 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Level Service Performance Forecasting via Spatiotemporal Graph Neural Networks
Aug 09, 2025This paper proposes a spatiotemporal graph neural network-based performance prediction algorithm to address the challenge of forecasting performance fluctuations in distributed backend systems with multi-level service call structures. The method abstracts system states at different time slices into a sequence of graph structures. It integrates the runtime features of service nodes with the invocation relationships among services to construct a unified spatiotemporal modeling framework. The model first applies a graph convolutional network to extract high-order dependency information from the service topology. Then it uses a gated recurrent network to capture the dynamic evolution of performance metrics over time. A time encoding mechanism is also introduced to enhance the model's ability to represent non-stationary temporal sequences. The architecture is trained in an end-to-end manner, optimizing the multi-layer nested structure to achieve high-precision regression of future service performance metrics. To validate the effectiveness of the proposed method, a large-scale public cluster dataset is used. A series of multi-dimensional experiments are designed, including variations in time windows and concurrent load levels. These experiments comprehensively evaluate the model's predictive performance and stability. The experimental results show that the proposed model outperforms existing representative methods across key metrics such as MAE, RMSE, and R2. It maintains strong robustness under varying load intensities and structural complexities. These results demonstrate the model's practical potential for backend service performance management tasks.
An Enhanced Encoder-Decoder Network Architecture for Reducing Information Loss in Image Semantic Segmentation
May 26, 2024



The traditional SegNet architecture commonly encounters significant information loss during the sampling process, which detrimentally affects its accuracy in image semantic segmentation tasks. To counter this challenge, we introduce an innovative encoder-decoder network structure enhanced with residual connections. Our approach employs a multi-residual connection strategy designed to preserve the intricate details across various image scales more effectively, thus minimizing the information loss inherent to down-sampling procedures. Additionally, to enhance the convergence rate of network training and mitigate sample imbalance issues, we have devised a modified cross-entropy loss function incorporating a balancing factor. This modification optimizes the distribution between positive and negative samples, thus improving the efficiency of model training. Experimental evaluations of our model demonstrate a substantial reduction in information loss and improved accuracy in semantic segmentation. Notably, our proposed network architecture demonstrates a substantial improvement in the finely annotated mean Intersection over Union (mIoU) on the dataset compared to the conventional SegNet. The proposed network structure not only reduces operational costs by decreasing manual inspection needs but also scales up the deployment of AI-driven image analysis across different sectors.
Efficiency optimization of large-scale language models based on deep learning in natural language processing tasks
May 20, 2024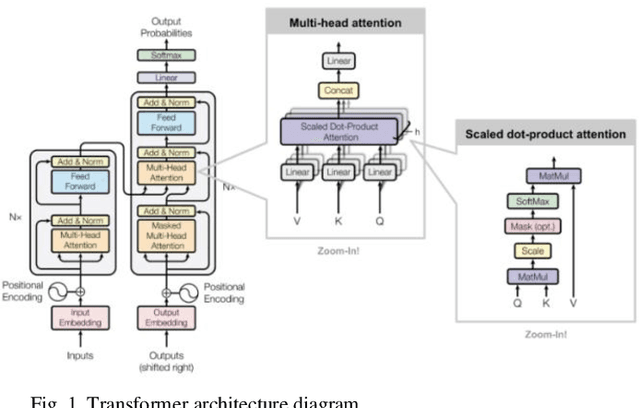
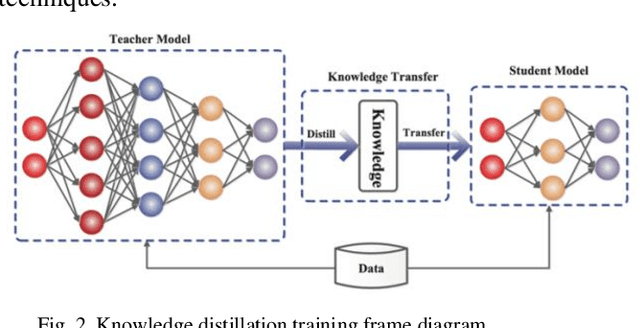
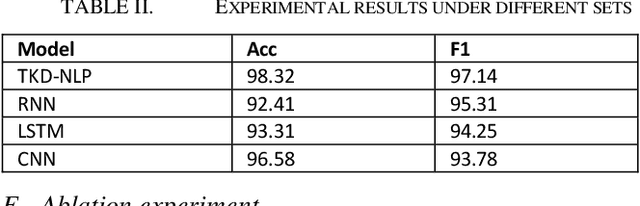
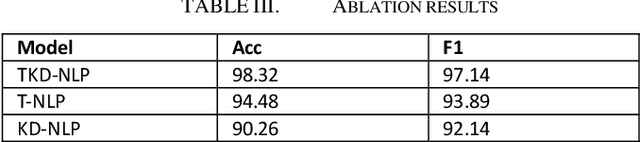
The internal structure and operation mechanism of large-scale language models are analyzed theoretically, especially how Transformer and its derivative architectures can restrict computing efficiency while capturing long-term dependencies. Further, we dig deep into the efficiency bottleneck of the training phase, and evaluate in detail the contribution of adaptive optimization algorithms (such as AdamW), massively parallel computing techniques, and mixed precision training strategies to accelerate convergence and reduce memory footprint. By analyzing the mathematical principles and implementation details of these algorithms, we reveal how they effectively improve training efficiency in practice. In terms of model deployment and inference optimization, this paper systematically reviews the latest advances in model compression techniques, focusing on strategies such as quantification, pruning, and knowledge distillation. By comparing the theoretical frameworks of these techniques and their effects in different application scenarios, we demonstrate their ability to significantly reduce model size and inference delay while maintaining model prediction accuracy. In addition, this paper critically examines the limitations of current efficiency optimization methods, such as the increased risk of overfitting, the control of performance loss after compression, and the problem of algorithm generality, and proposes some prospects for future research. In conclusion, this study provides a comprehensive theoretical framework for understanding the efficiency optimization of large-scale language models.