 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2R2: Mixture of Multi-Rate Residuals for Efficient Transformer Inference
Feb 04, 2025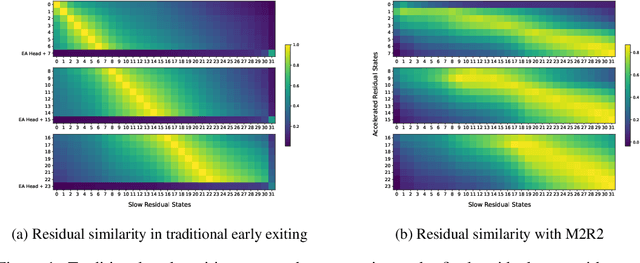
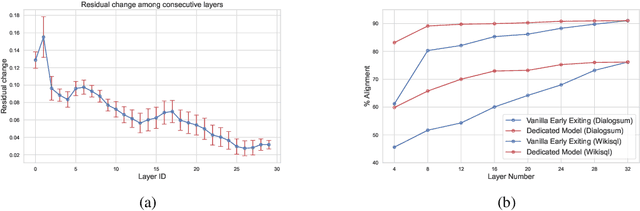
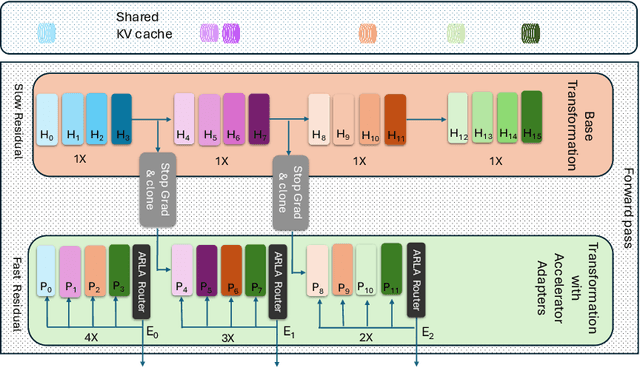
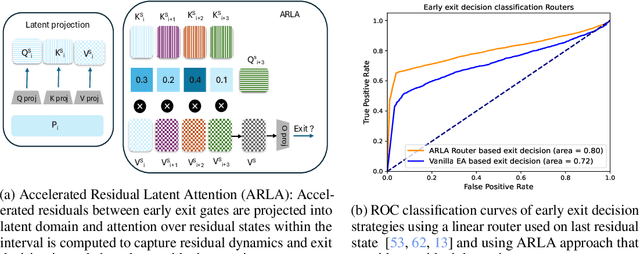
Residual transformations enhance the representational depth and expressive power of large language models (LLMs). However, applying static residual transformations across all tokens in auto-regressive generation leads to a suboptimal trade-off between inference efficiency and generation fidelity. Existing methods, including Early Exiting, Skip Decoding, and Mixture-of-Depth address this by modulating the residual transformation based on token-level complexity. Nevertheless, these approaches predominantly consider the distance traversed by tokens through the model layers, neglecting the underlying velocity of residual evolution. We introduce Mixture of Multi-rate Residuals (M2R2), a framework that dynamically modulates residual velocity to improve early alignment, enhancing inference efficiency. Evaluations on reasoning oriented tasks such as Koala, Self-Instruct, WizardLM, and MT-Bench show M2R2 surpasses state-of-the-art distance-based strategies, balancing generation quality and speedup. In self-speculative decoding setup, M2R2 achieves up to 2.8x speedups on MT-Bench, outperforming methods like 2-model speculative decoding, Medusa, LookAhead Decoding, and DEED. In Mixture-of-Experts (MoE) architectures, integrating early residual alignment with ahead-of-time expert loading into high-bandwidth memory (HBM) accelerates decoding, reduces expert-switching bottlenecks, and achieves a 2.9x speedup, making it highly effective in resource-constrained environments.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Speculative Streaming: Fast LLM Inference without Auxiliary Models
Feb 16, 2024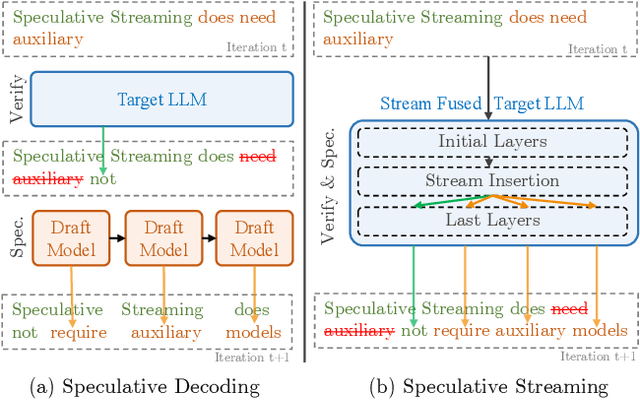
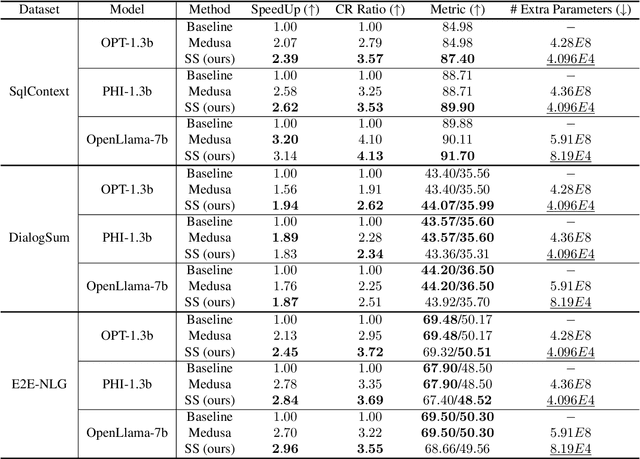
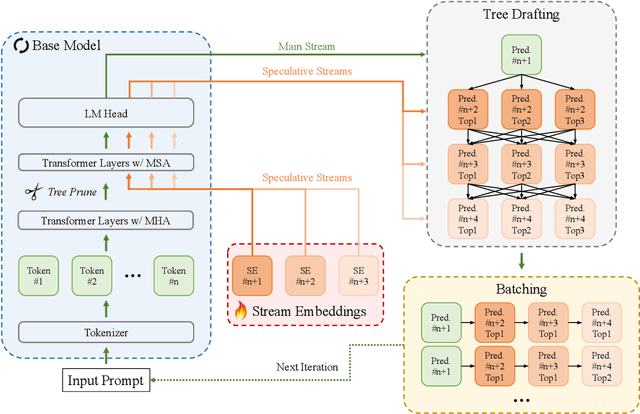
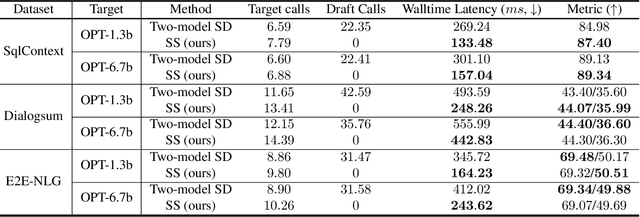
Speculative decoding is a prominent technique to speed up the inference of a large target language model based on predictions of an auxiliary draft model. While effective, in application-specific settings, it often involves fine-tuning both draft and target models to achieve high acceptance rates. As the number of downstream tasks grows, these draft models add significant complexity to inference systems. We propose Speculative Streaming, a single-model speculative decoding method that fuses drafting into the target model by changing the fine-tuning objective from next token prediction to future n-gram prediction. Speculative Streaming speeds up decoding by 1.8 - 3.1X in a diverse set of tasks, such as Summarization, Structured Queries, and Meaning Representation, without sacrificing generation quality. Additionally, Speculative Streaming is parameter-efficient. It achieves on-par/higher speed-ups than Medusa-style architectures while using ~10000X fewer extra parameters, making it well-suited for resource-constrained devices.
FastSeq: Make Sequence Generation Faster
Jun 08, 2021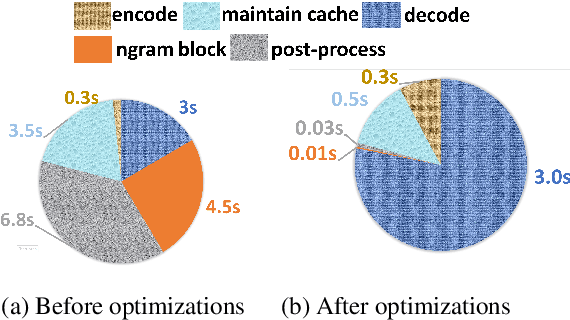
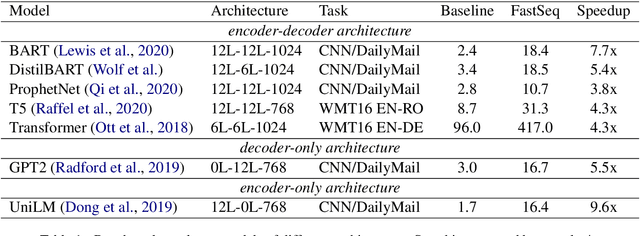
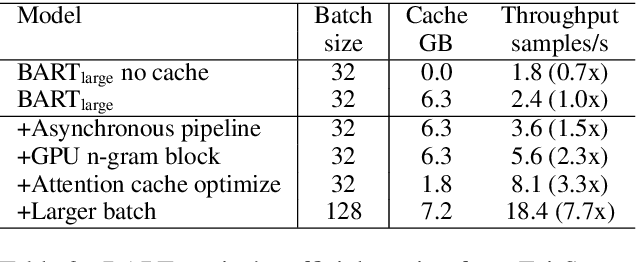
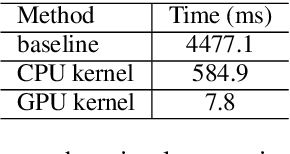
Transformer-based models have made tremendous impacts in natural language generation. However the inference speed is a bottleneck due to large model size and intensive computing involved in auto-regressive decoding process. We develop FastSeq framework to accelerate sequence generation without accuracy loss. The proposed optimization techniques include an attention cache optimization, an efficient algorithm for detecting repeated n-grams, and an asynchronous generation pipeline with parallel I/O. These optimizations are general enough to be applicable to Transformer-based models (e.g., T5, GPT2, and UniLM). Our benchmark results on a set of widely used and diverse models demonstrate 4-9x inference speed gain. Additionally, FastSeq is easy to use with a simple one-line code change. The source code is available at https://github.com/microsoft/fastseq.
EL-Attention: Memory Efficient Lossless Attention for Generation
May 11, 2021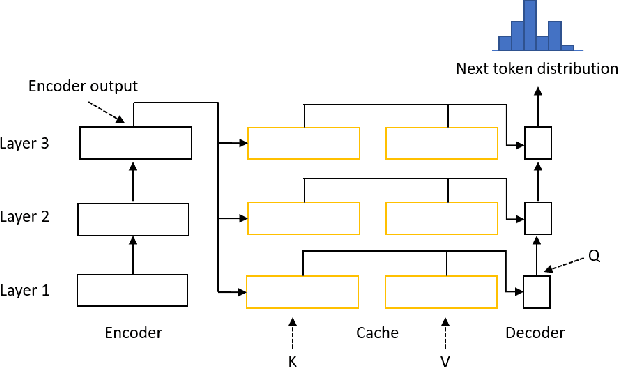
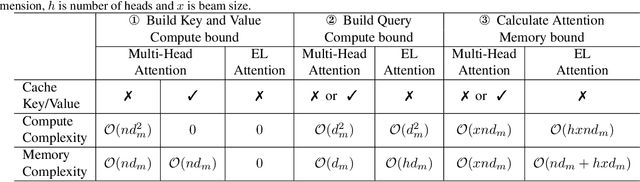
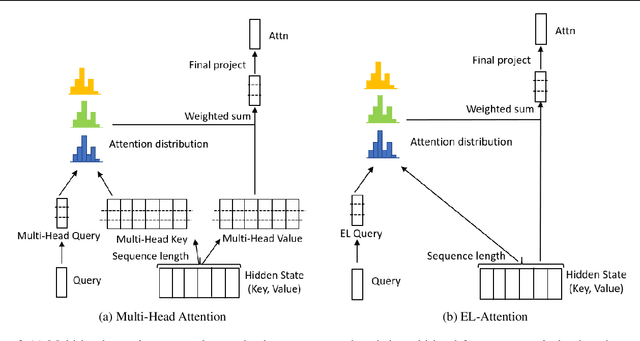
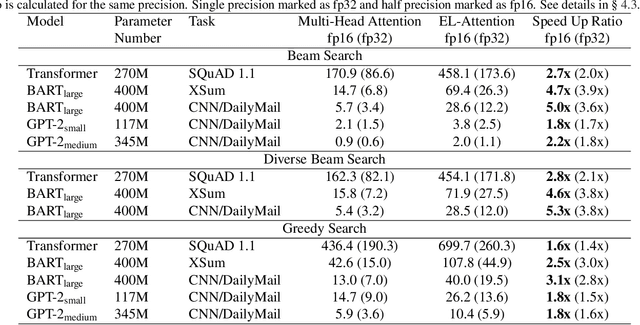
Transformer model with multi-head attention requires caching intermediate results for efficient inference in generation tasks. However, cache brings new memory-related costs and prevents leveraging larger batch size for faster speed. We propose memory-efficient lossless attention (called EL-attention) to address this issue. It avoids heavy operations for building multi-head keys and values, with no requirements of using cache. EL-attention constructs an ensemble of attention results by expanding query while keeping key and value shared. It produces the same result as multi-head attention with less GPU memory and faster inference speed. We conduct extensive experiments on Transformer, BART, and GPT-2 for summarization and question generation tasks. The results show EL-attention speeds up existing models by 1.6x to 5.3x without accuracy loss.