 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStealthRank: LLM Ranking Manipulation via Stealthy Prompt Optimization
Paper and Code

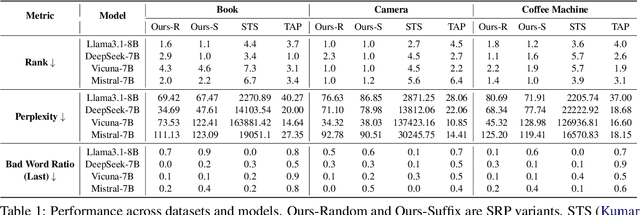


The integration of large language models (LLMs) into information retrieval systems introduces new attack surfaces, particularly for adversarial ranking manipulations. We present StealthRank, a novel adversarial ranking attack that manipulates LLM-driven product recommendation systems while maintaining textual fluency and stealth. Unlike existing methods that often introduce detectable anomalies, StealthRank employs an energy-based optimization framework combined with Langevin dynamics to generate StealthRank Prompts (SRPs)-adversarial text sequences embedded within product descriptions that subtly yet effectively influence LLM ranking mechanisms. We evaluate StealthRank across multiple LLMs, demonstrating its ability to covertly boost the ranking of target products while avoiding explicit manipulation traces that can be easily detected. Our results show that StealthRank consistently outperforms state-of-the-art adversarial ranking baselines in both effectiveness and stealth, highlighting critical vulnerabilities in LLM-driven recommendation systems.