 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
SeedLM: Compressing LLM Weights into Seeds of Pseudo-Random Generators
Oct 14, 2024



Large Language Models (LLMs) have transformed natural language processing, but face significant challenges in widespread deployment due to their high runtime cost. In this paper, we introduce SeedLM, a novel post-training compression method that uses seeds of pseudo-random generators to encode and compress model weights. Specifically, for each block of weights, we find a seed that is fed into a Linear Feedback Shift Register (LFSR) during inference to efficiently generate a random matrix. This matrix is then linearly combined with compressed coefficients to reconstruct the weight block. SeedLM reduces memory access and leverages idle compute cycles during inference, effectively speeding up memory-bound tasks by trading compute for fewer memory accesses. Unlike state-of-the-art compression methods that rely on calibration data, our approach is data-free and generalizes well across diverse tasks. Our experiments with Llama 3 70B, which is particularly challenging to compress, show that SeedLM achieves significantly better zero-shot accuracy retention at 4- and 3-bit than state-of-the-art techniques, while maintaining performance comparable to FP16 baselines. Additionally, FPGA-based tests demonstrate that 4-bit SeedLM, as model size increases to 70B, approaches a 4x speed-up over an FP16 Llama 2/3 baseline.
KV Prediction for Improved Time to First Token
Oct 10, 2024



Inference with transformer-based language models begins with a prompt processing step. In this step, the model generates the first output token and stores the KV cache needed for future generation steps. This prompt processing step can be computationally expensive, taking 10s of seconds or more for billion-parameter models on edge devices when prompt lengths or batch sizes rise. This degrades user experience by introducing significant latency into the model's outputs. To reduce the time spent producing the first output (known as the ``time to first token'', or TTFT) of a pretrained model, we introduce a novel method called KV Prediction. In our method, a small auxiliary model is used to process the prompt and produce an approximation of the KV cache used by a base model. This approximated KV cache is then used with the base model for autoregressive generation without the need to query the auxiliary model again. We demonstrate that our method produces a pareto-optimal efficiency-accuracy trade-off when compared to baselines. On TriviaQA, we demonstrate relative accuracy improvements in the range of $15\%-50\%$ across a range of TTFT FLOPs budgets. We also demonstrate accuracy improvements of up to $30\%$ on HumanEval python code completion at fixed TTFT FLOPs budgets. Additionally, we benchmark models on an Apple M2 Pro CPU and demonstrate that our improvement in FLOPs translates to a TTFT speedup on hardware. We release our code at https://github.com/apple/corenet/tree/main/projects/kv-prediction .
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference
Jul 19, 2024



The inference of transformer-based large language models consists of two sequential stages: 1) a prefilling stage to compute the KV cache of prompts and generate the first token, and 2) a decoding stage to generate subsequent tokens. For long prompts, the KV cache must be computed for all tokens during the prefilling stage, which can significantly increase the time needed to generate the first token. Consequently, the prefilling stage may become a bottleneck in the generation process. An open question remains whether all prompt tokens are essential for generating the first token. To answer this, we introduce a novel method, LazyLLM, that selectively computes the KV for tokens important for the next token prediction in both the prefilling and decoding stages. Contrary to static pruning approaches that prune the prompt at once, LazyLLM allows language models to dynamically select different subsets of tokens from the context in different generation steps, even though they might be pruned in previous steps. Extensive experiments on standard datasets across various tasks demonstrate that LazyLLM is a generic method that can be seamlessly integrated with existing language models to significantly accelerate the generation without fine-tuning. For instance, in the multi-document question-answering task, LazyLLM accelerates the prefilling stage of the LLama 2 7B model by 2.34x while maintaining accuracy.
KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache Generation
May 08, 2024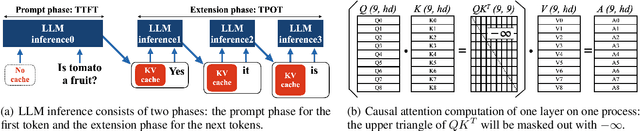

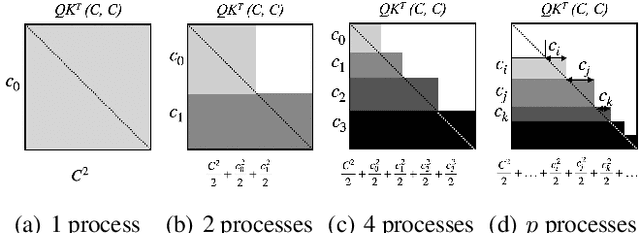
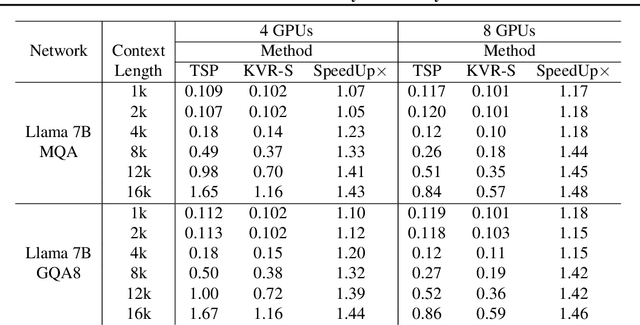
Large Language Model or LLM inference has two phases, the prompt (or prefill) phase to output the first token and the extension (or decoding) phase to the generate subsequent tokens. In this work, we propose an efficient parallelization scheme, KV-Runahead to accelerate the prompt phase. The key observation is that the extension phase generates tokens faster than the prompt phase because of key-value cache (KV-cache). Hence, KV-Runahead parallelizes the prompt phase by orchestrating multiple processes to populate the KV-cache and minimizes the time-to-first-token (TTFT). Dual-purposing the KV-cache scheme has two main benefits. Fist, since KV-cache is designed to leverage the causal attention map, we minimize computation and computation automatically. Second, since it already exists for the extension phase, KV-Runahead is easy to implement. We further propose context-level load-balancing to handle uneven KV-cache generation (due to the causal attention) and to optimize TTFT. Compared with an existing parallelization scheme such as tensor or sequential parallelization where keys and values are locally generated and exchanged via all-gather collectives, our experimental results demonstrate that KV-Runahead can offer over 1.4x and 1.6x speedups for Llama 7B and Falcon 7B respectively.
OpenELM: An Efficient Language Model Family with Open Training and Inference Framework
May 02, 2024The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and enabling investigations into data and model biases, as well as potential risks. To this end, we release OpenELM, a state-of-the-art open language model. OpenELM uses a layer-wise scaling strategy to efficiently allocate parameters within each layer of the transformer model, leading to enhanced accuracy. For example, with a parameter budget of approximately one billion parameters, OpenELM exhibits a 2.36% improvement in accuracy compared to OLMo while requiring $2\times$ fewer pre-training tokens. Diverging from prior practices that only provide model weights and inference code, and pre-train on private datasets, our release includes the complete framework for training and evaluation of the language model on publicly available datasets, including training logs, multiple checkpoints, and pre-training configurations. We also release code to convert models to MLX library for inference and fine-tuning on Apple devices. This comprehensive release aims to empower and strengthen the open research community, paving the way for future open research endeavors. Our source code along with pre-trained model weights and training recipes is available at \url{https://github.com/apple/corenet}. Additionally, \model models can be found on HuggingFace at: \url{https://huggingface.co/apple/OpenELM}.
CatLIP: CLIP-level Visual Recognition Accuracy with 2.7x Faster Pre-training on Web-scale Image-Text Data
Apr 24, 2024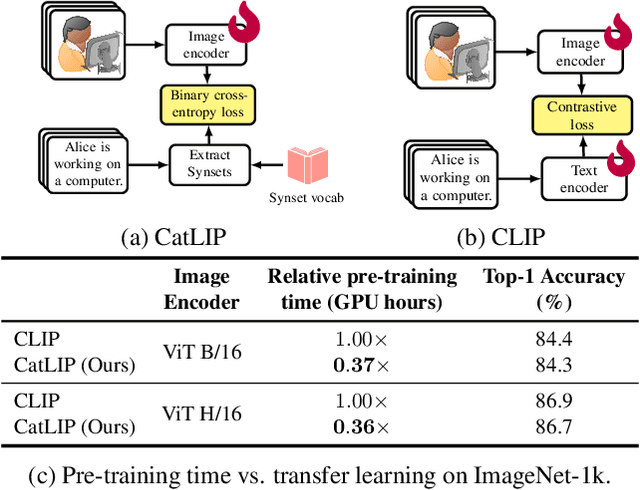

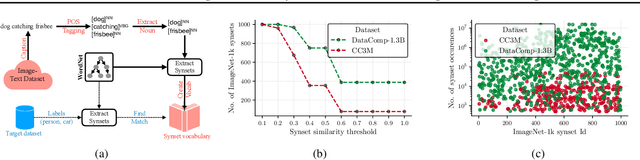
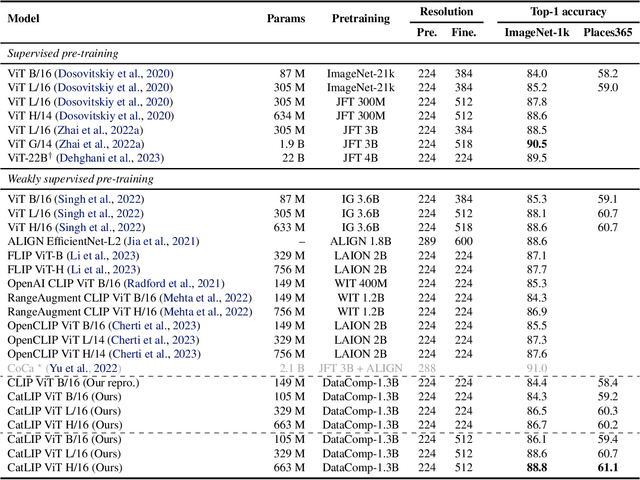
Contrastive learning has emerged as a transformative method for learning effective visual representations through the alignment of image and text embeddings. However, pairwise similarity computation in contrastive loss between image and text pairs poses computational challenges. This paper presents a novel weakly supervised pre-training of vision models on web-scale image-text data. The proposed method reframes pre-training on image-text data as a classification task. Consequently, it eliminates the need for pairwise similarity computations in contrastive loss, achieving a remarkable $2.7\times$ acceleration in training speed compared to contrastive learning on web-scale data. Through extensive experiments spanning diverse vision tasks, including detection and segmentation, we demonstrate that the proposed method maintains high representation quality. Our source code along with pre-trained model weights and training recipes is available at \url{https://github.com/apple/corenet}.
Superposition Prompting: Improving and Accelerating Retrieval-Augmented Generation
Apr 10, 2024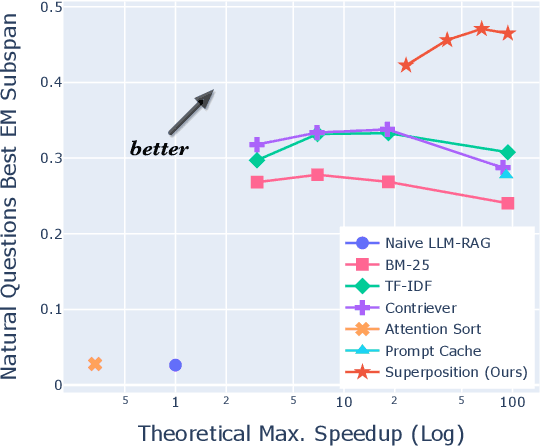
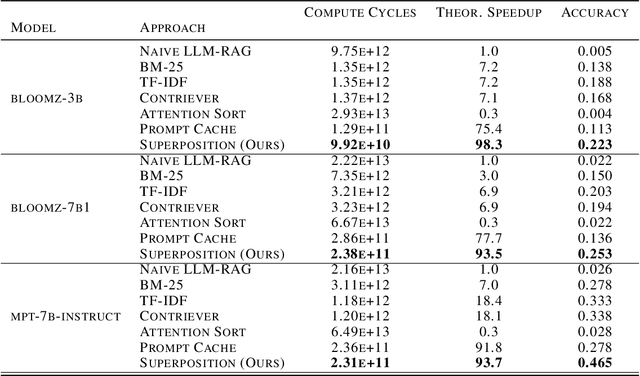
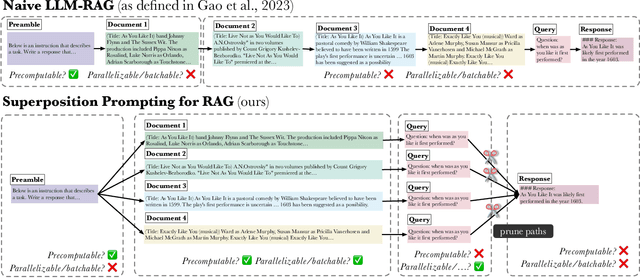
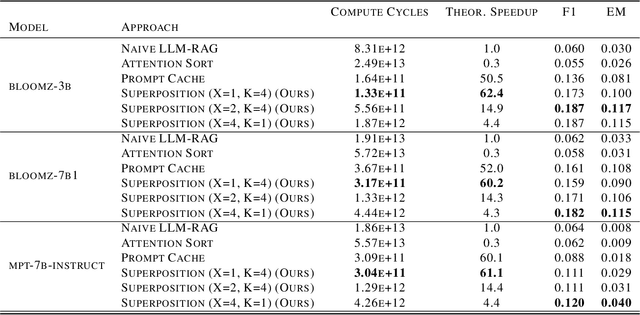
Despite the successes of large language models (LLMs), they exhibit significant drawbacks, particularly when processing long contexts. Their inference cost scales quadratically with respect to sequence length, making it expensive for deployment in some real-world text processing applications, such as retrieval-augmented generation (RAG). Additionally, LLMs also exhibit the "distraction phenomenon," where irrelevant context in the prompt degrades output quality. To address these drawbacks, we propose a novel RAG prompting methodology, superposition prompting, which can be directly applied to pre-trained transformer-based LLMs without the need for fine-tuning. At a high level, superposition prompting allows the LLM to process input documents in parallel prompt paths, discarding paths once they are deemed irrelevant. We demonstrate the capability of our method to simultaneously enhance time efficiency across a variety of question-answering benchmarks using multiple pre-trained LLMs. Furthermore, our technique significantly improves accuracy when the retrieved context is large relative the context the model was trained on. For example, our approach facilitates an 93x reduction in compute time while improving accuracy by 43\% on the NaturalQuestions-Open dataset with the MPT-7B instruction-tuned model over naive RAG.
Speculative Streaming: Fast LLM Inference without Auxiliary Models
Feb 16, 2024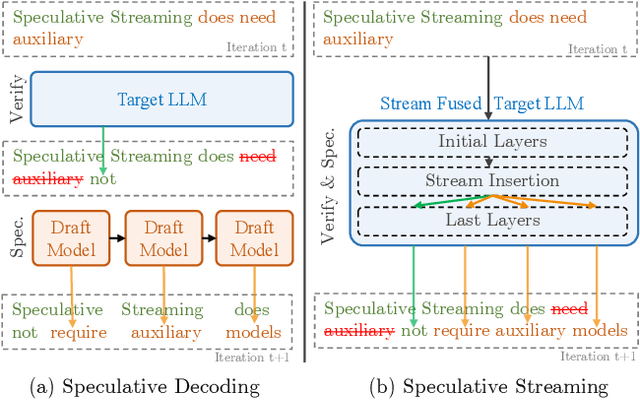
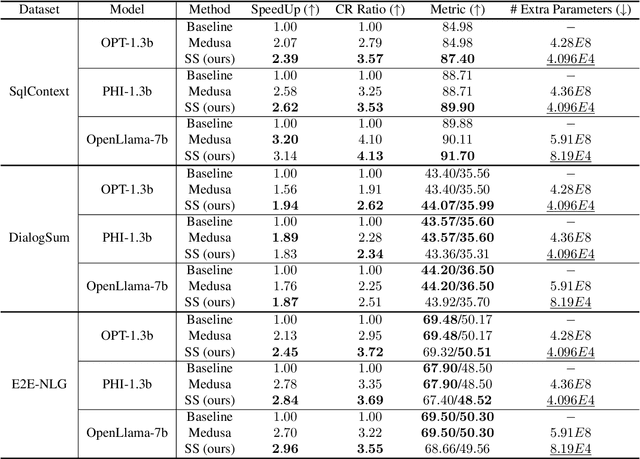
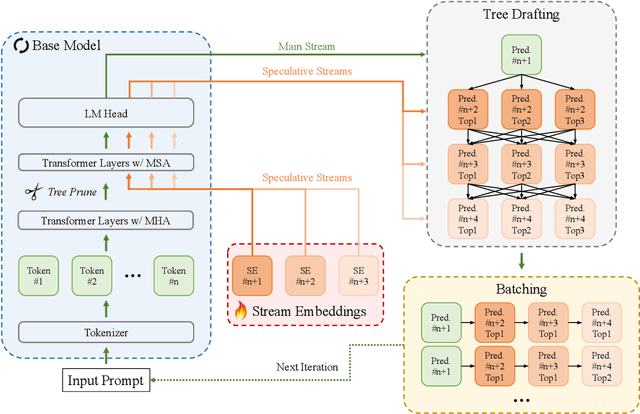
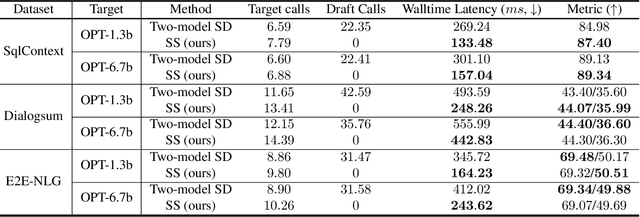
Speculative decoding is a prominent technique to speed up the inference of a large target language model based on predictions of an auxiliary draft model. While effective, in application-specific settings, it often involves fine-tuning both draft and target models to achieve high acceptance rates. As the number of downstream tasks grows, these draft models add significant complexity to inference systems. We propose Speculative Streaming, a single-model speculative decoding method that fuses drafting into the target model by changing the fine-tuning objective from next token prediction to future n-gram prediction. Speculative Streaming speeds up decoding by 1.8 - 3.1X in a diverse set of tasks, such as Summarization, Structured Queries, and Meaning Representation, without sacrificing generation quality. Additionally, Speculative Streaming is parameter-efficient. It achieves on-par/higher speed-ups than Medusa-style architectures while using ~10000X fewer extra parameters, making it well-suited for resource-constrained devices.