 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastSeq: Make Sequence Generation Faster
Jun 08, 2021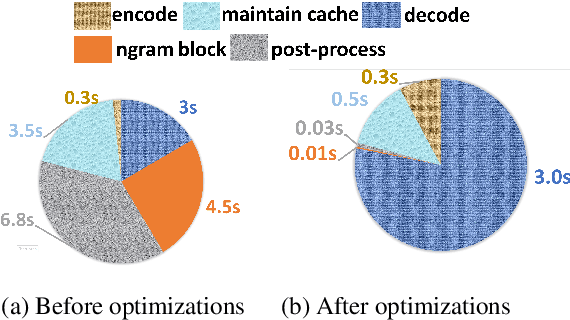
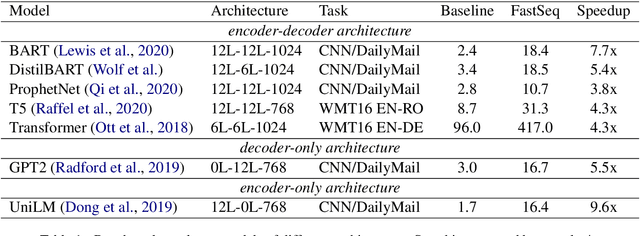
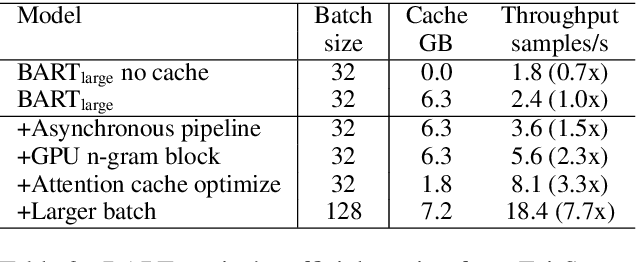
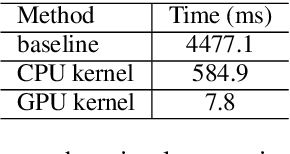
Transformer-based models have made tremendous impacts in natural language generation. However the inference speed is a bottleneck due to large model size and intensive computing involved in auto-regressive decoding process. We develop FastSeq framework to accelerate sequence generation without accuracy loss. The proposed optimization techniques include an attention cache optimization, an efficient algorithm for detecting repeated n-grams, and an asynchronous generation pipeline with parallel I/O. These optimizations are general enough to be applicable to Transformer-based models (e.g., T5, GPT2, and UniLM). Our benchmark results on a set of widely used and diverse models demonstrate 4-9x inference speed gain. Additionally, FastSeq is easy to use with a simple one-line code change. The source code is available at https://github.com/microsoft/fastseq.
EL-Attention: Memory Efficient Lossless Attention for Generation
May 11, 2021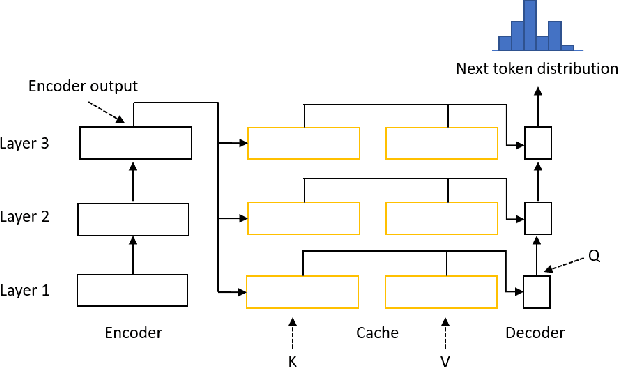
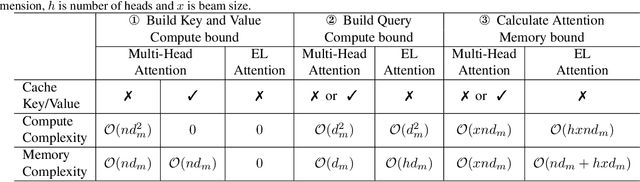
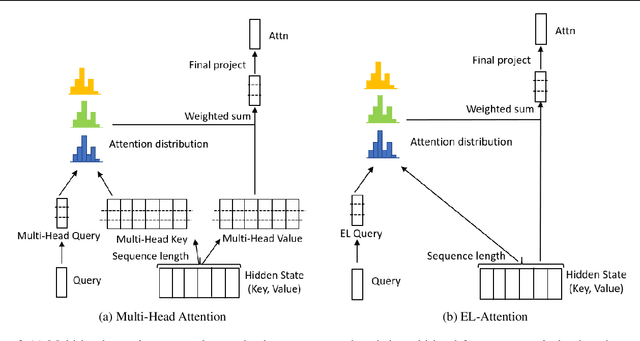
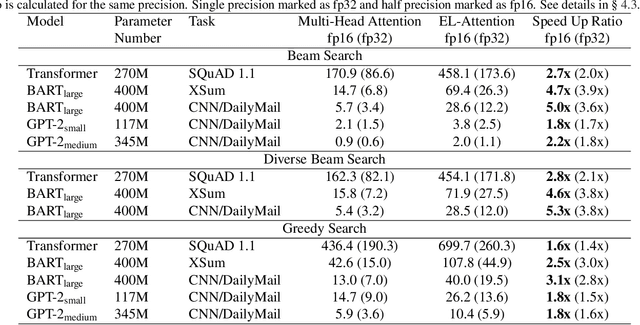
Transformer model with multi-head attention requires caching intermediate results for efficient inference in generation tasks. However, cache brings new memory-related costs and prevents leveraging larger batch size for faster speed. We propose memory-efficient lossless attention (called EL-attention) to address this issue. It avoids heavy operations for building multi-head keys and values, with no requirements of using cache. EL-attention constructs an ensemble of attention results by expanding query while keeping key and value shared. It produces the same result as multi-head attention with less GPU memory and faster inference speed. We conduct extensive experiments on Transformer, BART, and GPT-2 for summarization and question generation tasks. The results show EL-attention speeds up existing models by 1.6x to 5.3x without accuracy loss.
ProphetNet-X: Large-Scale Pre-training Models for English, Chinese, Multi-lingual, Dialog, and Code Generation
Apr 16, 2021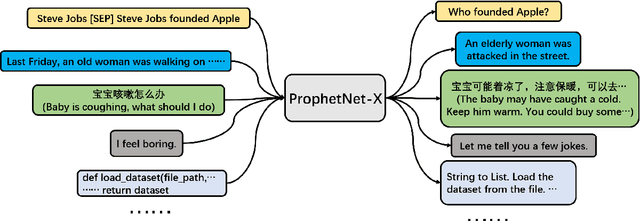

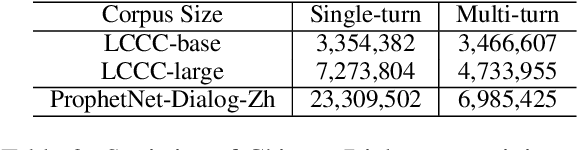
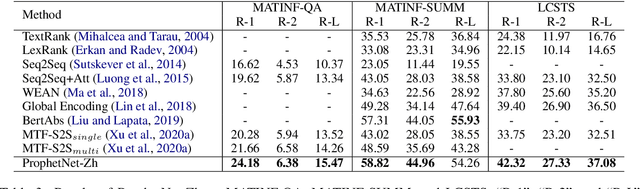
Now, the pre-training technique is ubiquitous in natural language processing field. ProphetNet is a pre-training based natural language generation method which shows powerful performance on English text summarization and question generation tasks. In this paper, we extend ProphetNet into other domains and languages, and present the ProphetNet family pre-training models, named ProphetNet-X, where X can be English, Chinese, Multi-lingual, and so on. We pre-train a cross-lingual generation model ProphetNet-Multi, a Chinese generation model ProphetNet-Zh, two open-domain dialog generation models ProphetNet-Dialog-En and ProphetNet-Dialog-Zh. And also, we provide a PLG (Programming Language Generation) model ProphetNet-Code to show the generation performance besides NLG (Natural Language Generation) tasks. In our experiments, ProphetNet-X models achieve new state-of-the-art performance on 10 benchmarks. All the models of ProphetNet-X share the same model structure, which allows users to easily switch between different models. We make the code and models publicly available, and we will keep updating more pre-training models and finetuning scripts. A video to introduce ProphetNet-X usage is also released.
BANG: Bridging Autoregressive and Non-autoregressive Generation with Large Scale Pretraining
Dec 31, 2020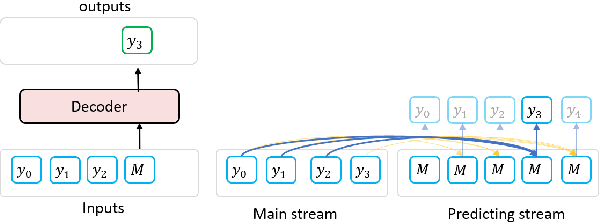
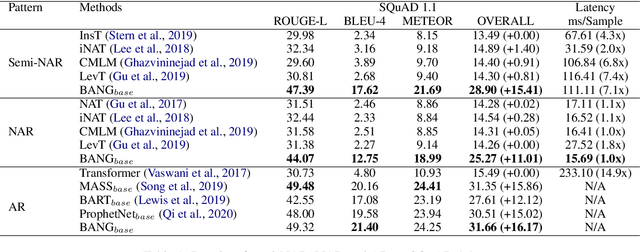
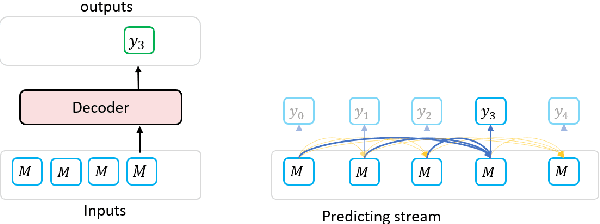

In this paper, we propose BANG, a new pretraining model to Bridge the gap between Autoregressive (AR) and Non-autoregressive (NAR) Generation. AR and NAR generation can be uniformly regarded as what extend of previous tokens can be attended to, and BANG bridges AR and NAR generation through designing a novel model structure for large-scale pre-training. A pretrained BANG model can simultaneously support AR, NAR, and semi-NAR generation to meet different requirements. Experiments on question generation (SQuAD 1.1), summarization (XSum), and dialogue (PersonaChat) show that BANG improves NAR and semi-NAR performance significantly as well as attaining comparable performance with strong AR pretrained models. Compared with the semi-NAR strong baselines, BANG achieves absolute improvements of 14.01 and 5.24 in overall scores of SQuAD and XSum, respectively. In addition, BANG achieves absolute improvements of 10.73, 6.39, and 5.90 in overall scores of SQuAD, XSUM, and PersonaChat compared with the NAR strong baselines, respectively. Our code will be made publicly available in the near future\footnote{https://github.com/microsoft/BANG}.
GLGE: A New General Language Generation Evaluation Benchmark
Nov 24, 2020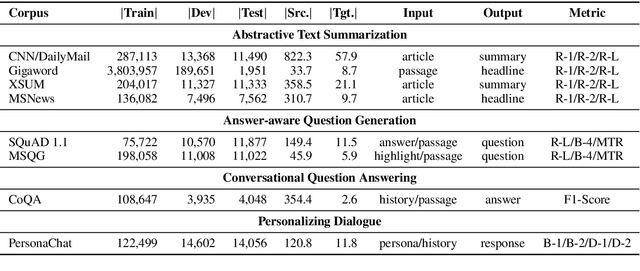
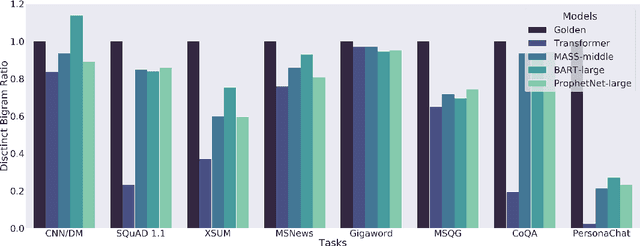

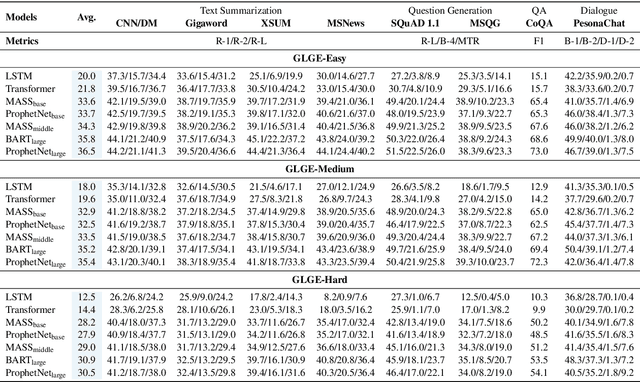
Multi-task benchmarks such as GLUE and SuperGLUE have driven great progress of pretraining and transfer learning in Natural Language Processing (NLP). These benchmarks mostly focus on a range of Natural Language Understanding (NLU) tasks, without considering the Natural Language Generation (NLG) models. In this paper, we present the General Language Generation Evaluation (GLGE), a new multi-task benchmark for evaluating the generalization capabilities of NLG models across eight language generation tasks. For each task, we continue to design three subtasks in terms of task difficulty (GLGE-Easy, GLGE-Medium, and GLGE-Hard). This introduces 24 subtasks to comprehensively compare model performance. To encourage research on pretraining and transfer learning on NLG models, we make GLGE publicly available and build a leaderboard with strong baselines including MASS, BART, and ProphetNet\footnote{The source code and dataset will be publicly available at https://github.com/microsoft/glge.
Tell Me How to Ask Again: Question Data Augmentation with Controllable Rewriting in Continuous Space
Oct 04, 2020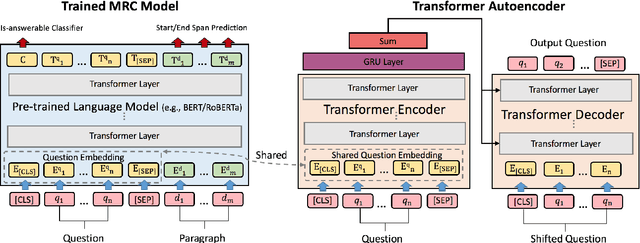
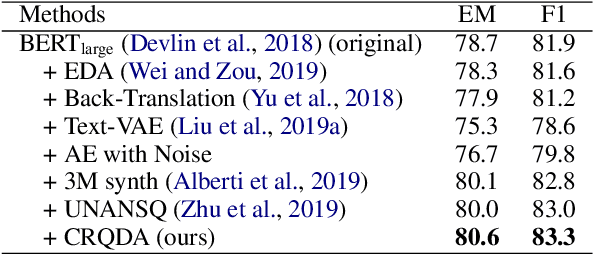

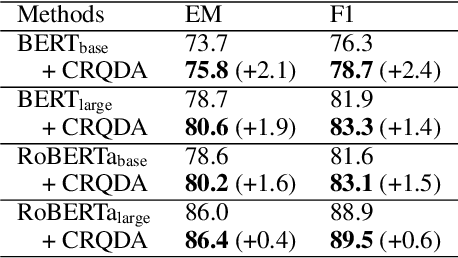
In this paper, we propose a novel data augmentation method, referred to as Controllable Rewriting based Question Data Augmentation (CRQDA), for machine reading comprehension (MRC), question generation, and question-answering natural language inference tasks. We treat the question data augmentation task as a constrained question rewriting problem to generate context-relevant, high-quality, and diverse question data samples. CRQDA utilizes a Transformer autoencoder to map the original discrete question into a continuous embedding space. It then uses a pre-trained MRC model to revise the question representation iteratively with gradient-based optimization. Finally, the revised question representations are mapped back into the discrete space, which serve as additional question data. Comprehensive experiments on SQuAD 2.0, SQuAD 1.1 question generation, and QNLI tasks demonstrate the effectiveness of CRQDA
RikiNet: Reading Wikipedia Pages for Natural Question Answering
Apr 30, 2020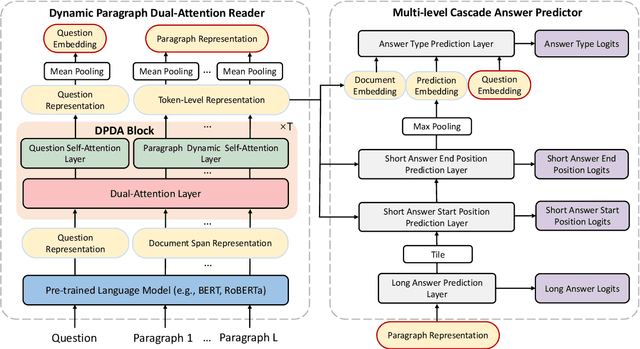
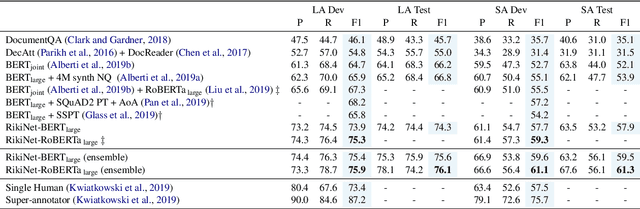
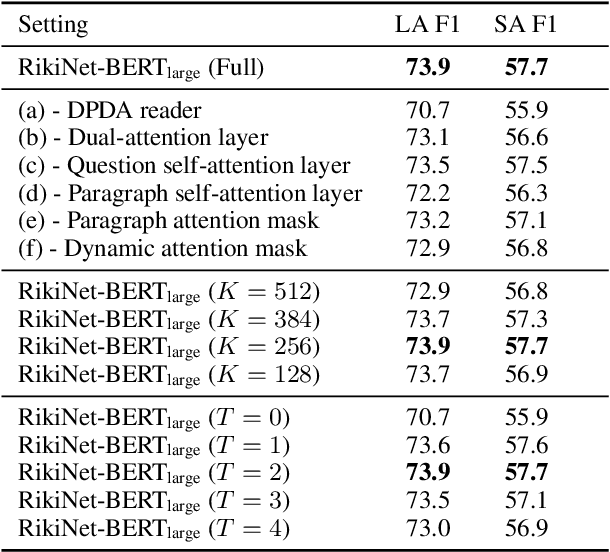
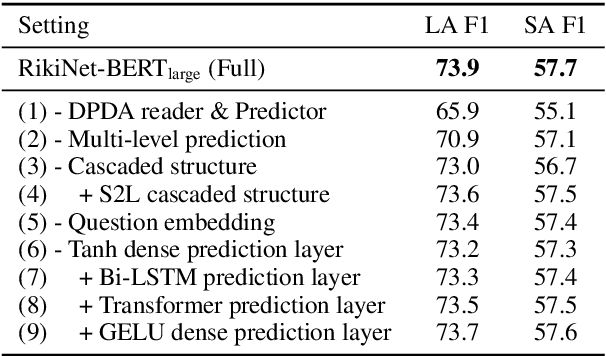
Reading long documents to answer open-domain questions remains challenging in natural language understanding. In this paper, we introduce a new model, called RikiNet, which reads Wikipedia pages for natural question answering. RikiNet contains a dynamic paragraph dual-attention reader and a multi-level cascaded answer predictor. The reader dynamically represents the document and question by utilizing a set of complementary attention mechanisms. The representations are then fed into the predictor to obtain the span of the short answer, the paragraph of the long answer, and the answer type in a cascaded manner. On the Natural Questions (NQ) dataset, a single RikiNet achieves 74.3 F1 and 57.9 F1 on long-answer and short-answer tasks. To our best knowledge, it is the first single model that outperforms the single human performance. Furthermore, an ensemble RikiNet obtains 76.1 F1 and 61.3 F1 on long-answer and short-answer tasks, achieving the best performance on the official NQ leaderboard
ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training
Feb 22, 2020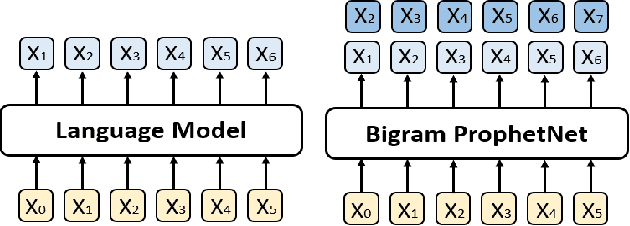
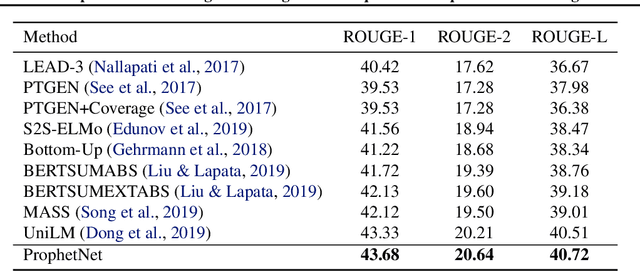
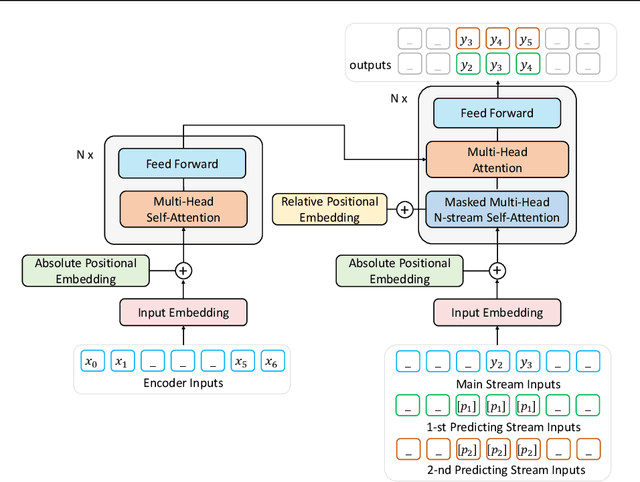
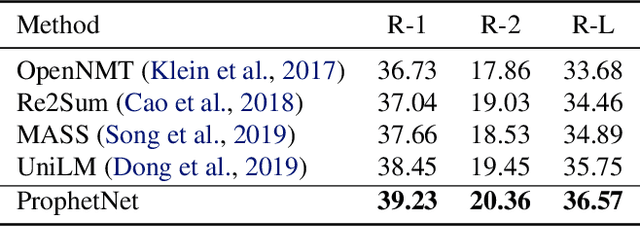
In this paper, we present a new sequence-to-sequence pre-training model called ProphetNet, which introduces a novel self-supervised objective named future n-gram prediction and the proposed n-stream self-attention mechanism. Instead of the optimization of one-step ahead prediction in traditional sequence-to-sequence model, the ProphetNet is optimized by n-step ahead prediction which predicts the next n tokens simultaneously based on previous context tokens at each time step. The future n-gram prediction explicitly encourages the model to plan for the future tokens and prevent overfitting on strong local correlations. We pre-train ProphetNet using a base scale dataset (16GB) and a large scale dataset (160GB) respectively. Then we conduct experiments on CNN/DailyMail, Gigaword, and SQuAD 1.1 benchmarks for abstractive summarization and question generation tasks. Experimental results show that ProphetNet achieves new state-of-the-art results on all these datasets compared to the models using the same scale pre-training corpus.