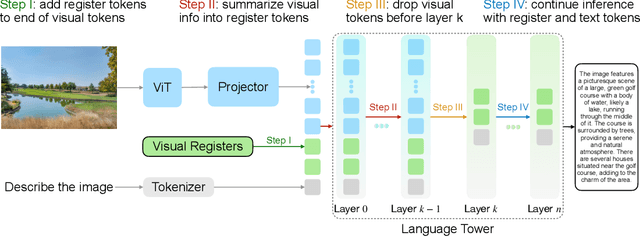
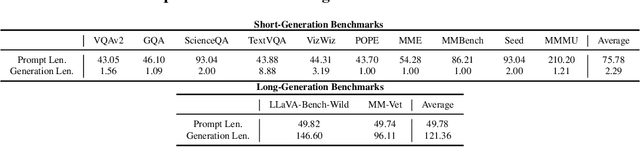
Recent advancements in vision-language models (VLMs) have expanded their potential for real-world applications, enabling these models to perform complex reasoning on images. In the widely used fully autoregressive transformer-based models like LLaVA, projected visual tokens are prepended to textual tokens. Oftentimes, visual tokens are significantly more than prompt tokens, resulting in increased computational overhead during both training and inference. In this paper, we propose Visual Compact Token Registers (Victor), a method that reduces the number of visual tokens by summarizing them into a smaller set of register tokens. Victor adds a few learnable register tokens after the visual tokens and summarizes the visual information into these registers using the first few layers in the language tower of VLMs. After these few layers, all visual tokens are discarded, significantly improving computational efficiency for both training and inference. Notably, our method is easy to implement and requires a small number of new trainable parameters with minimal impact on model performance. In our experiment, with merely 8 visual registers--about 1% of the original tokens--Victor shows less than a 4% accuracy drop while reducing the total training time by 43% and boosting the inference throughput by 3.3X.
CtrlSynth: Controllable Image Text Synthesis for Data-Efficient Multimodal Learning
Oct 15, 2024Pretraining robust vision or multimodal foundation models (e.g., CLIP) relies on large-scale datasets that may be noisy, potentially misaligned, and have long-tail distributions. Previous works have shown promising results in augmenting datasets by generating synthetic samples. However, they only support domain-specific ad hoc use cases (e.g., either image or text only, but not both), and are limited in data diversity due to a lack of fine-grained control over the synthesis process. In this paper, we design a \emph{controllable} image-text synthesis pipeline, CtrlSynth, for data-efficient and robust multimodal learning. The key idea is to decompose the visual semantics of an image into basic elements, apply user-specified control policies (e.g., remove, add, or replace operations), and recompose them to synthesize images or texts. The decompose and recompose feature in CtrlSynth allows users to control data synthesis in a fine-grained manner by defining customized control policies to manipulate the basic elements. CtrlSynth leverages the capabilities of pretrained foundation models such as large language models or diffusion models to reason and recompose basic elements such that synthetic samples are natural and composed in diverse ways. CtrlSynth is a closed-loop, training-free, and modular framework, making it easy to support different pretrained models. With extensive experiments on 31 datasets spanning different vision and vision-language tasks, we show that CtrlSynth substantially improves zero-shot classification, image-text retrieval, and compositional reasoning performance of CLIP models.
KV Prediction for Improved Time to First Token
Oct 10, 2024



Inference with transformer-based language models begins with a prompt processing step. In this step, the model generates the first output token and stores the KV cache needed for future generation steps. This prompt processing step can be computationally expensive, taking 10s of seconds or more for billion-parameter models on edge devices when prompt lengths or batch sizes rise. This degrades user experience by introducing significant latency into the model's outputs. To reduce the time spent producing the first output (known as the ``time to first token'', or TTFT) of a pretrained model, we introduce a novel method called KV Prediction. In our method, a small auxiliary model is used to process the prompt and produce an approximation of the KV cache used by a base model. This approximated KV cache is then used with the base model for autoregressive generation without the need to query the auxiliary model again. We demonstrate that our method produces a pareto-optimal efficiency-accuracy trade-off when compared to baselines. On TriviaQA, we demonstrate relative accuracy improvements in the range of $15\%-50\%$ across a range of TTFT FLOPs budgets. We also demonstrate accuracy improvements of up to $30\%$ on HumanEval python code completion at fixed TTFT FLOPs budgets. Additionally, we benchmark models on an Apple M2 Pro CPU and demonstrate that our improvement in FLOPs translates to a TTFT speedup on hardware. We release our code at https://github.com/apple/corenet/tree/main/projects/kv-prediction .
OpenELM: An Efficient Language Model Family with Open Training and Inference Framework
May 02, 2024The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and enabling investigations into data and model biases, as well as potential risks. To this end, we release OpenELM, a state-of-the-art open language model. OpenELM uses a layer-wise scaling strategy to efficiently allocate parameters within each layer of the transformer model, leading to enhanced accuracy. For example, with a parameter budget of approximately one billion parameters, OpenELM exhibits a 2.36% improvement in accuracy compared to OLMo while requiring $2\times$ fewer pre-training tokens. Diverging from prior practices that only provide model weights and inference code, and pre-train on private datasets, our release includes the complete framework for training and evaluation of the language model on publicly available datasets, including training logs, multiple checkpoints, and pre-training configurations. We also release code to convert models to MLX library for inference and fine-tuning on Apple devices. This comprehensive release aims to empower and strengthen the open research community, paving the way for future open research endeavors. Our source code along with pre-trained model weights and training recipes is available at \url{https://github.com/apple/corenet}. Additionally, \model models can be found on HuggingFace at: \url{https://huggingface.co/apple/OpenELM}.
APT: Adaptive Pruning and Tuning Pretrained Language Models for Efficient Training and Inference
Jan 22, 2024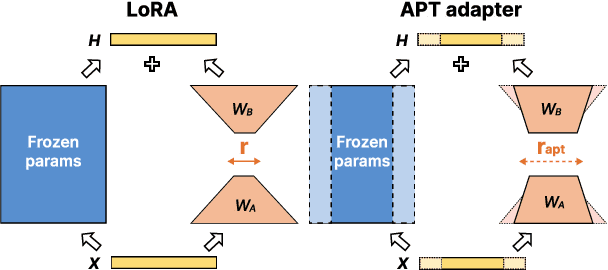
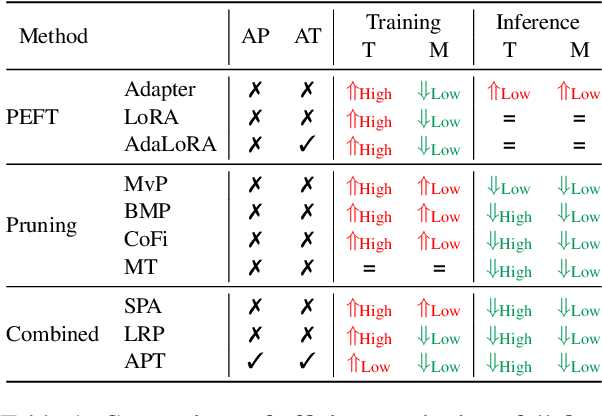
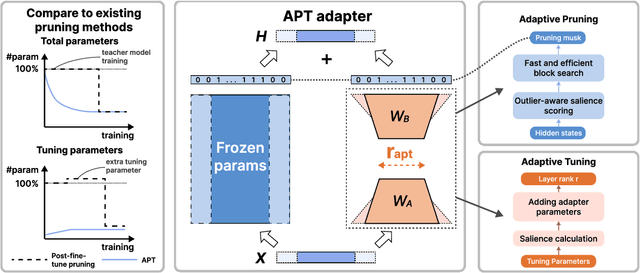

Fine-tuning and inference with large Language Models (LM) are generally known to be expensive. Parameter-efficient fine-tuning over pretrained LMs reduces training memory by updating a small number of LM parameters but does not improve inference efficiency. Structured pruning improves LM inference efficiency by removing consistent parameter blocks, yet often increases training memory and time. To improve both training and inference efficiency, we introduce APT that adaptively prunes and tunes parameters for the LMs. At the early stage of fine-tuning, APT dynamically adds salient tuning parameters for fast and accurate convergence while discarding unimportant parameters for efficiency. Compared to baselines, our experiments show that APT maintains up to 98% task performance when pruning RoBERTa and T5 models with 40% parameters left while keeping 86.4% LLaMA models' performance with 70% parameters remained. Furthermore, APT speeds up LMs fine-tuning by up to 8x and reduces large LMs memory training footprint by up to 70%.
BTR: Binary Token Representations for Efficient Retrieval Augmented Language Models
Oct 02, 2023



Retrieval augmentation addresses many critical problems in large language models such as hallucination, staleness, and privacy leaks. However, running retrieval-augmented language models (LMs) is slow and difficult to scale due to processing large amounts of retrieved text. We introduce binary token representations (BTR), which use 1-bit vectors to precompute every token in passages, significantly reducing computation during inference. Despite the potential loss of accuracy, our new calibration techniques and training objectives restore performance. Combined with offline and runtime compression, this only requires 127GB of disk space for encoding 3 billion tokens in Wikipedia. Our experiments show that on five knowledge-intensive NLP tasks, BTR accelerates state-of-the-art inference by up to 4x and reduces storage by over 100x while maintaining over 95% task performance.
Efficiency Pentathlon: A Standardized Arena for Efficiency Evaluation
Jul 19, 2023Rising computational demands of modern natural language processing (NLP) systems have increased the barrier to entry for cutting-edge research while posing serious environmental concerns. Yet, progress on model efficiency has been impeded by practical challenges in model evaluation and comparison. For example, hardware is challenging to control due to disparate levels of accessibility across different institutions. Moreover, improvements in metrics such as FLOPs often fail to translate to progress in real-world applications. In response, we introduce Pentathlon, a benchmark for holistic and realistic evaluation of model efficiency. Pentathlon focuses on inference, which accounts for a majority of the compute in a model's lifecycle. It offers a strictly-controlled hardware platform, and is designed to mirror real-world applications scenarios. It incorporates a suite of metrics that target different aspects of efficiency, including latency, throughput, memory overhead, and energy consumption. Pentathlon also comes with a software library that can be seamlessly integrated into any codebase and enable evaluation. As a standardized and centralized evaluation platform, Pentathlon can drastically reduce the workload to make fair and reproducible efficiency comparisons. While initially focused on natural language processing (NLP) models, Pentathlon is designed to allow flexible extension to other fields. We envision Pentathlon will stimulate algorithmic innovations in building efficient models, and foster an increased awareness of the social and environmental implications in the development of future-generation NLP models.
AdANNS: A Framework for Adaptive Semantic Search
May 30, 2023



Web-scale search systems learn an encoder to embed a given query which is then hooked into an approximate nearest neighbor search (ANNS) pipeline to retrieve similar data points. To accurately capture tail queries and data points, learned representations typically are rigid, high-dimensional vectors that are generally used as-is in the entire ANNS pipeline and can lead to computationally expensive retrieval. In this paper, we argue that instead of rigid representations, different stages of ANNS can leverage adaptive representations of varying capacities to achieve significantly better accuracy-compute trade-offs, i.e., stages of ANNS that can get away with more approximate computation should use a lower-capacity representation of the same data point. To this end, we introduce AdANNS, a novel ANNS design framework that explicitly leverages the flexibility of Matryoshka Representations. We demonstrate state-of-the-art accuracy-compute trade-offs using novel AdANNS-based key ANNS building blocks like search data structures (AdANNS-IVF) and quantization (AdANNS-OPQ). For example on ImageNet retrieval, AdANNS-IVF is up to 1.5% more accurate than the rigid representations-based IVF at the same compute budget; and matches accuracy while being up to 90x faster in wall-clock time. For Natural Questions, 32-byte AdANNS-OPQ matches the accuracy of the 64-byte OPQ baseline constructed using rigid representations -- same accuracy at half the cost! We further show that the gains from AdANNS translate to modern-day composite ANNS indices that combine search structures and quantization. Finally, we demonstrate that AdANNS can enable inference-time adaptivity for compute-aware search on ANNS indices built non-adaptively on matryoshka representations. Code is open-sourced at https://github.com/RAIVNLab/AdANNS.
PuMer: Pruning and Merging Tokens for Efficient Vision Language Models
May 27, 2023
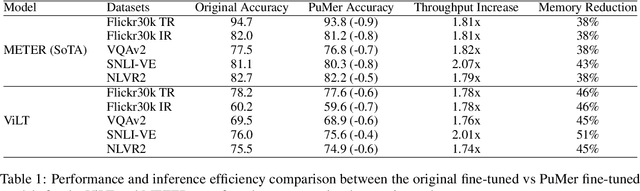
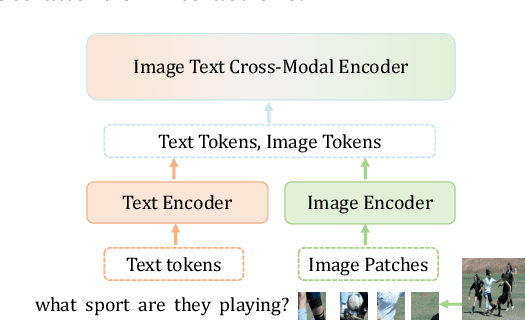
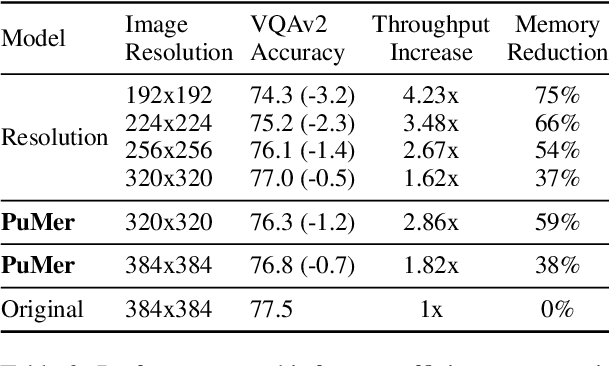
Large-scale vision language (VL) models use Transformers to perform cross-modal interactions between the input text and image. These cross-modal interactions are computationally expensive and memory-intensive due to the quadratic complexity of processing the input image and text. We present PuMer: a token reduction framework that uses text-informed Pruning and modality-aware Merging strategies to progressively reduce the tokens of input image and text, improving model inference speed and reducing memory footprint. PuMer learns to keep salient image tokens related to the input text and merges similar textual and visual tokens by adding lightweight token reducer modules at several cross-modal layers in the VL model. Training PuMer is mostly the same as finetuning the original VL model but faster. Our evaluation for two vision language models on four downstream VL tasks shows PuMer increases inference throughput by up to 2x and reduces memory footprint by over 50% while incurring less than a 1% accuracy drop.
A Survey for Efficient Open Domain Question Answering
Nov 15, 2022Open domain question answering (ODQA) is a longstanding task aimed at answering factual questions from a large knowledge corpus without any explicit evidence in natural language processing (NLP). Recent works have predominantly focused on improving the answering accuracy and achieved promising progress. However, higher accuracy often comes with more memory consumption and inference latency, which might not necessarily be efficient enough for direct deployment in the real world. Thus, a trade-off between accuracy, memory consumption and processing speed is pursued. In this paper, we provide a survey of recent advances in the efficiency of ODQA models. We walk through the ODQA models and conclude the core techniques on efficiency. Quantitative analysis on memory cost, processing speed, accuracy and overall comparison are given. We hope that this work would keep interested scholars informed of the advances and open challenges in ODQA efficiency research, and thus contribute to the further development of ODQA efficiency.