 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Single-Agent Alignment: Preventing Context-Fragmented Violations in Multi-Agent Systems
Apr 24, 2026We identify and formalize a novel security risk: Context-Fragmented Violations (CFVs) - a class of policy breaches where individual agent actions appear locally safe and reasonable, yet collectively violate organizational policies because critical policy facts are siloed in different departments private contexts. Existing prompt-based alignment mechanisms and monolithic interceptors are poorly matched to violations that span contextual islands. We propose Distributed Sentinel, a distributed zero-trust enforcement architecture that introduces the Semantic Taint Token (STT) Protocol. Through lightweight sidecar proxies, our system propagates security state across organizational boundaries without exposing raw cross-domain data, enabling Counterfactual Graph Simulation for cross-domain policy verification. We construct PhantomEcosystem, a comprehensive benchmark comprising 9 categories of realistic cross-agent violation scenarios with adversarially balanced safe controls. On this benchmark, Distributed Sentinel achieves F1 = 0.95 with 106ms end-to-end latency (16ms verification + 90ms entity extraction on A100), compared to 0.85 F1 for prompt-based filtering and 0.65 for rule-based DLP. To empirically validate the need for external enforcement, we evaluate eight frontier LLMs in execution-oriented multi-agent workflows with per-agent domain world models. All models exhibit substantial violation rates (14-98%), with cross-domain data flows showing systematically higher violation rates than same-domain flows. These results indicate that self-avoidance is unreliable and that multi-agent security benefits from a centralized enforcement layer operating above individual agents.
Policy-Invisible Violations in LLM-Based Agents
Apr 14, 2026LLM-based agents can execute actions that are syntactically valid, user-sanctioned, and semantically appropriate, yet still violate organizational policy because the facts needed for correct policy judgment are hidden at decision time. We call this failure mode policy-invisible violations: cases in which compliance depends on entity attributes, contextual state, or session history absent from the agent's visible context. We present PhantomPolicy, a benchmark spanning eight violation categories with balanced violation and safe-control cases, in which all tool responses contain clean business data without policy metadata. We manually review all 600 model traces produced by five frontier models and evaluate them using human-reviewed trace labels. Manual review changes 32 labels (5.3%) relative to the original case-level annotations, confirming the need for trace-level human review. To demonstrate what world-state-grounded enforcement can achieve under favorable conditions, we introduce Sentinel, an enforcement framework based on counterfactual graph simulation. Sentinel treats every agent action as a proposed mutation to an organizational knowledge graph, performs speculative execution to materialize the post-action world state, and verifies graph-structural invariants to decide Allow/Block/Clarify. Against human-reviewed trace labels, Sentinel substantially outperforms a content-only DLP baseline (68.8% vs. 93.0% accuracy) while maintaining high precision, though it still leaves room for improvement on certain violation categories. These results demonstrate what becomes achievable once policy-relevant world state is made available to the enforcement layer.
Multi-Level Service Performance Forecasting via Spatiotemporal Graph Neural Networks
Aug 09, 2025This paper proposes a spatiotemporal graph neural network-based performance prediction algorithm to address the challenge of forecasting performance fluctuations in distributed backend systems with multi-level service call structures. The method abstracts system states at different time slices into a sequence of graph structures. It integrates the runtime features of service nodes with the invocation relationships among services to construct a unified spatiotemporal modeling framework. The model first applies a graph convolutional network to extract high-order dependency information from the service topology. Then it uses a gated recurrent network to capture the dynamic evolution of performance metrics over time. A time encoding mechanism is also introduced to enhance the model's ability to represent non-stationary temporal sequences. The architecture is trained in an end-to-end manner, optimizing the multi-layer nested structure to achieve high-precision regression of future service performance metrics. To validate the effectiveness of the proposed method, a large-scale public cluster dataset is used. A series of multi-dimensional experiments are designed, including variations in time windows and concurrent load levels. These experiments comprehensively evaluate the model's predictive performance and stability. The experimental results show that the proposed model outperforms existing representative methods across key metrics such as MAE, RMSE, and R2. It maintains strong robustness under varying load intensities and structural complexities. These results demonstrate the model's practical potential for backend service performance management tasks.
Quantifying the Robustness of Retrieval-Augmented Language Models Against Spurious Features in Grounding Data
Mar 07, 2025Robustness has become a critical attribute for the deployment of RAG systems in real-world applications. Existing research focuses on robustness to explicit noise (e.g., document semantics) but overlooks spurious features (a.k.a. implicit noise). While previous works have explored spurious features in LLMs, they are limited to specific features (e.g., formats) and narrow scenarios (e.g., ICL). In this work, we statistically confirm the presence of spurious features in the RAG paradigm, a robustness problem caused by the sensitivity of LLMs to semantic-agnostic features. Moreover, we provide a comprehensive taxonomy of spurious features and empirically quantify their impact through controlled experiments. Further analysis reveals that not all spurious features are harmful and they can even be beneficial sometimes. Extensive evaluation results across multiple LLMs suggest that spurious features are a widespread and challenging problem in the field of RAG. The code and dataset will be released to facilitate future research. We release all codes and data at: $\\\href{https://github.com/maybenotime/RAG-SpuriousFeatures}{https://github.com/maybenotime/RAG-SpuriousFeatures}$.
MuDAF: Long-Context Multi-Document Attention Focusing through Contrastive Learning on Attention Heads
Feb 19, 2025Large Language Models (LLMs) frequently show distracted attention due to irrelevant information in the input, which severely impairs their long-context capabilities. Inspired by recent studies on the effectiveness of retrieval heads in long-context factutality, we aim at addressing this distraction issue through improving such retrieval heads directly. We propose Multi-Document Attention Focusing (MuDAF), a novel method that explicitly optimizes the attention distribution at the head level through contrastive learning. According to the experimental results, MuDAF can significantly improve the long-context question answering performance of LLMs, especially in multi-document question answering. Extensive evaluations on retrieval scores and attention visualizations show that MuDAF possesses great potential in making attention heads more focused on relevant information and reducing attention distractions.
AutoDirector: Online Auto-scheduling Agents for Multi-sensory Composition
Aug 21, 2024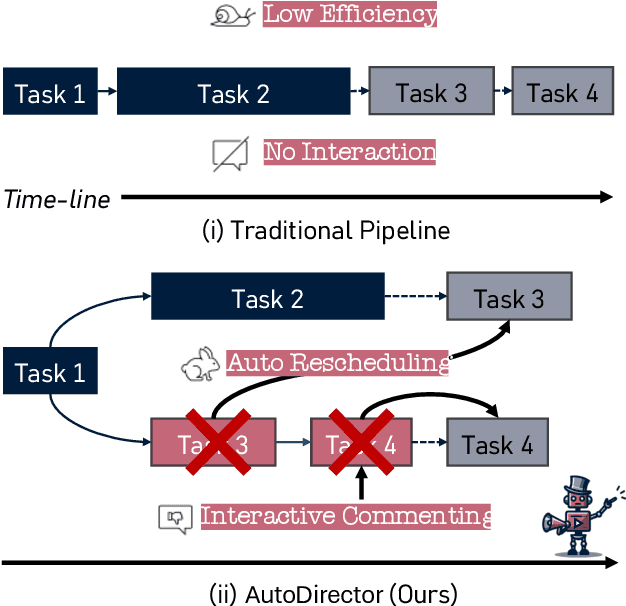

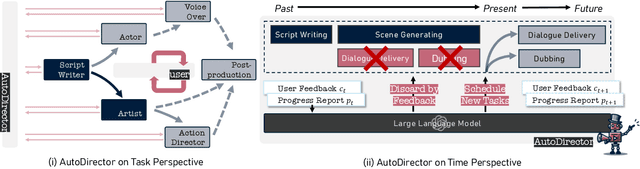

With the advancement of generative models, the synthesis of different sensory elements such as music, visuals, and speech has achieved significant realism. However, the approach to generate multi-sensory outputs has not been fully explored, limiting the application on high-value scenarios such as of directing a film. Developing a movie director agent faces two major challenges: (1) Lack of parallelism and online scheduling with production steps: In the production of multi-sensory films, there are complex dependencies between different sensory elements, and the production time for each element varies. (2) Diverse needs and clear communication demands with users: Users often cannot clearly express their needs until they see a draft, which requires human-computer interaction and iteration to continually adjust and optimize the film content based on user feedback. To address these issues, we introduce AutoDirector, an interactive multi-sensory composition framework that supports long shots, special effects, music scoring, dubbing, and lip-syncing. This framework improves the efficiency of multi-sensory film production through automatic scheduling and supports the modification and improvement of interactive tasks to meet user needs. AutoDirector not only expands the application scope of human-machine collaboration but also demonstrates the potential of AI in collaborating with humans in the role of a film director to complete multi-sensory films.
Step-Back Profiling: Distilling User History for Personalized Scientific Writing
Jun 20, 2024Large language models (LLMs) excel at a variety of natural language processing tasks, yet they struggle to generate personalized content for individuals, particularly in real-world scenarios like scientific writing. Addressing this challenge, we introduce Step-Back Profiling to personalize LLMs by distilling user history into concise profiles, including essential traits and preferences of users. Regarding our experiments, we construct a Personalized Scientific Writing (PSW) dataset to study multiuser personalization. PSW requires the models to write scientific papers given specialized author groups with diverse academic backgrounds. As for the results, we demonstrate the effectiveness of capturing user characteristics via Step-Back Profiling for collaborative writing. Moreover, our approach outperforms the baselines by up to 3.6 points on the general personalization benchmark (LaMP), including 7 personalization LLM tasks. Our extensive ablation studies validate the contributions of different components in our method and provide insights into our task definition. Our dataset and code are available at \url{https://github.com/gersteinlab/step-back-profiling}.
Towards Truthful Multilingual Large Language Models: Benchmarking and Alignment Strategies
Jun 20, 2024In the era of large language models (LLMs), building multilingual large language models (MLLMs) that can serve users worldwide holds great significance. However, existing research seldom focuses on the truthfulness of MLLMs. Meanwhile, contemporary multilingual aligning technologies struggle to balance massive languages and often exhibit serious truthfulness gaps across different languages, especially those that differ greatly from English. In our work, we construct a benchmark for truthfulness evaluation in multilingual scenarios and explore the ways to align facts across languages to enhance the truthfulness of MLLMs. Furthermore, we propose Fact-aware Multilingual Selective Synergy (FaMSS) to optimize the data allocation across a large number of languages and different data types. Experimental results demonstrate that our approach can effectively reduce the multilingual representation disparity and enhance the multilingual capabilities of LLMs.
TGGLinesPlus: A robust topological graph-guided computer vision algorithm for line detection from images
Mar 26, 2024



Line detection is a classic and essential problem in image processing, computer vision and machine intelligence. Line detection has many important applications, including image vectorization (e.g., document recognition and art design), indoor mapping, and important societal challenges (e.g., sea ice fracture line extraction from satellite imagery). Many line detection algorithms and methods have been developed, but robust and intuitive methods are still lacking. In this paper, we proposed and implemented a topological graph-guided algorithm, named TGGLinesPlus, for line detection. Our experiments on images from a wide range of domains have demonstrated the flexibility of our TGGLinesPlus algorithm. We also benchmarked our algorithm with five classic and state-of-the-art line detection methods and the results demonstrate the robustness of TGGLinesPlus. We hope our open-source implementation of TGGLinesPlus will inspire and pave the way for many applications where spatial science matters.
Hypertext Entity Extraction in Webpage
Mar 04, 2024



Webpage entity extraction is a fundamental natural language processing task in both research and applications. Nowadays, the majority of webpage entity extraction models are trained on structured datasets which strive to retain textual content and its structure information. However, existing datasets all overlook the rich hypertext features (e.g., font color, font size) which show their effectiveness in previous works. To this end, we first collect a \textbf{H}ypertext \textbf{E}ntity \textbf{E}xtraction \textbf{D}ataset (\textit{HEED}) from the e-commerce domains, scraping both the text and the corresponding explicit hypertext features with high-quality manual entity annotations. Furthermore, we present the \textbf{Mo}E-based \textbf{E}ntity \textbf{E}xtraction \textbf{F}ramework (\textit{MoEEF}), which efficiently integrates multiple features to enhance model performance by Mixture of Experts and outperforms strong baselines, including the state-of-the-art small-scale models and GPT-3.5-turbo. Moreover, the effectiveness of hypertext features in \textit{HEED} and several model components in \textit{MoEEF} are analyzed.