 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup-Evolving Agents: Open-Ended Self-Improvement via Experience Sharing
Feb 04, 2026Open-ended self-improving agents can autonomously modify their own structural designs to advance their capabilities and overcome the limits of pre-defined architectures, thus reducing reliance on human intervention. We introduce Group-Evolving Agents (GEA), a new paradigm for open-ended self-improvements, which treats a group of agents as the fundamental evolutionary unit, enabling explicit experience sharing and reuse within the group throughout evolution. Unlike existing open-ended self-evolving paradigms that adopt tree-structured evolution, GEA overcomes the limitation of inefficient utilization of exploratory diversity caused by isolated evolutionary branches. We evaluate GEA on challenging coding benchmarks, where it significantly outperforms state-of-the-art self-evolving methods (71.0% vs. 56.7% on SWE-bench Verified, 88.3% vs. 68.3% on Polyglot) and matches or exceeds top human-designed agent frameworks (71.8% and 52.0% on two benchmarks, respectively). Analysis reveals that GEA more effectively converts early-stage exploratory diversity into sustained, long-term progress, achieving stronger performance under the same number of evolved agents. Furthermore, GEA exhibits consistent transferability across different coding models and greater robustness, fixing framework-level bugs in 1.4 iterations on average, versus 5 for self-evolving methods.
BIASINSPECTOR: Detecting Bias in Structured Data through LLM Agents
Apr 07, 2025Detecting biases in structured data is a complex and time-consuming task. Existing automated techniques are limited in diversity of data types and heavily reliant on human case-by-case handling, resulting in a lack of generalizability. Currently, large language model (LLM)-based agents have made significant progress in data science, but their ability to detect data biases is still insufficiently explored. To address this gap, we introduce the first end-to-end, multi-agent synergy framework, BIASINSPECTOR, designed for automatic bias detection in structured data based on specific user requirements. It first develops a multi-stage plan to analyze user-specified bias detection tasks and then implements it with a diverse and well-suited set of tools. It delivers detailed results that include explanations and visualizations. To address the lack of a standardized framework for evaluating the capability of LLM agents to detect biases in data, we further propose a comprehensive benchmark that includes multiple evaluation metrics and a large set of test cases. Extensive experiments demonstrate that our framework achieves exceptional overall performance in structured data bias detection, setting a new milestone for fairer data applications.
A Large-scale Empirical Study on Large Language Models for Election Prediction
Dec 19, 2024



Can Large Language Models (LLMs) accurately predict election outcomes? While LLMs have demonstrated impressive performance in healthcare, legal analysis, and creative applications, their capabilities in election forecasting remain uncertain. Notably, election prediction poses unique challenges: limited voter-level data, evolving political contexts, and the complexity of modeling human behavior. In the first part of this paper, we explore and introduce a multi-step reasoning framework for election prediction, which systematically integrates demographic, ideological, and time-sensitive factors. Validated on 2016 and 2020 real-world data and extensive synthetic personas, our approach adapts to changing political landscapes, reducing bias and significantly improving predictive accuracy. We further apply our pipeline to the 2024 U.S. presidential election, illustrating its ability to generalize beyond observed historical data. Beyond enhancing accuracy, the second part of the paper provides insights into the broader implications of LLM-based election forecasting. We identify potential political biases embedded in pretrained corpora, examine how demographic patterns can become exaggerated, and suggest strategies for mitigating these issues. Together, this project, a large-scale LLM empirical study, advances the accuracy of election predictions and establishes directions for more balanced, transparent, and context-aware modeling in political science research and practice.
Representation learning with CGAN for casual inference
Jul 03, 2024Conditional Generative Adversarial Nets (CGAN) is often used to improve conditional image generation performance. However, there is little research on Representation learning with CGAN for causal inference. This paper proposes a new method for finding representation learning functions by adopting the adversarial idea. We apply the pattern of CGAN and theoretically emonstrate the feasibility of finding a suitable representation function in the context of two distributions being balanced. The theoretical result shows that when two distributions are balanced, the ideal representation function can be found and thus can be used to further research.
* Proceedings of the 3rd International Conference on Signal Processing and Machine Learning
Images Speak Louder than Words: Understanding and Mitigating Bias in Vision-Language Model from a Causal Mediation Perspective
Jul 03, 2024
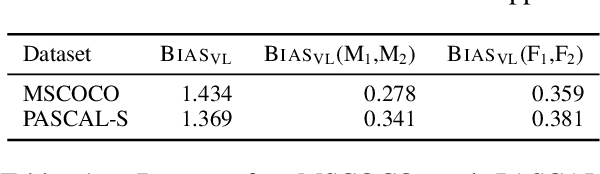

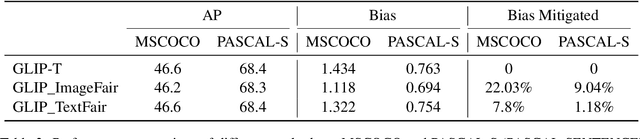
Vision-language models (VLMs) pre-trained on extensive datasets can inadvertently learn biases by correlating gender information with specific objects or scenarios. Current methods, which focus on modifying inputs and monitoring changes in the model's output probability scores, often struggle to comprehensively understand bias from the perspective of model components. We propose a framework that incorporates causal mediation analysis to measure and map the pathways of bias generation and propagation within VLMs. This approach allows us to identify the direct effects of interventions on model bias and the indirect effects of interventions on bias mediated through different model components. Our results show that image features are the primary contributors to bias, with significantly higher impacts than text features, specifically accounting for 32.57% and 12.63% of the bias in the MSCOCO and PASCAL-SENTENCE datasets, respectively. Notably, the image encoder's contribution surpasses that of the text encoder and the deep fusion encoder. Further experimentation confirms that contributions from both language and vision modalities are aligned and non-conflicting. Consequently, focusing on blurring gender representations within the image encoder, which contributes most to the model bias, reduces bias efficiently by 22.03% and 9.04% in the MSCOCO and PASCAL-SENTENCE datasets, respectively, with minimal performance loss or increased computational demands.
Online Open-set Semi-supervised Object Detection via Semi-supervised Outlier Filtering
May 23, 2023
Open-set semi-supervised object detection (OSSOD) methods aim to utilize practical unlabeled datasets with out-of-distribution (OOD) instances for object detection. The main challenge in OSSOD is distinguishing and filtering the OOD instances from the in-distribution (ID) instances during pseudo-labeling. The previous method uses an offline OOD detection network trained only with labeled data for solving this problem. However, the scarcity of available data limits the potential for improvement. Meanwhile, training separately leads to low efficiency. To alleviate the above issues, this paper proposes a novel end-to-end online framework that improves performance and efficiency by mining more valuable instances from unlabeled data. Specifically, we first propose a semi-supervised OOD detection strategy to mine valuable ID and OOD instances in unlabeled datasets for training. Then, we constitute an online end-to-end trainable OSSOD framework by integrating the OOD detection head into the object detector, making it jointly trainable with the original detection task. Our experimental results show that our method works well on several benchmarks, including the partially labeled COCO dataset with open-set classes and the fully labeled COCO dataset with the additional large-scale open-set unlabeled dataset, OpenImages. Compared with previous OSSOD methods, our approach achieves the best performance on COCO with OpenImages by +0.94 mAP, reaching 44.07 mAP.