 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Good Can Linear Models Be for Time-Series Forecasting?
Jun 25, 2026Time-series forecasting research has been moving steadily toward larger architectures, from specialized transformers to general-purpose foundation models, on the assumption that capacity is what unlocks accuracy. We take the opposite position: most of the gap can be closed at far lower cost by tuning preprocessing rather than scaling models. We use Ridge regression as the testbed, since it has a closed-form solution and interpretable weights, which let the optimal hyperparameters be read off the search directly. We search over context length, local normalization, regularization, and augmentation on eight standard benchmarks and find three patterns. (1) Optimal lookback is strongly series-specific and often non-monotonic in forecast horizon, with fitted power-law exponents ranging from $+0.46$ on ETTm2 to $-0.19$ on Exchange and Traffic, challenging the convention that longer horizons need longer history. (2) Normalizing over a learned trailing fraction of the context, rather than its entirety, is almost universally preferred. (3) Series within the same dataset often disagree on hyperparameters; the optimal degree of cross-series sharing varies from fully shared to fully per-series. The resulting models beat prior linear forecasters on most dataset-horizon entries and exceed Transformer, MLP, and CNN baselines on six of eight benchmarks. The optimized hyperparameters also serve as a diagnostic on the data itself, revealing structures that larger models absorb silently into their learned parameters.
Video-Mirai: Autoregressive Video Diffusion Models Need Foresight
Jun 02, 2026Causal video generators must predict from the past, but they need not learn only from it. In streaming autoregressive video diffusion, each emitted segment becomes a commitment that future segments must preserve. Standard training, however, only asks each causal state to explain the present. This creates what we call a representation-level planning gap: states that fit the current segment may discard identity, layout, and motion information needed for a consistent future. We introduce Video-Mirai, a training-only method that closes this gap without changing causal inference: the generator rolls out causally, a frozen foresight encoder reads the completed rollout non-causally, and a lightweight predictor distills the resulting stopped-gradient targets into causal states. Future frames supervise representations, never generator inputs. At inference, the encoder and predictor are discarded, leaving the original architecture, per-step FLOPs, and KV-cache behavior unchanged. Video-Mirai improves a strong Causal-Forcing baseline on 5-second VBench from 83.8 to 84.6 in terms of Total Score. On 30-second rollouts beyond the training horizon, subject consistency improves from 84.9 to 88.5 and background consistency from 90.2 to 91.9. Ablations identify future-conditioned targets as the key ingredient, and probes show that future frames become more decodable from current features. Causality should constrain inference, not representation supervision. Our study highlights that visual autoregressive models need foresight. Project page: https://y0uroy.github.io/Video-Mirai.
Mirai: Autoregressive Visual Generation Needs Foresight
Jan 21, 2026Autoregressive (AR) visual generators model images as sequences of discrete tokens and are trained with next token likelihood. This strict causality supervision optimizes each step only by its immediate next token, which diminishes global coherence and slows convergence. We ask whether foresight, training signals that originate from later tokens, can help AR visual generation. We conduct a series of controlled diagnostics along the injection level, foresight layout, and foresight source axes, unveiling a key insight: aligning foresight to AR models' internal representation on the 2D image grids improves causality modeling. We formulate this insight with Mirai (meaning "future" in Japanese), a general framework that injects future information into AR training with no architecture change and no extra inference overhead: Mirai-E uses explicit foresight from multiple future positions of unidirectional representations, whereas Mirai-I leverages implicit foresight from matched bidirectional representations. Extensive experiments show that Mirai significantly accelerates convergence and improves generation quality. For instance, Mirai can speed up LlamaGen-B's convergence by up to 10$\times$ and reduce the generation FID from 5.34 to 4.34 on the ImageNet class-condition image generation benchmark. Our study highlights that visual autoregressive models need foresight.
Joint Fusion and Encoding: Advancing Multimodal Retrieval from the Ground Up
Feb 27, 2025Information retrieval is indispensable for today's Internet applications, yet traditional semantic matching techniques often fall short in capturing the fine-grained cross-modal interactions required for complex queries. Although late-fusion two-tower architectures attempt to bridge this gap by independently encoding visual and textual data before merging them at a high level, they frequently overlook the subtle interplay essential for comprehensive understanding. In this work, we rigorously assess these limitations and introduce a unified retrieval framework that fuses visual and textual cues from the ground up, enabling early cross-modal interactions for enhancing context interpretation. Through a two-stage training process--comprising post-training adaptation followed by instruction tuning--we adapt MLLMs as retrievers using a simple one-tower architecture. Our approach outperforms conventional methods across diverse retrieval scenarios, particularly when processing complex multi-modal inputs. Notably, the joint fusion encoder yields greater improvements on tasks that require modality fusion compared to those that do not, underscoring the transformative potential of early integration strategies and pointing toward a promising direction for contextually aware and effective information retrieval.
SCOMatch: Alleviating Overtrusting in Open-set Semi-supervised Learning
Sep 26, 2024



Open-set semi-supervised learning (OSSL) leverages practical open-set unlabeled data, comprising both in-distribution (ID) samples from seen classes and out-of-distribution (OOD) samples from unseen classes, for semi-supervised learning (SSL). Prior OSSL methods initially learned the decision boundary between ID and OOD with labeled ID data, subsequently employing self-training to refine this boundary. These methods, however, suffer from the tendency to overtrust the labeled ID data: the scarcity of labeled data caused the distribution bias between the labeled samples and the entire ID data, which misleads the decision boundary to overfit. The subsequent self-training process, based on the overfitted result, fails to rectify this problem. In this paper, we address the overtrusting issue by treating OOD samples as an additional class, forming a new SSL process. Specifically, we propose SCOMatch, a novel OSSL method that 1) selects reliable OOD samples as new labeled data with an OOD memory queue and a corresponding update strategy and 2) integrates the new SSL process into the original task through our Simultaneous Close-set and Open-set self-training. SCOMatch refines the decision boundary of ID and OOD classes across the entire dataset, thereby leading to improved results. Extensive experimental results show that SCOMatch significantly outperforms the state-of-the-art methods on various benchmarks. The effectiveness is further verified through ablation studies and visualization.
FIIH: Fully Invertible Image Hiding for Secure and Robust
Jul 24, 2024



Image hiding is the study of techniques for covert storage and transmission, which embeds a secret image into a container image and generates stego image to make it similar in appearance to a normal image. However, existing image hiding methods have a serious problem that the hiding and revealing process cannot be fully invertible, which results in the revealing network not being able to recover the secret image losslessly, which makes it impossible to simultaneously achieve high fidelity and secure transmission of the secret image in an insecure network environment. To solve this problem,this paper proposes a fully invertible image hiding architecture based on invertible neural network,aiming to realize invertible hiding of secret images,which is invertible on both data and network. Based on this ingenious architecture, the method can withstand deep learning based image steganalysis. In addition, we propose a new method for enhancing the robustness of stego images after interference during transmission. Experiments demonstrate that the FIIH proposed in this paper significantly outperforms other state-of-the-art image hiding methods in hiding a single image, and also significantly outperforms other state-of-the-art methods in robustness and security.
Towards reporting bias in visual-language datasets: bimodal augmentation by decoupling object-attribute association
Oct 02, 2023



Reporting bias arises when people assume that some knowledge is universally understood and hence, do not necessitate explicit elaboration. In this paper, we focus on the wide existence of reporting bias in visual-language datasets, embodied as the object-attribute association, which can subsequentially degrade models trained on them. To mitigate this bias, we propose a bimodal augmentation (BiAug) approach through object-attribute decoupling to flexibly synthesize visual-language examples with a rich array of object-attribute pairing and construct cross-modal hard negatives. We employ large language models (LLMs) in conjunction with a grounding object detector to extract target objects. Subsequently, the LLM generates a detailed attribute description for each object and produces a corresponding hard negative counterpart. An inpainting model is then used to create images based on these detailed object descriptions. By doing so, the synthesized examples explicitly complement omitted objects and attributes to learn, and the hard negative pairs steer the model to distinguish object attributes. Our experiments demonstrated that BiAug is superior in object-attribute understanding. In addition, BiAug also improves the performance on zero-shot retrieval tasks on general benchmarks like MSCOCO and Flickr30K. BiAug refines the way of collecting text-image datasets. Mitigating the reporting bias helps models achieve a deeper understanding of visual-language phenomena, expanding beyond mere frequent patterns to encompass the richness and diversity of real-world scenarios.
CoNe: Contrast Your Neighbours for Supervised Image Classification
Aug 21, 2023



Image classification is a longstanding problem in computer vision and machine learning research. Most recent works (e.g. SupCon , Triplet, and max-margin) mainly focus on grouping the intra-class samples aggressively and compactly, with the assumption that all intra-class samples should be pulled tightly towards their class centers. However, such an objective will be very hard to achieve since it ignores the intra-class variance in the dataset. (i.e. different instances from the same class can have significant differences). Thus, such a monotonous objective is not sufficient. To provide a more informative objective, we introduce Contrast Your Neighbours (CoNe) - a simple yet practical learning framework for supervised image classification. Specifically, in CoNe, each sample is not only supervised by its class center but also directly employs the features of its similar neighbors as anchors to generate more adaptive and refined targets. Moreover, to further boost the performance, we propose ``distributional consistency" as a more informative regularization to enable similar instances to have a similar probability distribution. Extensive experimental results demonstrate that CoNe achieves state-of-the-art performance across different benchmark datasets, network architectures, and settings. Notably, even without a complicated training recipe, our CoNe achieves 80.8\% Top-1 accuracy on ImageNet with ResNet-50, which surpasses the recent Timm training recipe (80.4\%). Code and pre-trained models are available at \href{https://github.com/mingkai-zheng/CoNe}{https://github.com/mingkai-zheng/CoNe}.
SimMatchV2: Semi-Supervised Learning with Graph Consistency
Aug 13, 2023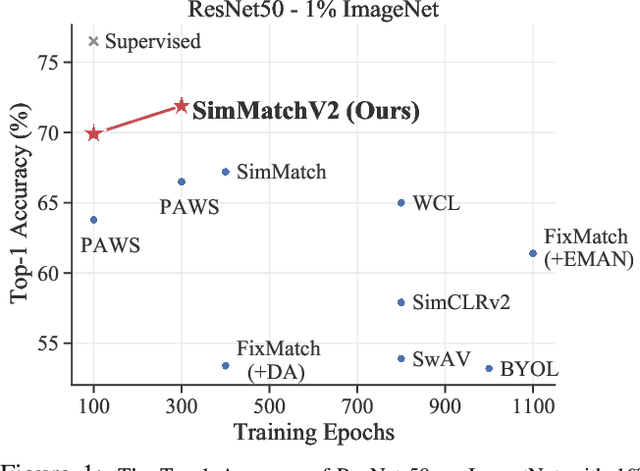
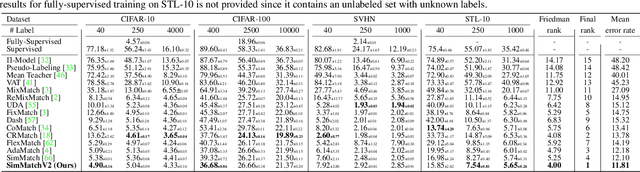
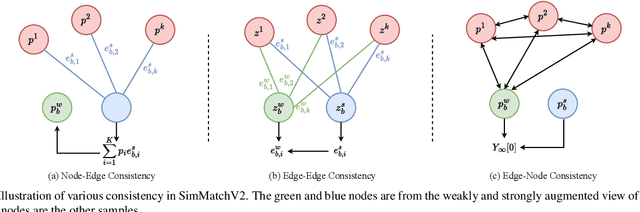
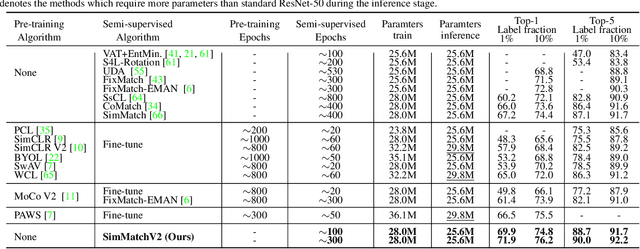
Semi-Supervised image classification is one of the most fundamental problem in computer vision, which significantly reduces the need for human labor. In this paper, we introduce a new semi-supervised learning algorithm - SimMatchV2, which formulates various consistency regularizations between labeled and unlabeled data from the graph perspective. In SimMatchV2, we regard the augmented view of a sample as a node, which consists of a label and its corresponding representation. Different nodes are connected with the edges, which are measured by the similarity of the node representations. Inspired by the message passing and node classification in graph theory, we propose four types of consistencies, namely 1) node-node consistency, 2) node-edge consistency, 3) edge-edge consistency, and 4) edge-node consistency. We also uncover that a simple feature normalization can reduce the gaps of the feature norm between different augmented views, significantly improving the performance of SimMatchV2. Our SimMatchV2 has been validated on multiple semi-supervised learning benchmarks. Notably, with ResNet-50 as our backbone and 300 epochs of training, SimMatchV2 achieves 71.9\% and 76.2\% Top-1 Accuracy with 1\% and 10\% labeled examples on ImageNet, which significantly outperforms the previous methods and achieves state-of-the-art performance. Code and pre-trained models are available at \href{https://github.com/mingkai-zheng/SimMatchV2}{https://github.com/mingkai-zheng/SimMatchV2}.
LightViT: Towards Light-Weight Convolution-Free Vision Transformers
Jul 12, 2022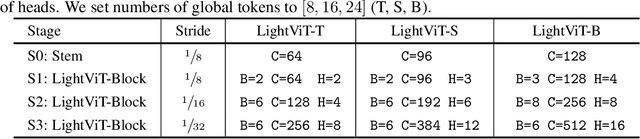
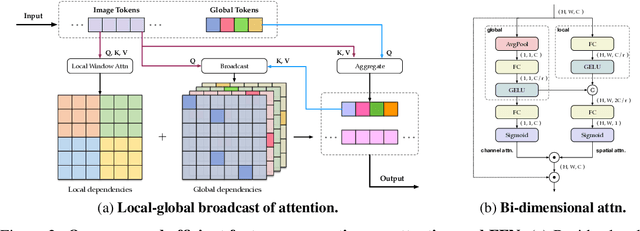
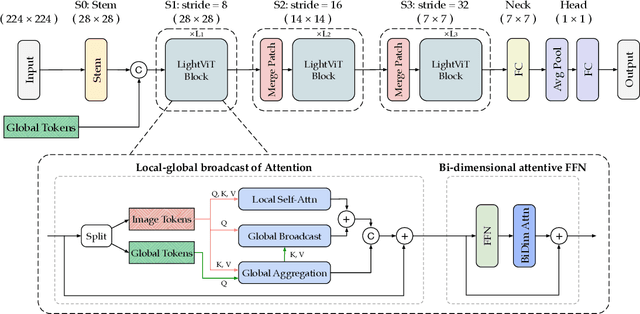
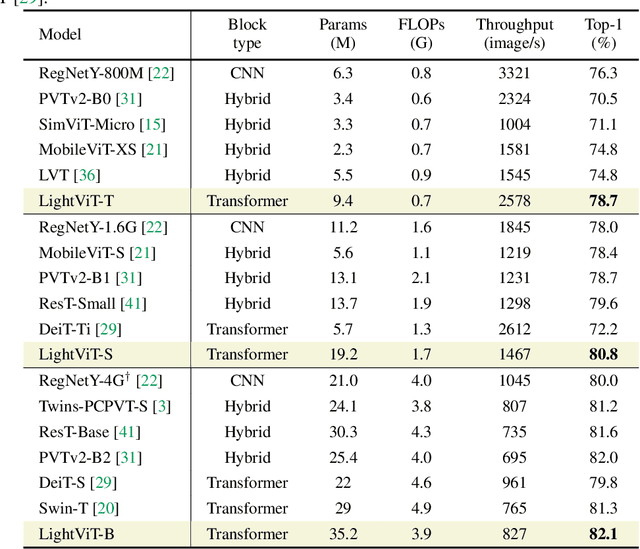
Vision transformers (ViTs) are usually considered to be less light-weight than convolutional neural networks (CNNs) due to the lack of inductive bias. Recent works thus resort to convolutions as a plug-and-play module and embed them in various ViT counterparts. In this paper, we argue that the convolutional kernels perform information aggregation to connect all tokens; however, they would be actually unnecessary for light-weight ViTs if this explicit aggregation could function in a more homogeneous way. Inspired by this, we present LightViT as a new family of light-weight ViTs to achieve better accuracy-efficiency balance upon the pure transformer blocks without convolution. Concretely, we introduce a global yet efficient aggregation scheme into both self-attention and feed-forward network (FFN) of ViTs, where additional learnable tokens are introduced to capture global dependencies; and bi-dimensional channel and spatial attentions are imposed over token embeddings. Experiments show that our model achieves significant improvements on image classification, object detection, and semantic segmentation tasks. For example, our LightViT-T achieves 78.7% accuracy on ImageNet with only 0.7G FLOPs, outperforming PVTv2-B0 by 8.2% while 11% faster on GPU. Code is available at https://github.com/hunto/LightViT.