 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Where to Learn in Cross-View Self-Supervised Learning
Paper and Code
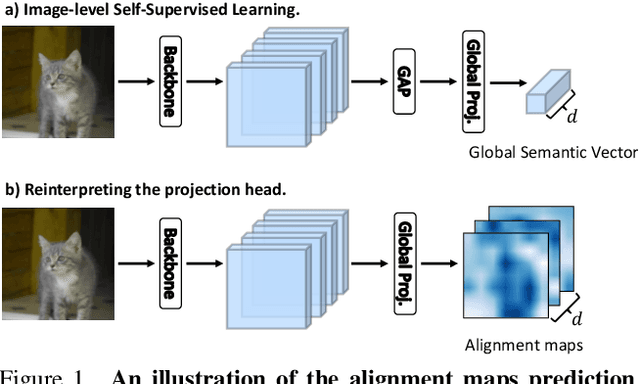
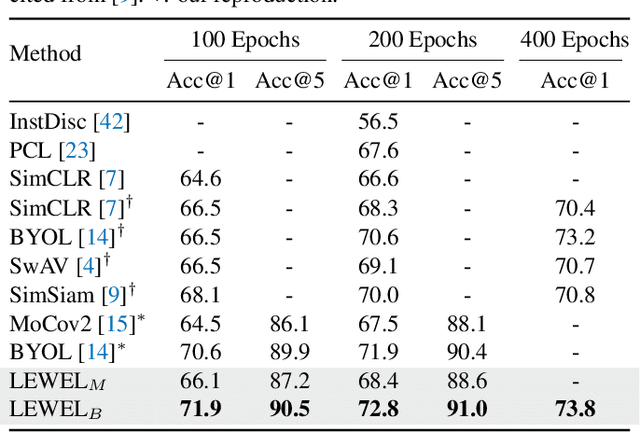
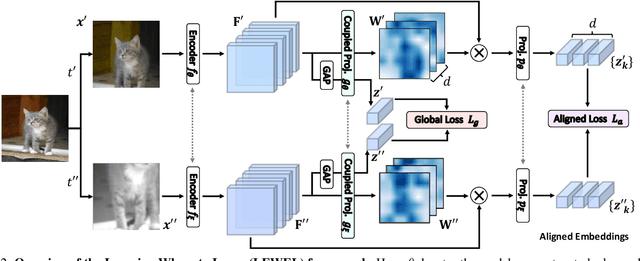
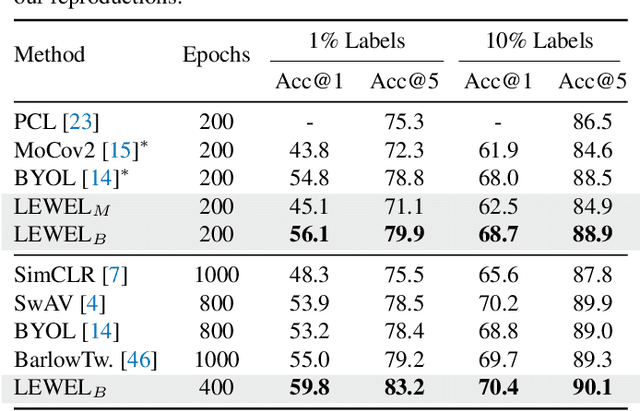
Self-supervised learning (SSL) has made enormous progress and largely narrowed the gap with the supervised ones, where the representation learning is mainly guided by a projection into an embedding space. During the projection, current methods simply adopt uniform aggregation of pixels for embedding; however, this risks involving object-irrelevant nuisances and spatial misalignment for different augmentations. In this paper, we present a new approach, Learning Where to Learn (LEWEL), to adaptively aggregate spatial information of features, so that the projected embeddings could be exactly aligned and thus guide the feature learning better. Concretely, we reinterpret the projection head in SSL as a per-pixel projection and predict a set of spatial alignment maps from the original features by this weight-sharing projection head. A spectrum of aligned embeddings is thus obtained by aggregating the features with spatial weighting according to these alignment maps. As a result of this adaptive alignment, we observe substantial improvements on both image-level prediction and dense prediction at the same time: LEWEL improves MoCov2 by 1.6%/1.3%/0.5%/0.4% points, improves BYOL by 1.3%/1.3%/0.7%/0.6% points, on ImageNet linear/semi-supervised classification, Pascal VOC semantic segmentation, and object detection, respectively.