 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDe-conflating Preference and Qualification: Constrained Dual-Perspective Reasoning for Job Recommendation with Large Language Models
Feb 03, 2026Professional job recommendation involves a complex bipartite matching process that must reconcile a candidate's subjective preference with an employer's objective qualification. While Large Language Models (LLMs) are well-suited for modeling the rich semantics of resumes and job descriptions, existing paradigms often collapse these two decision dimensions into a single interaction signal, yielding confounded supervision under recruitment-funnel censoring and limiting policy controllability. To address these challenges, We propose JobRec, a generative job recommendation framework for de-conflating preference and qualification via constrained dual-perspective reasoning. JobRec introduces a Unified Semantic Alignment Schema that aligns candidate and job attributes into structured semantic layers, and a Two-Stage Cooperative Training Strategy that learns decoupled experts to separately infer preference and qualification. Building on these experts, a Lagrangian-based Policy Alignment module optimizes recommendations under explicit eligibility requirements, enabling controllable trade-offs. To mitigate data scarcity, we construct a synthetic dataset refined by experts. Experiments show that JobRec consistently outperforms strong baselines and provides improved controllability for strategy-aware professional matching.
Multimodal Generative Engine Optimization: Rank Manipulation for Vision-Language Model Rankers
Jan 18, 2026Vision-Language Models (VLMs) are rapidly replacing unimodal encoders in modern retrieval and recommendation systems. While their capabilities are well-documented, their robustness against adversarial manipulation in competitive ranking scenarios remains largely unexplored. In this paper, we uncover a critical vulnerability in VLM-based product search: multimodal ranking attacks. We present Multimodal Generative Engine Optimization (MGEO), a novel adversarial framework that enables a malicious actor to unfairly promote a target product by jointly optimizing imperceptible image perturbations and fluent textual suffixes. Unlike existing attacks that treat modalities in isolation, MGEO employs an alternating gradient-based optimization strategy to exploit the deep cross-modal coupling within the VLM. Extensive experiments on real-world datasets using state-of-the-art models demonstrate that our coordinated attack significantly outperforms text-only and image-only baselines. These findings reveal that multimodal synergy, typically a strength of VLMs, can be weaponized to compromise the integrity of search rankings without triggering conventional content filters.
Defenses Against Prompt Attacks Learn Surface Heuristics
Jan 12, 2026Large language models (LLMs) are increasingly deployed in security-sensitive applications, where they must follow system- or developer-specified instructions that define the intended task behavior, while completing benign user requests. When adversarial instructions appear in user queries or externally retrieved content, models may override intended logic. Recent defenses rely on supervised fine-tuning with benign and malicious labels. Although these methods achieve high attack rejection rates, we find that they rely on narrow correlations in defense data rather than harmful intent, leading to systematic rejection of safe inputs. We analyze three recurring shortcut behaviors induced by defense fine-tuning. \emph{Position bias} arises when benign content placed later in a prompt is rejected at much higher rates; across reasoning benchmarks, suffix-task rejection rises from below \textbf{10\%} to as high as \textbf{90\%}. \emph{Token trigger bias} occurs when strings common in attack data raise rejection probability even in benign contexts; inserting a single trigger token increases false refusals by up to \textbf{50\%}. \emph{Topic generalization bias} reflects poor generalization beyond the defense data distribution, with defended models suffering test-time accuracy drops of up to \textbf{40\%}. These findings suggest that current prompt-injection defenses frequently respond to attack-like surface patterns rather than the underlying intent. We introduce controlled diagnostic datasets and a systematic evaluation across two base models and multiple defense pipelines, highlighting limitations of supervised fine-tuning for reliable LLM security.
Value-Action Alignment in Large Language Models under Privacy-Prosocial Conflict
Jan 07, 2026Large language models (LLMs) are increasingly used to simulate decision-making tasks involving personal data sharing, where privacy concerns and prosocial motivations can push choices in opposite directions. Existing evaluations often measure privacy-related attitudes or sharing intentions in isolation, which makes it difficult to determine whether a model's expressed values jointly predict its downstream data-sharing actions as in real human behaviors. We introduce a context-based assessment protocol that sequentially administers standardized questionnaires for privacy attitudes, prosocialness, and acceptance of data sharing within a bounded, history-carrying session. To evaluate value-action alignments under competing attitudes, we use multi-group structural equation modeling (MGSEM) to identify relations from privacy concerns and prosocialness to data sharing. We propose Value-Action Alignment Rate (VAAR), a human-referenced directional agreement metric that aggregates path-level evidence for expected signs. Across multiple LLMs, we observe stable but model-specific Privacy-PSA-AoDS profiles, and substantial heterogeneity in value-action alignment.
Realistic threat perception drives intergroup conflict: A causal, dynamic analysis using generative-agent simulations
Dec 18, 2025Human conflict is often attributed to threats against material conditions and symbolic values, yet it remains unclear how they interact and which dominates. Progress is limited by weak causal control, ethical constraints, and scarce temporal data. We address these barriers using simulations of large language model (LLM)-driven agents in virtual societies, independently varying realistic and symbolic threat while tracking actions, language, and attitudes. Representational analyses show that the underlying LLM encodes realistic threat, symbolic threat, and hostility as distinct internal states, that our manipulations map onto them, and that steering these states causally shifts behavior. Our simulations provide a causal account of threat-driven conflict over time: realistic threat directly increases hostility, whereas symbolic threat effects are weaker, fully mediated by ingroup bias, and increase hostility only when realistic threat is absent. Non-hostile intergroup contact buffers escalation, and structural asymmetries concentrate hostility among majority groups.
StealthRank: LLM Ranking Manipulation via Stealthy Prompt Optimization
Apr 08, 2025
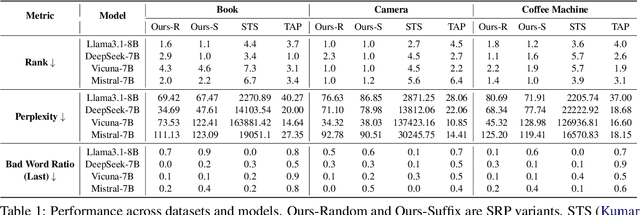


The integration of large language models (LLMs) into information retrieval systems introduces new attack surfaces, particularly for adversarial ranking manipulations. We present StealthRank, a novel adversarial ranking attack that manipulates LLM-driven product recommendation systems while maintaining textual fluency and stealth. Unlike existing methods that often introduce detectable anomalies, StealthRank employs an energy-based optimization framework combined with Langevin dynamics to generate StealthRank Prompts (SRPs)-adversarial text sequences embedded within product descriptions that subtly yet effectively influence LLM ranking mechanisms. We evaluate StealthRank across multiple LLMs, demonstrating its ability to covertly boost the ranking of target products while avoiding explicit manipulation traces that can be easily detected. Our results show that StealthRank consistently outperforms state-of-the-art adversarial ranking baselines in both effectiveness and stealth, highlighting critical vulnerabilities in LLM-driven recommendation systems.
A Large-scale Empirical Study on Large Language Models for Election Prediction
Dec 19, 2024



Can Large Language Models (LLMs) accurately predict election outcomes? While LLMs have demonstrated impressive performance in healthcare, legal analysis, and creative applications, their capabilities in election forecasting remain uncertain. Notably, election prediction poses unique challenges: limited voter-level data, evolving political contexts, and the complexity of modeling human behavior. In the first part of this paper, we explore and introduce a multi-step reasoning framework for election prediction, which systematically integrates demographic, ideological, and time-sensitive factors. Validated on 2016 and 2020 real-world data and extensive synthetic personas, our approach adapts to changing political landscapes, reducing bias and significantly improving predictive accuracy. We further apply our pipeline to the 2024 U.S. presidential election, illustrating its ability to generalize beyond observed historical data. Beyond enhancing accuracy, the second part of the paper provides insights into the broader implications of LLM-based election forecasting. We identify potential political biases embedded in pretrained corpora, examine how demographic patterns can become exaggerated, and suggest strategies for mitigating these issues. Together, this project, a large-scale LLM empirical study, advances the accuracy of election predictions and establishes directions for more balanced, transparent, and context-aware modeling in political science research and practice.
Political-LLM: Large Language Models in Political Science
Dec 09, 2024



In recent years, large language models (LLMs) have been widely adopted in political science tasks such as election prediction, sentiment analysis, policy impact assessment, and misinformation detection. Meanwhile, the need to systematically understand how LLMs can further revolutionize the field also becomes urgent. In this work, we--a multidisciplinary team of researchers spanning computer science and political science--present the first principled framework termed Political-LLM to advance the comprehensive understanding of integrating LLMs into computational political science. Specifically, we first introduce a fundamental taxonomy classifying the existing explorations into two perspectives: political science and computational methodologies. In particular, from the political science perspective, we highlight the role of LLMs in automating predictive and generative tasks, simulating behavior dynamics, and improving causal inference through tools like counterfactual generation; from a computational perspective, we introduce advancements in data preparation, fine-tuning, and evaluation methods for LLMs that are tailored to political contexts. We identify key challenges and future directions, emphasizing the development of domain-specific datasets, addressing issues of bias and fairness, incorporating human expertise, and redefining evaluation criteria to align with the unique requirements of computational political science. Political-LLM seeks to serve as a guidebook for researchers to foster an informed, ethical, and impactful use of Artificial Intelligence in political science. Our online resource is available at: http://political-llm.org/.