 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegRap2025: A Benchmark of Gross Tumor Volume and Lymph Node Clinical Target Volume Segmentation for Radiotherapy Planning of Nasopharyngeal Carcinoma
Jan 28, 2026Accurate delineation of Gross Tumor Volume (GTV), Lymph Node Clinical Target Volume (LN CTV), and Organ-at-Risk (OAR) from Computed Tomography (CT) scans is essential for precise radiotherapy planning in Nasopharyngeal Carcinoma (NPC). Building upon SegRap2023, which focused on OAR and GTV segmentation using single-center paired non-contrast CT (ncCT) and contrast-enhanced CT (ceCT) scans, the SegRap2025 challenge aims to enhance the generalizability and robustness of segmentation models across imaging centers and modalities. SegRap2025 comprises two tasks: Task01 addresses GTV segmentation using paired CT from the SegRap2023 dataset, with an additional external testing set to evaluate cross-center generalization, and Task02 focuses on LN CTV segmentation using multi-center training data and an unseen external testing set, where each case contains paired CT scans or a single modality, emphasizing both cross-center and cross-modality robustness. This paper presents the challenge setup and provides a comprehensive analysis of the solutions submitted by ten participating teams. For GTV segmentation task, the top-performing models achieved average Dice Similarity Coefficient (DSC) of 74.61% and 56.79% on the internal and external testing cohorts, respectively. For LN CTV segmentation task, the highest average DSC values reached 60.24%, 60.50%, and 57.23% on paired CT, ceCT-only, and ncCT-only subsets, respectively. SegRap2025 establishes a large-scale multi-center, multi-modality benchmark for evaluating the generalization and robustness in radiotherapy target segmentation, providing valuable insights toward clinically applicable automated radiotherapy planning systems. The benchmark is available at: https://hilab-git.github.io/SegRap2025_Challenge.
Conformal novelty detection with false discovery rate control at the boundary
Jan 06, 2026Conformal novelty detection is a classical machine learning task for which uncertainty quantification is essential for providing reliable results. Recent work has shown that the BH procedure applied to conformal p-values controls the false discovery rate (FDR). Unfortunately, the BH procedure can lead to over-optimistic assessments near the rejection threshold, with an increase of false discoveries at the margin as pointed out by Soloff et al. (2024). This issue is solved therein by the support line (SL) correction, which is proven to control the boundary false discovery rate (bFDR) in the independent, non-conformal setting. The present work extends the SL method to the conformal setting: first, we show that the SL procedure can violate the bFDR control in this specific setting. Second, we propose several alternatives that provably control the bFDR in the conformal setting. Finally, numerical experiments with both synthetic and real data support our theoretical findings and show the relevance of the new proposed procedures.
CORE: Concept-Oriented Reinforcement for Bridging the Definition-Application Gap in Mathematical Reasoning
Dec 21, 2025

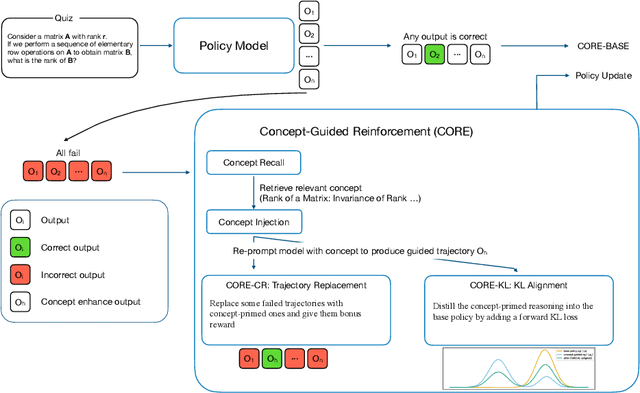
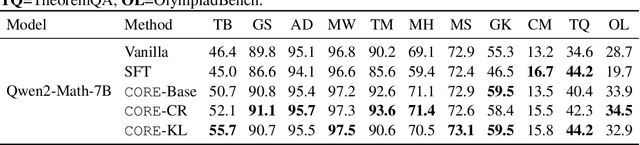
Large language models (LLMs) often solve challenging math exercises yet fail to apply the concept right when the problem requires genuine understanding. Popular Reinforcement Learning with Verifiable Rewards (RLVR) pipelines reinforce final answers but provide little fine-grained conceptual signal, so models improve at pattern reuse rather than conceptual applications. We introduce CORE (Concept-Oriented REinforcement), an RL training framework that turns explicit concepts into a controllable supervision signal. Starting from a high-quality, low-contamination textbook resource that links verifiable exercises to concise concept descriptions, we run a sanity probe showing LLMs can restate definitions but fail concept-linked quizzes, quantifying the conceptual reasoning gap. CORE then (i) synthesizes concept-aligned quizzes, (ii) injects brief concept snippets during rollouts to elicit concept-primed trajectories, and (iii) reinforces conceptual reasoning via trajectory replacement after group failures, a lightweight forward-KL constraint that aligns unguided with concept-primed policies, or standard GRPO directly on concept-aligned quizzes. Across several models, CORE delivers consistent gains over vanilla and SFT baselines on both in-domain concept-exercise suites and diverse out-of-domain math benchmarks. CORE unifies direct training on concept-aligned quizzes and concept-injected rollouts under outcome regularization. It provides fine-grained conceptual supervision that bridges problem-solving competence and genuine conceptual reasoning, while remaining algorithm- and verifier-agnostic.
Trustworthy Evaluation of Generative AI Models
Jan 31, 2025Generative AI (GenAI) models have recently achieved remarkable empirical performance in various applications, however, their evaluations yet lack uncertainty quantification. In this paper, we propose a method to compare two generative models based on an unbiased estimator of their relative performance gap. Statistically, our estimator achieves parametric convergence rate and asymptotic normality, which enables valid inference. Computationally, our method is efficient and can be accelerated by parallel computing and leveraging pre-storing intermediate results. On simulated datasets with known ground truth, we show our approach effectively controls type I error and achieves power comparable with commonly used metrics. Furthermore, we demonstrate the performance of our method in evaluating diffusion models on real image datasets with statistical confidence.
Counterfactual explainability of black-box prediction models
Nov 03, 2024It is crucial to be able to explain black-box prediction models to use them effectively and safely in practice. Most existing tools for model explanations are associational rather than causal, and we use two paradoxical examples to show that such explanations are generally inadequate. Motivated by the concept of genetic heritability in twin studies, we propose a new notion called counterfactual explainability for black-box prediction models. Counterfactual explainability has three key advantages: (1) it leverages counterfactual outcomes and extends methods for global sensitivity analysis (such as functional analysis of variance and Sobol's indices) to a causal setting; (2) it is defined not only for the totality of a set of input factors but also for their interactions (indeed, it is a probability measure on a whole ``explanation algebra''); (3) it also applies to dependent input factors whose causal relationship can be modeled by a directed acyclic graph, thus incorporating causal mechanisms into the explanation.
Enhancing Convolutional Neural Networks with Higher-Order Numerical Difference Methods
Sep 08, 2024

With the rise of deep learning technology in practical applications, Convolutional Neural Networks (CNNs) have been able to assist humans in solving many real-world problems. To enhance the performance of CNNs, numerous network architectures have been explored. Some of these architectures are designed based on the accumulated experience of researchers over time, while others are designed through neural architecture search methods. The improvements made to CNNs by the aforementioned methods are quite significant, but most of the improvement methods are limited in reality by model size and environmental constraints, making it difficult to fully realize the improved performance. In recent years, research has found that many CNN structures can be explained by the discretization of ordinary differential equations. This implies that we can design theoretically supported deep network structures using higher-order numerical difference methods. It should be noted that most of the previous CNN model structures are based on low-order numerical methods. Therefore, considering that the accuracy of linear multi-step numerical difference methods is higher than that of the forward Euler method, this paper proposes a stacking scheme based on the linear multi-step method. This scheme enhances the performance of ResNet without increasing the model size and compares it with the Runge-Kutta scheme. The experimental results show that the performance of the stacking scheme proposed in this paper is superior to existing stacking schemes (ResNet and HO-ResNet), and it has the capability to be extended to other types of neural networks.
Comprehensive Review and Empirical Evaluation of Causal Discovery Algorithms for Numerical Data
Jul 17, 2024Causal analysis has become an essential component in understanding the underlying causes of phenomena across various fields. Despite its significance, the existing literature on causal discovery algorithms is fragmented, with inconsistent methodologies and a lack of comprehensive evaluations. This study addresses these gaps by conducting an exhaustive review and empirical evaluation of causal discovery methods for numerical data, aiming to provide a clearer and more structured understanding of the field. Our research began with a comprehensive literature review spanning over a decade, revealing that existing surveys fall short in covering the vast array of causal discovery advancements. We meticulously analyzed over 200 scholarly articles to identify 24 distinct algorithms. This extensive analysis led to the development of a novel taxonomy tailored to the complexities of causal discovery, categorizing methods into six main types. Addressing the lack of comprehensive evaluations, our study conducts an extensive empirical assessment of more than 20 causal discovery algorithms on synthetic and real-world datasets. We categorize synthetic datasets based on size, linearity, and noise distribution, employing 5 evaluation metrics, and summarized the top-3 algorithm recommendations for different data scenarios. The recommendations have been validated on 2 real-world datasets. Our results highlight the significant impact of dataset characteristics on algorithm performance. Moreover, a metadata extraction strategy was developed to assist users in algorithm selection on unknown datasets. The accuracy of estimating metadata is higher than 80%. Based on these insights, we offer professional and practical recommendations to help users choose the most suitable causal discovery methods for their specific dataset needs.
An Uncertainty-guided Tiered Self-training Framework for Active Source-free Domain Adaptation in Prostate Segmentation
Jul 03, 2024
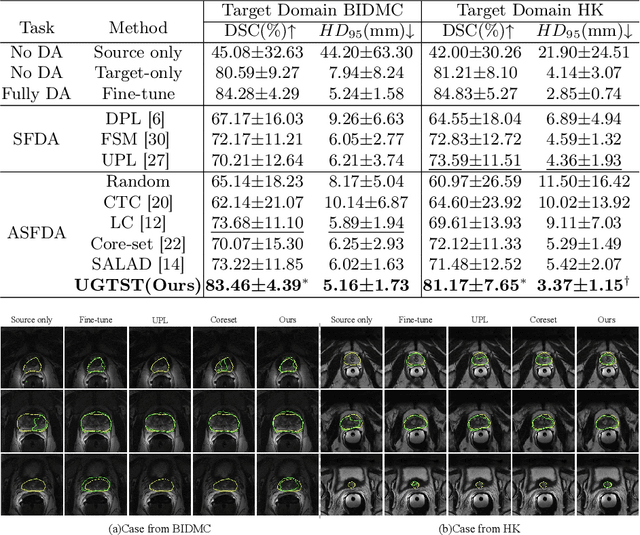
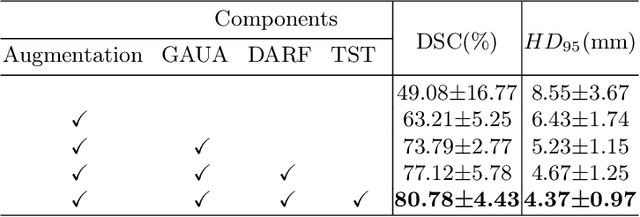
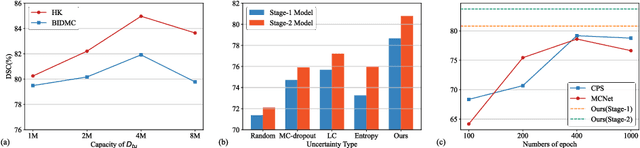
Deep learning models have exhibited remarkable efficacy in accurately delineating the prostate for diagnosis and treatment of prostate diseases, but challenges persist in achieving robust generalization across different medical centers. Source-free Domain Adaptation (SFDA) is a promising technique to adapt deep segmentation models to address privacy and security concerns while reducing domain shifts between source and target domains. However, recent literature indicates that the performance of SFDA remains far from satisfactory due to unpredictable domain gaps. Annotating a few target domain samples is acceptable, as it can lead to significant performance improvement with a low annotation cost. Nevertheless, due to extremely limited annotation budgets, careful consideration is needed in selecting samples for annotation. Inspired by this, our goal is to develop Active Source-free Domain Adaptation (ASFDA) for medical image segmentation. Specifically, we propose a novel Uncertainty-guided Tiered Self-training (UGTST) framework, consisting of efficient active sample selection via entropy-based primary local peak filtering to aggregate global uncertainty and diversity-aware redundancy filter, coupled with a tiered self-learning strategy, achieves stable domain adaptation. Experimental results on cross-center prostate MRI segmentation datasets revealed that our method yielded marked advancements, with a mere 5% annotation, exhibiting an average Dice score enhancement of 9.78% and 7.58% in two target domains compared with state-of-the-art methods, on par with fully supervised learning. Code is available at:https://github.com/HiLab-git/UGTST
Images Speak Louder than Words: Understanding and Mitigating Bias in Vision-Language Model from a Causal Mediation Perspective
Jul 03, 2024
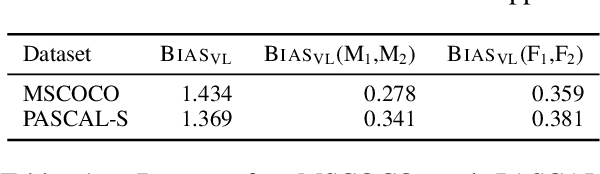

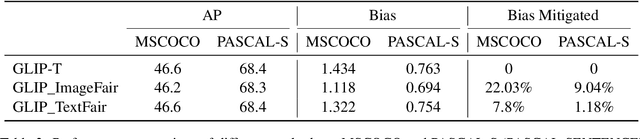
Vision-language models (VLMs) pre-trained on extensive datasets can inadvertently learn biases by correlating gender information with specific objects or scenarios. Current methods, which focus on modifying inputs and monitoring changes in the model's output probability scores, often struggle to comprehensively understand bias from the perspective of model components. We propose a framework that incorporates causal mediation analysis to measure and map the pathways of bias generation and propagation within VLMs. This approach allows us to identify the direct effects of interventions on model bias and the indirect effects of interventions on bias mediated through different model components. Our results show that image features are the primary contributors to bias, with significantly higher impacts than text features, specifically accounting for 32.57% and 12.63% of the bias in the MSCOCO and PASCAL-SENTENCE datasets, respectively. Notably, the image encoder's contribution surpasses that of the text encoder and the deep fusion encoder. Further experimentation confirms that contributions from both language and vision modalities are aligned and non-conflicting. Consequently, focusing on blurring gender representations within the image encoder, which contributes most to the model bias, reduces bias efficiently by 22.03% and 9.04% in the MSCOCO and PASCAL-SENTENCE datasets, respectively, with minimal performance loss or increased computational demands.
Deep Learning Powered Estimate of The Extrinsic Parameters on Unmanned Surface Vehicles
Jun 07, 2024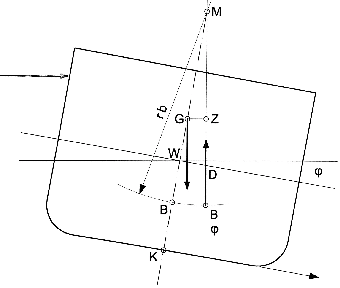



Unmanned Surface Vehicles (USVs) are pivotal in marine exploration, but their sensors' accuracy is compromised by the dynamic marine environment. Traditional calibration methods fall short in these conditions. This paper introduces a deep learning architecture that predicts changes in the USV's dynamic metacenter and refines sensors' extrinsic parameters in real time using a Time-Sequence General Regression Neural Network (GRNN) with Euler angles as input. Simulation data from Unity3D ensures robust training and testing. Experimental results show that the Time-Sequence GRNN achieves the lowest mean squared error (MSE) loss, outperforming traditional neural networks. This method significantly enhances sensor calibration for USVs, promising improved data accuracy in challenging maritime conditions. Future work will refine the network and validate results with real-world data.