 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLast-Layer Fairness Fine-tuning is Simple and Effective for Neural Networks
Apr 08, 2023As machine learning has been deployed ubiquitously across applications in modern data science, algorithmic fairness has become a great concern and varieties of fairness criteria have been proposed. Among them, imposing fairness constraints during learning, i.e. in-processing fair training, has been a popular type of training method because they don't require accessing sensitive attributes during test time in contrast to post-processing methods. Although imposing fairness constraints have been studied extensively for classical machine learning models, the effect these techniques have on deep neural networks is still unclear. Recent research has shown that adding fairness constraints to the objective function leads to severe over-fitting to fairness criteria in large models, and how to solve this challenge is an important open question. To address this challenge, we leverage the wisdom and power of pre-training and fine-tuning and develop a simple but novel framework to train fair neural networks in an efficient and inexpensive way. We conduct comprehensive experiments on two popular image datasets with state-of-art architectures under different fairness notions to show that last-layer fine-tuning is sufficient for promoting fairness of the deep neural network. Our framework brings new insights into representation learning in training fair neural networks.
FIFA: Making Fairness More Generalizable in Classifiers Trained on Imbalanced Data
Jun 06, 2022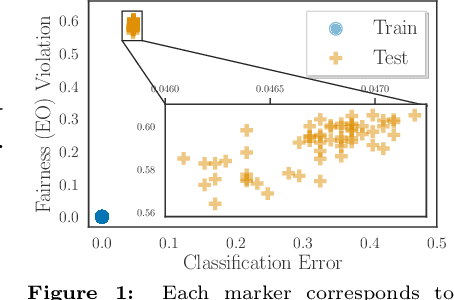
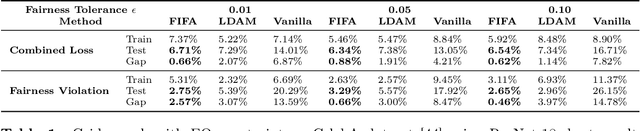
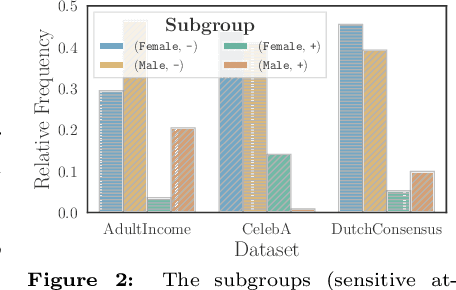
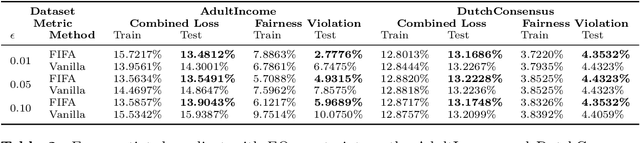
Algorithmic fairness plays an important role in machine learning and imposing fairness constraints during learning is a common approach. However, many datasets are imbalanced in certain label classes (e.g. "healthy") and sensitive subgroups (e.g. "older patients"). Empirically, this imbalance leads to a lack of generalizability not only of classification, but also of fairness properties, especially in over-parameterized models. For example, fairness-aware training may ensure equalized odds (EO) on the training data, but EO is far from being satisfied on new users. In this paper, we propose a theoretically-principled, yet Flexible approach that is Imbalance-Fairness-Aware (FIFA). Specifically, FIFA encourages both classification and fairness generalization and can be flexibly combined with many existing fair learning methods with logits-based losses. While our main focus is on EO, FIFA can be directly applied to achieve equalized opportunity (EqOpt); and under certain conditions, it can also be applied to other fairness notions. We demonstrate the power of FIFA by combining it with a popular fair classification algorithm, and the resulting algorithm achieves significantly better fairness generalization on several real-world datasets.
FastSeq: Make Sequence Generation Faster
Jun 08, 2021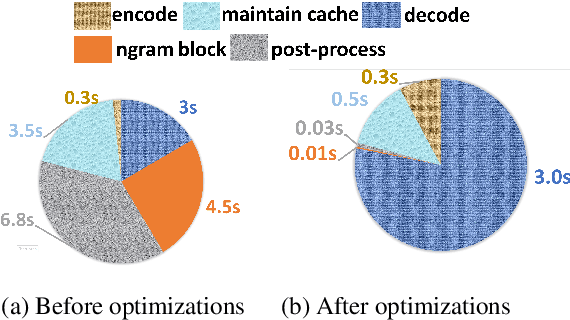
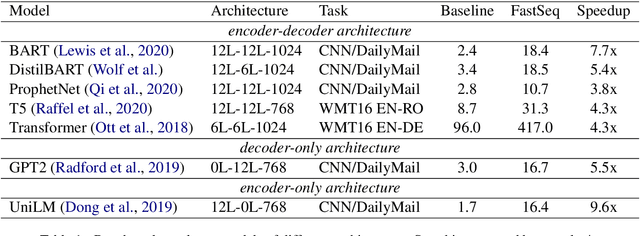
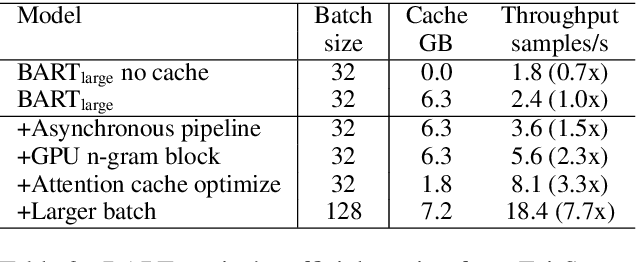
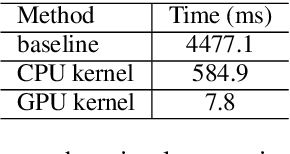
Transformer-based models have made tremendous impacts in natural language generation. However the inference speed is a bottleneck due to large model size and intensive computing involved in auto-regressive decoding process. We develop FastSeq framework to accelerate sequence generation without accuracy loss. The proposed optimization techniques include an attention cache optimization, an efficient algorithm for detecting repeated n-grams, and an asynchronous generation pipeline with parallel I/O. These optimizations are general enough to be applicable to Transformer-based models (e.g., T5, GPT2, and UniLM). Our benchmark results on a set of widely used and diverse models demonstrate 4-9x inference speed gain. Additionally, FastSeq is easy to use with a simple one-line code change. The source code is available at https://github.com/microsoft/fastseq.