 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Convolutional Neural Networks with Higher-Order Numerical Difference Methods
Sep 08, 2024

With the rise of deep learning technology in practical applications, Convolutional Neural Networks (CNNs) have been able to assist humans in solving many real-world problems. To enhance the performance of CNNs, numerous network architectures have been explored. Some of these architectures are designed based on the accumulated experience of researchers over time, while others are designed through neural architecture search methods. The improvements made to CNNs by the aforementioned methods are quite significant, but most of the improvement methods are limited in reality by model size and environmental constraints, making it difficult to fully realize the improved performance. In recent years, research has found that many CNN structures can be explained by the discretization of ordinary differential equations. This implies that we can design theoretically supported deep network structures using higher-order numerical difference methods. It should be noted that most of the previous CNN model structures are based on low-order numerical methods. Therefore, considering that the accuracy of linear multi-step numerical difference methods is higher than that of the forward Euler method, this paper proposes a stacking scheme based on the linear multi-step method. This scheme enhances the performance of ResNet without increasing the model size and compares it with the Runge-Kutta scheme. The experimental results show that the performance of the stacking scheme proposed in this paper is superior to existing stacking schemes (ResNet and HO-ResNet), and it has the capability to be extended to other types of neural networks.
An Enhanced Encoder-Decoder Network Architecture for Reducing Information Loss in Image Semantic Segmentation
May 26, 2024



The traditional SegNet architecture commonly encounters significant information loss during the sampling process, which detrimentally affects its accuracy in image semantic segmentation tasks. To counter this challenge, we introduce an innovative encoder-decoder network structure enhanced with residual connections. Our approach employs a multi-residual connection strategy designed to preserve the intricate details across various image scales more effectively, thus minimizing the information loss inherent to down-sampling procedures. Additionally, to enhance the convergence rate of network training and mitigate sample imbalance issues, we have devised a modified cross-entropy loss function incorporating a balancing factor. This modification optimizes the distribution between positive and negative samples, thus improving the efficiency of model training. Experimental evaluations of our model demonstrate a substantial reduction in information loss and improved accuracy in semantic segmentation. Notably, our proposed network architecture demonstrates a substantial improvement in the finely annotated mean Intersection over Union (mIoU) on the dataset compared to the conventional SegNet. The proposed network structure not only reduces operational costs by decreasing manual inspection needs but also scales up the deployment of AI-driven image analysis across different sectors.
Efficiency optimization of large-scale language models based on deep learning in natural language processing tasks
May 20, 2024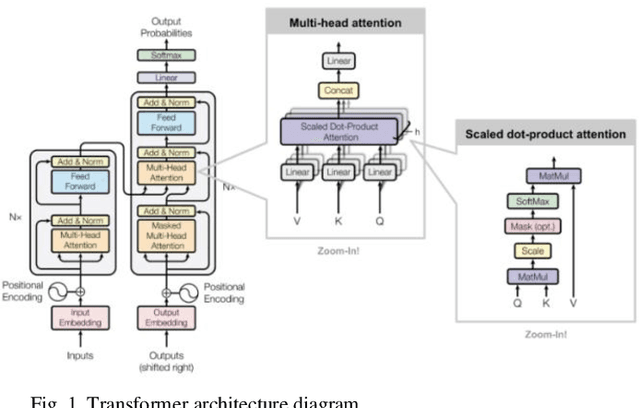
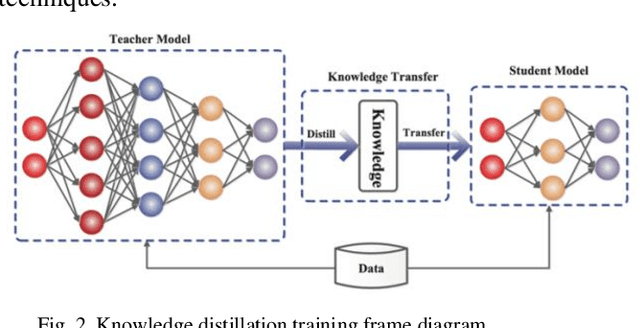
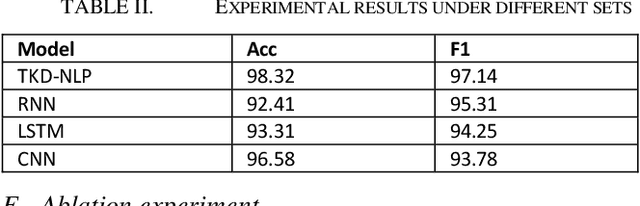
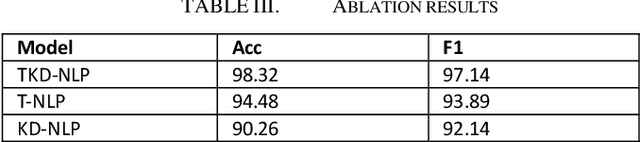
The internal structure and operation mechanism of large-scale language models are analyzed theoretically, especially how Transformer and its derivative architectures can restrict computing efficiency while capturing long-term dependencies. Further, we dig deep into the efficiency bottleneck of the training phase, and evaluate in detail the contribution of adaptive optimization algorithms (such as AdamW), massively parallel computing techniques, and mixed precision training strategies to accelerate convergence and reduce memory footprint. By analyzing the mathematical principles and implementation details of these algorithms, we reveal how they effectively improve training efficiency in practice. In terms of model deployment and inference optimization, this paper systematically reviews the latest advances in model compression techniques, focusing on strategies such as quantification, pruning, and knowledge distillation. By comparing the theoretical frameworks of these techniques and their effects in different application scenarios, we demonstrate their ability to significantly reduce model size and inference delay while maintaining model prediction accuracy. In addition, this paper critically examines the limitations of current efficiency optimization methods, such as the increased risk of overfitting, the control of performance loss after compression, and the problem of algorithm generality, and proposes some prospects for future research. In conclusion, this study provides a comprehensive theoretical framework for understanding the efficiency optimization of large-scale language models.