 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiency optimization of large-scale language models based on deep learning in natural language processing tasks
Paper and Code
May 20, 2024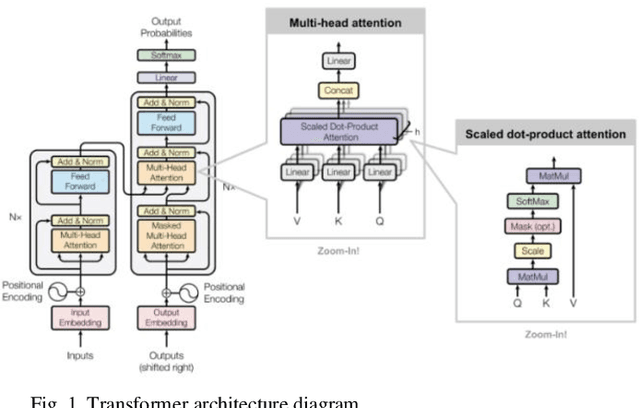
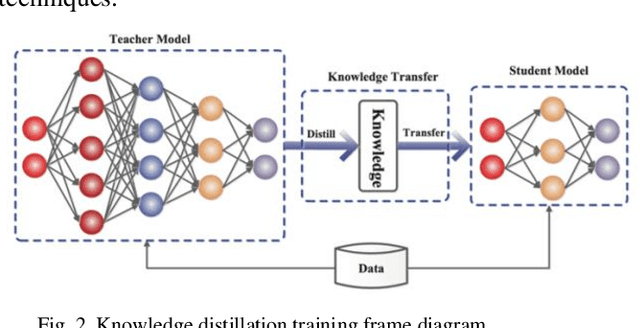
The internal structure and operation mechanism of large-scale language models are analyzed theoretically, especially how Transformer and its derivative architectures can restrict computing efficiency while capturing long-term dependencies. Further, we dig deep into the efficiency bottleneck of the training phase, and evaluate in detail the contribution of adaptive optimization algorithms (such as AdamW), massively parallel computing techniques, and mixed precision training strategies to accelerate convergence and reduce memory footprint. By analyzing the mathematical principles and implementation details of these algorithms, we reveal how they effectively improve training efficiency in practice. In terms of model deployment and inference optimization, this paper systematically reviews the latest advances in model compression techniques, focusing on strategies such as quantification, pruning, and knowledge distillation. By comparing the theoretical frameworks of these techniques and their effects in different application scenarios, we demonstrate their ability to significantly reduce model size and inference delay while maintaining model prediction accuracy. In addition, this paper critically examines the limitations of current efficiency optimization methods, such as the increased risk of overfitting, the control of performance loss after compression, and the problem of algorithm generality, and proposes some prospects for future research. In conclusion, this study provides a comprehensive theoretical framework for understanding the efficiency optimization of large-scale language models.