 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Prompt Design for Socially Compliant Robot Navigation with Vision Language Models
Jan 21, 2026Language models are increasingly used for social robot navigation, yet existing benchmarks largely overlook principled prompt design for socially compliant behavior. This limitation is particularly relevant in practice, as many systems rely on small vision language models (VLMs) for efficiency. Compared to large language models, small VLMs exhibit weaker decision-making capabilities, making effective prompt design critical for accurate navigation. Inspired by cognitive theories of human learning and motivation, we study prompt design along two dimensions: system guidance (action-focused, reasoning-oriented, and perception-reasoning prompts) and motivational framing, where models compete against humans, other AI systems, or their past selves. Experiments on two socially compliant navigation datasets reveal three key findings. First, for non-finetuned GPT-4o, competition against humans achieves the best performance, while competition against other AI systems performs worst. For finetuned models, competition against the model's past self yields the strongest results, followed by competition against humans, with performance further influenced by coupling effects among prompt design, model choice, and dataset characteristics. Second, inappropriate system prompt design can significantly degrade performance, even compared to direct finetuning. Third, while direct finetuning substantially improves semantic-level metrics such as perception, prediction, and reasoning, it yields limited gains in action accuracy. In contrast, our system prompts produce a disproportionately larger improvement in action accuracy, indicating that the proposed prompt design primarily acts as a decision-level constraint rather than a representational enhancement.
MUSON: A Reasoning-oriented Multimodal Dataset for Socially Compliant Navigation in Urban Environments
Dec 28, 2025Socially compliant navigation requires structured reasoning over dynamic pedestrians and physical constraints to ensure safe and interpretable decisions. However, existing social navigation datasets often lack explicit reasoning supervision and exhibit highly long-tailed action distributions, limiting models' ability to learn safety-critical behaviors. To address these issues, we introduce MUSON, a multimodal dataset for short-horizon social navigation collected across diverse indoor and outdoor campus scenes. MUSON adopts a structured five-step Chain-of-Thought annotation consisting of perception, prediction, reasoning, action, and explanation, with explicit modeling of static physical constraints and a rationally balanced discrete action space. Compared to SNEI, MUSON provides consistent reasoning, action, and explanation. Benchmarking multiple state-of-the-art Small Vision Language Models on MUSON shows that Qwen2.5-VL-3B achieves the highest decision accuracy of 0.8625, demonstrating that MUSON serves as an effective and reusable benchmark for socially compliant navigation. The dataset is publicly available at https://huggingface.co/datasets/MARSLab/MUSON
MAction-SocialNav: Multi-Action Socially Compliant Navigation via Reasoning-enhanced Prompt Tuning
Dec 25, 2025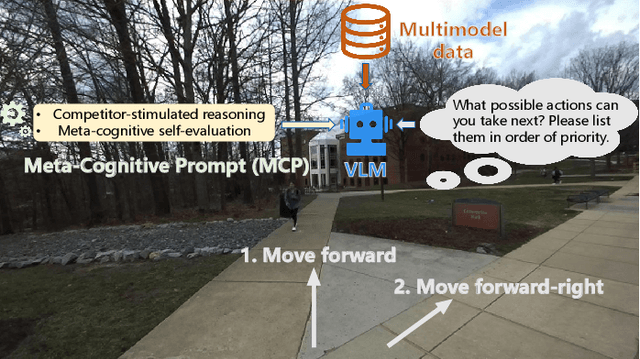
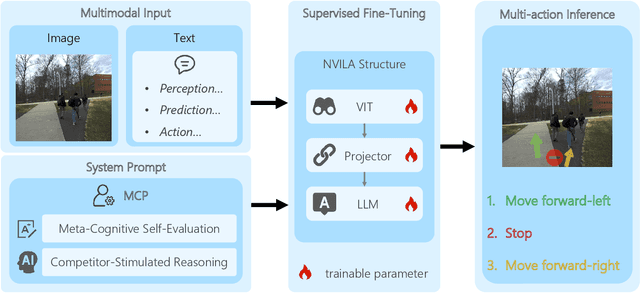


Socially compliant navigation requires robots to move safely and appropriately in human-centered environments by respecting social norms. However, social norms are often ambiguous, and in a single scenario, multiple actions may be equally acceptable. Most existing methods simplify this problem by assuming a single correct action, which limits their ability to handle real-world social uncertainty. In this work, we propose MAction-SocialNav, an efficient vision language model for socially compliant navigation that explicitly addresses action ambiguity, enabling generating multiple plausible actions within one scenario. To enhance the model's reasoning capability, we introduce a novel meta-cognitive prompt (MCP) method. Furthermore, to evaluate the proposed method, we curate a multi-action socially compliant navigation dataset that accounts for diverse conditions, including crowd density, indoor and outdoor environments, and dual human annotations. The dataset contains 789 samples, each with three-turn conversation, split into 710 training samples and 79 test samples through random selection. We also design five evaluation metrics to assess high-level decision precision, safety, and diversity. Extensive experiments demonstrate that the proposed MAction-SocialNav achieves strong social reasoning performance while maintaining high efficiency, highlighting its potential for real-world human robot navigation. Compared with zero-shot GPT-4o and Claude, our model achieves substantially higher decision quality (APG: 0.595 vs. 0.000/0.025) and safety alignment (ER: 0.264 vs. 0.642/0.668), while maintaining real-time efficiency (1.524 FPS, over 3x faster).
SocialNav-MoE: A Mixture-of-Experts Vision Language Model for Socially Compliant Navigation with Reinforcement Fine-Tuning
Dec 15, 2025For robots navigating in human-populated environments, safety and social compliance are equally critical, yet prior work has mostly emphasized safety. Socially compliant navigation that accounts for human comfort, social norms, and contextual appropriateness remains underexplored. Vision language models (VLMs) show promise for this task; however, large-scale models incur substantial computational overhead, leading to higher inference latency and energy consumption, which makes them unsuitable for real-time deployment on resource-constrained robotic platforms. To address this issue, we investigate the effectiveness of small VLM and propose SocialNav-MoE, an efficient Mixture-of-Experts vision language model for socially compliant navigation with reinforcement fine-tuning (RFT). We further introduce a semantic similarity reward (SSR) to effectively leverage RFT for enhancing the decision-making capabilities. Additionally, we study the effectiveness of different small language model types (Phi, Qwen, and StableLM), routing strategies, and vision encoders (CLIP vs. SigLIP, frozen vs. fine-tuned). Experiments on the SNEI dataset demonstrate that SocialNav-MoE achieves an excellent balance between navigation accuracy and efficiency. The proposed SSR function is more effective than hard-level and character-level rewards. Source code will be released upon acceptance.
A novel forecasting framework combining virtual samples and enhanced Transformer models for tourism demand forecasting
Mar 25, 2025Accurate tourism demand forecasting is hindered by limited historical data and complex spatiotemporal dependencies among tourist origins. A novel forecasting framework integrating virtual sample generation and a novel Transformer predictor addresses constraints arising from restricted data availability. A spatiotemporal GAN produces realistic virtual samples by dynamically modeling spatial correlations through a graph convolutional network, and an enhanced Transformer captures local patterns with causal convolutions and long-term dependencies with self-attention,eliminating autoregressive decoding. A joint training strategy refines virtual sample generation based on predictor feedback to maintain robust performance under data-scarce conditions. Experimental evaluations on real-world daily and monthly tourism demand datasets indicate a reduction in average MASE by 18.37% compared to conventional Transformer-based models, demonstrating improved forecasting accuracy. The integration of adaptive spatiotemporal sample augmentation with a specialized Transformer can effectively address limited-data forecasting scenarios in tourism management.
LLM-Advisor: An LLM Benchmark for Cost-efficient Path Planning across Multiple Terrains
Mar 03, 2025



Multi-terrain cost-efficient path planning is a crucial task in robot navigation, requiring the identification of a path from the start to the goal that not only avoids obstacles but also minimizes travel costs. This is especially crucial for real-world applications where robots need to navigate diverse terrains in outdoor environments, where recharging or refueling is difficult. However, there is very limited research on this topic. In this paper, we develop a prompt-based approach, LLM-Advisor, which leverages large language models (LLMs) as effective advisors for path planning. The LLM-Advisor selectively provides suggestions, demonstrating its ability to recognize when no modifications are necessary. When suggestions are made, 70.59% of the paths suggested for the A* algorithm, 69.47% for the RRT* algorithm, and 78.70% for the LLM-A* algorithm achieve greater cost efficiency. Since LLM-Advisor may occasionally lack common sense in their suggestions, we propose two hallucination-mitigation strategies. Furthermore, we experimentally verified that GPT-4o performs poorly in zero-shot path planning, even when terrain descriptions are clearly provided, demonstrating its low spatial awareness. We also experimentally demonstrate that using an LLM as an advisor is more effective than directly integrating it into the path-planning loop. Since LLMs may generate hallucinations, using LLMs in the loop of a search-based method (such as A*) may lead to a higher number of failed paths, demonstrating that our proposed LLM-Advisor is a better choice.
SCOMatch: Alleviating Overtrusting in Open-set Semi-supervised Learning
Sep 26, 2024



Open-set semi-supervised learning (OSSL) leverages practical open-set unlabeled data, comprising both in-distribution (ID) samples from seen classes and out-of-distribution (OOD) samples from unseen classes, for semi-supervised learning (SSL). Prior OSSL methods initially learned the decision boundary between ID and OOD with labeled ID data, subsequently employing self-training to refine this boundary. These methods, however, suffer from the tendency to overtrust the labeled ID data: the scarcity of labeled data caused the distribution bias between the labeled samples and the entire ID data, which misleads the decision boundary to overfit. The subsequent self-training process, based on the overfitted result, fails to rectify this problem. In this paper, we address the overtrusting issue by treating OOD samples as an additional class, forming a new SSL process. Specifically, we propose SCOMatch, a novel OSSL method that 1) selects reliable OOD samples as new labeled data with an OOD memory queue and a corresponding update strategy and 2) integrates the new SSL process into the original task through our Simultaneous Close-set and Open-set self-training. SCOMatch refines the decision boundary of ID and OOD classes across the entire dataset, thereby leading to improved results. Extensive experimental results show that SCOMatch significantly outperforms the state-of-the-art methods on various benchmarks. The effectiveness is further verified through ablation studies and visualization.
Language-Guided Self-Supervised Video Summarization Using Text Semantic Matching Considering the Diversity of the Video
May 14, 2024Current video summarization methods primarily depend on supervised computer vision techniques, which demands time-consuming manual annotations. Further, the annotations are always subjective which make this task more challenging. To address these issues, we analyzed the feasibility in transforming the video summarization into a text summary task and leverage Large Language Models (LLMs) to boost video summarization. This paper proposes a novel self-supervised framework for video summarization guided by LLMs. Our method begins by generating captions for video frames, which are then synthesized into text summaries by LLMs. Subsequently, we measure semantic distance between the frame captions and the text summary. It's worth noting that we propose a novel loss function to optimize our model according to the diversity of the video. Finally, the summarized video can be generated by selecting the frames whose captions are similar with the text summary. Our model achieves competitive results against other state-of-the-art methods and paves a novel pathway in video summarization.
Improving Plasticity in Online Continual Learning via Collaborative Learning
Dec 01, 2023Online Continual Learning (CL) solves the problem of learning the ever-emerging new classification tasks from a continuous data stream. Unlike its offline counterpart, in online CL, the training data can only be seen once. Most existing online CL research regards catastrophic forgetting (i.e., model stability) as almost the only challenge. In this paper, we argue that the model's capability to acquire new knowledge (i.e., model plasticity) is another challenge in online CL. While replay-based strategies have been shown to be effective in alleviating catastrophic forgetting, there is a notable gap in research attention toward improving model plasticity. To this end, we propose Collaborative Continual Learning (CCL), a collaborative learning based strategy to improve the model's capability in acquiring new concepts. Additionally, we introduce Distillation Chain (DC), a novel collaborative learning scheme to boost the training of the models. We adapted CCL-DC to existing representative online CL works. Extensive experiments demonstrate that even if the learners are well-trained with state-of-the-art online CL methods, our strategy can still improve model plasticity dramatically, and thereby improve the overall performance by a large margin.
Rethinking Momentum Knowledge Distillation in Online Continual Learning
Sep 06, 2023Online Continual Learning (OCL) addresses the problem of training neural networks on a continuous data stream where multiple classification tasks emerge in sequence. In contrast to offline Continual Learning, data can be seen only once in OCL. In this context, replay-based strategies have achieved impressive results and most state-of-the-art approaches are heavily depending on them. While Knowledge Distillation (KD) has been extensively used in offline Continual Learning, it remains under-exploited in OCL, despite its potential. In this paper, we theoretically analyze the challenges in applying KD to OCL. We introduce a direct yet effective methodology for applying Momentum Knowledge Distillation (MKD) to many flagship OCL methods and demonstrate its capabilities to enhance existing approaches. In addition to improving existing state-of-the-arts accuracy by more than $10\%$ points on ImageNet100, we shed light on MKD internal mechanics and impacts during training in OCL. We argue that similar to replay, MKD should be considered a central component of OCL.