 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAU: A Dual-Branch Network to Enhance Long-Tailed Recognition via Generative Models
Aug 29, 2024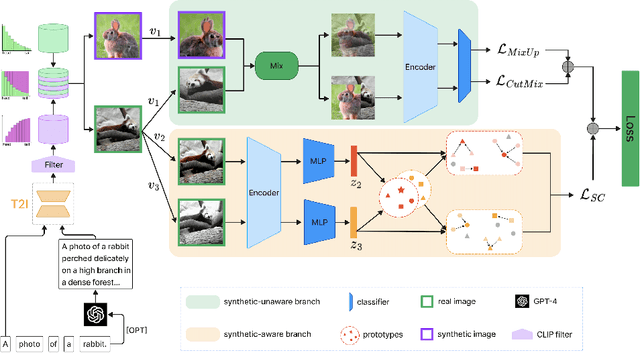
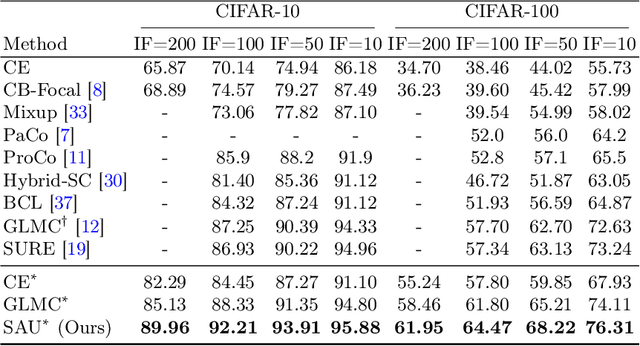
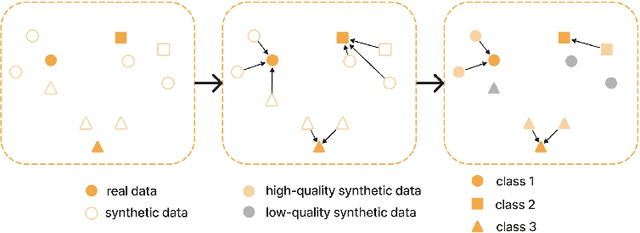
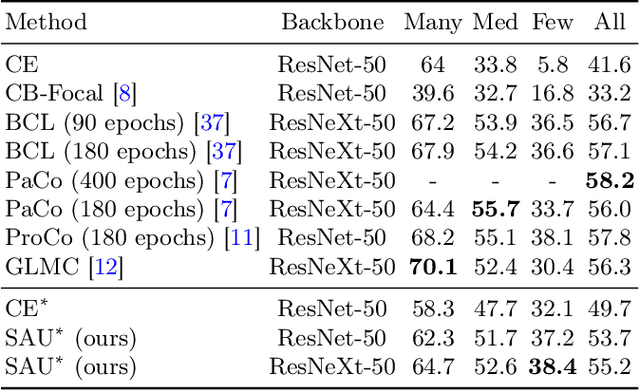
Long-tailed distributions in image recognition pose a considerable challenge due to the severe imbalance between a few dominant classes with numerous examples and many minority classes with few samples. Recently, the use of large generative models to create synthetic data for image classification has been realized, but utilizing synthetic data to address the challenge of long-tailed recognition remains relatively unexplored. In this work, we proposed the use of synthetic data as a complement to long-tailed datasets to eliminate the impact of data imbalance. To tackle this real-synthetic mixed dataset, we designed a two-branch model that contains Synthetic-Aware and Unaware branches (SAU). The core ideas are (1) a synthetic-unaware branch for classification that mixes real and synthetic data and treats all data equally without distinguishing between them. (2) A synthetic-aware branch for improving the robustness of the feature extractor by distinguishing between real and synthetic data and learning their discrepancies. Extensive experimental results demonstrate that our method can improve the accuracy of long-tailed image recognition. Notably, our approach achieves state-of-the-art Top-1 accuracy and significantly surpasses other methods on CIFAR-10-LT and CIFAR-100-LT datasets across various imbalance factors. Our code is available at https://github.com/lgX1123/gm4lt.
Training-free Long Video Generation with Chain of Diffusion Model Experts
Aug 27, 2024Video generation models hold substantial potential in areas such as filmmaking. However, current video diffusion models need high computational costs and produce suboptimal results due to high complexity of video generation task. In this paper, we propose \textbf{ConFiner}, an efficient high-quality video generation framework that decouples video generation into easier subtasks: structure \textbf{con}trol and spatial-temporal re\textbf{fine}ment. It can generate high-quality videos with chain of off-the-shelf diffusion model experts, each expert responsible for a decoupled subtask. During the refinement, we introduce coordinated denoising, which can merge multiple diffusion experts' capabilities into a single sampling. Furthermore, we design ConFiner-Long framework, which can generate long coherent video with three constraint strategies on ConFiner. Experimental results indicate that with only 10\% of the inference cost, our ConFiner surpasses representative models like Lavie and Modelscope across all objective and subjective metrics. And ConFiner-Long can generate high-quality and coherent videos with up to 600 frames.
CoNe: Contrast Your Neighbours for Supervised Image Classification
Aug 21, 2023



Image classification is a longstanding problem in computer vision and machine learning research. Most recent works (e.g. SupCon , Triplet, and max-margin) mainly focus on grouping the intra-class samples aggressively and compactly, with the assumption that all intra-class samples should be pulled tightly towards their class centers. However, such an objective will be very hard to achieve since it ignores the intra-class variance in the dataset. (i.e. different instances from the same class can have significant differences). Thus, such a monotonous objective is not sufficient. To provide a more informative objective, we introduce Contrast Your Neighbours (CoNe) - a simple yet practical learning framework for supervised image classification. Specifically, in CoNe, each sample is not only supervised by its class center but also directly employs the features of its similar neighbors as anchors to generate more adaptive and refined targets. Moreover, to further boost the performance, we propose ``distributional consistency" as a more informative regularization to enable similar instances to have a similar probability distribution. Extensive experimental results demonstrate that CoNe achieves state-of-the-art performance across different benchmark datasets, network architectures, and settings. Notably, even without a complicated training recipe, our CoNe achieves 80.8\% Top-1 accuracy on ImageNet with ResNet-50, which surpasses the recent Timm training recipe (80.4\%). Code and pre-trained models are available at \href{https://github.com/mingkai-zheng/CoNe}{https://github.com/mingkai-zheng/CoNe}.
SimMatchV2: Semi-Supervised Learning with Graph Consistency
Aug 13, 2023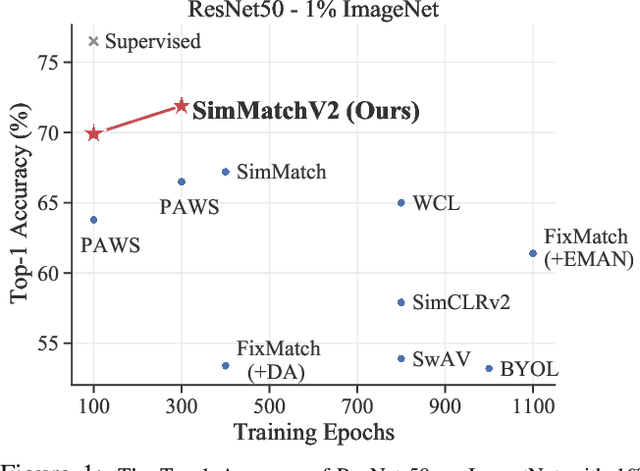
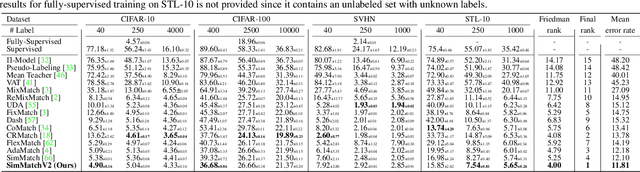
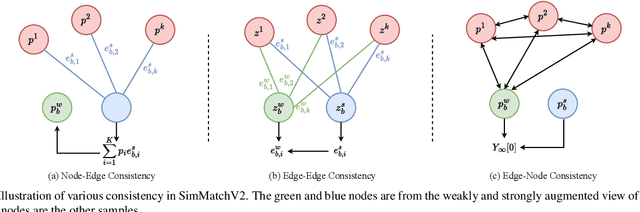
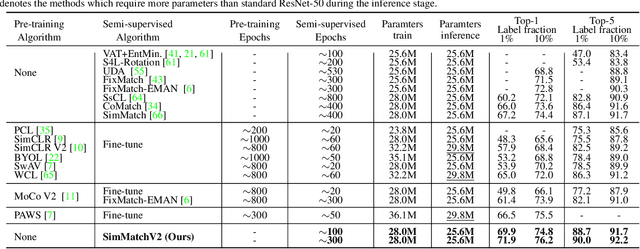
Semi-Supervised image classification is one of the most fundamental problem in computer vision, which significantly reduces the need for human labor. In this paper, we introduce a new semi-supervised learning algorithm - SimMatchV2, which formulates various consistency regularizations between labeled and unlabeled data from the graph perspective. In SimMatchV2, we regard the augmented view of a sample as a node, which consists of a label and its corresponding representation. Different nodes are connected with the edges, which are measured by the similarity of the node representations. Inspired by the message passing and node classification in graph theory, we propose four types of consistencies, namely 1) node-node consistency, 2) node-edge consistency, 3) edge-edge consistency, and 4) edge-node consistency. We also uncover that a simple feature normalization can reduce the gaps of the feature norm between different augmented views, significantly improving the performance of SimMatchV2. Our SimMatchV2 has been validated on multiple semi-supervised learning benchmarks. Notably, with ResNet-50 as our backbone and 300 epochs of training, SimMatchV2 achieves 71.9\% and 76.2\% Top-1 Accuracy with 1\% and 10\% labeled examples on ImageNet, which significantly outperforms the previous methods and achieves state-of-the-art performance. Code and pre-trained models are available at \href{https://github.com/mingkai-zheng/SimMatchV2}{https://github.com/mingkai-zheng/SimMatchV2}.
Knowledge Diffusion for Distillation
May 25, 2023The representation gap between teacher and student is an emerging topic in knowledge distillation (KD). To reduce the gap and improve the performance, current methods often resort to complicated training schemes, loss functions, and feature alignments, which are task-specific and feature-specific. In this paper, we state that the essence of these methods is to discard the noisy information and distill the valuable information in the feature, and propose a novel KD method dubbed DiffKD, to explicitly denoise and match features using diffusion models. Our approach is based on the observation that student features typically contain more noises than teacher features due to the smaller capacity of student model. To address this, we propose to denoise student features using a diffusion model trained by teacher features. This allows us to perform better distillation between the refined clean feature and teacher feature. Additionally, we introduce a light-weight diffusion model with a linear autoencoder to reduce the computation cost and an adpative noise matching module to improve the denoising performance. Extensive experiments demonstrate that DiffKD is effective across various types of features and achieves state-of-the-art performance consistently on image classification, object detection, and semantic segmentation tasks. Code will be available at https://github.com/hunto/DiffKD.
Can GPT-4 Perform Neural Architecture Search?
Apr 24, 2023

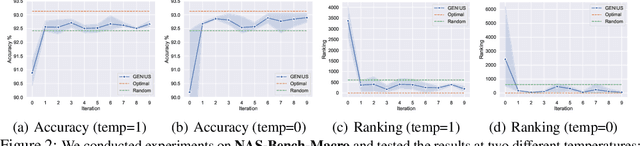

We investigate the potential of GPT-4~\cite{gpt4} to perform Neural Architecture Search (NAS) -- the task of designing effective neural architectures. Our proposed approach, \textbf{G}PT-4 \textbf{E}nhanced \textbf{N}eural arch\textbf{I}tect\textbf{U}re \textbf{S}earch (GENIUS), leverages the generative capabilities of GPT-4 as a black-box optimiser to quickly navigate the architecture search space, pinpoint promising candidates, and iteratively refine these candidates to improve performance. We assess GENIUS across several benchmarks, comparing it with existing state-of-the-art NAS techniques to illustrate its effectiveness. Rather than targeting state-of-the-art performance, our objective is to highlight GPT-4's potential to assist research on a challenging technical problem through a simple prompting scheme that requires relatively limited domain expertise\footnote{Code available at \href{https://github.com/mingkai-zheng/GENIUS}{https://github.com/mingkai-zheng/GENIUS}.}. More broadly, we believe our preliminary results point to future research that harnesses general purpose language models for diverse optimisation tasks. We also highlight important limitations to our study, and note implications for AI safety.
Boosting Semi-Supervised Semantic Segmentation with Probabilistic Representations
Oct 26, 2022
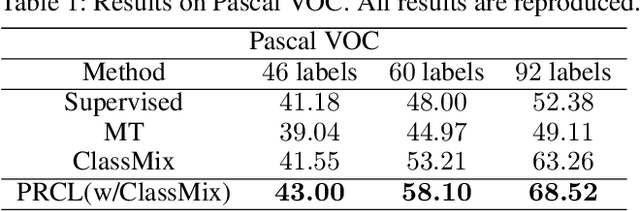
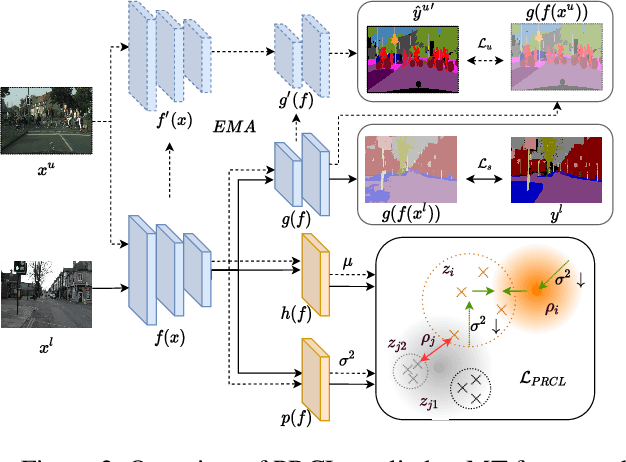
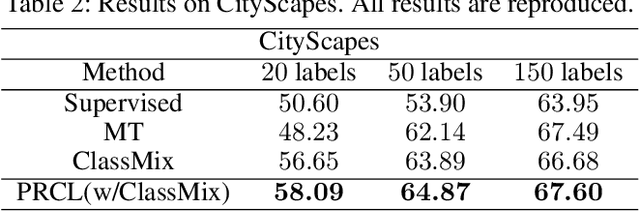
Recent breakthroughs in semi-supervised semantic segmentation have been developed through contrastive learning. In prevalent pixel-wise contrastive learning solutions, the model maps pixels to deterministic representations and regularizes them in the latent space. However, there exist inaccurate pseudo-labels which map the ambiguous representations of pixels to the wrong classes due to the limited cognitive ability of the model. In this paper, we define pixel-wise representations from a new perspective of probability theory and propose a Probabilistic Representation Contrastive Learning (PRCL) framework that improves representation quality by taking its probability into consideration. Through modeling the mapping from pixels to representations as the probability via multivariate Gaussian distributions, we can tune the contribution of the ambiguous representations to tolerate the risk of inaccurate pseudo-labels. Furthermore, we define prototypes in the form of distributions, which indicates the confidence of a class, while the point prototype cannot. Moreover, we propose to regularize the distribution variance to enhance the reliability of representations. Taking advantage of these benefits, high-quality feature representations can be derived in the latent space, thereby the performance of semantic segmentation can be further improved. We conduct sufficient experiment to evaluate PRCL on Pascal VOC and CityScapes. The comparisons with state-of-the-art approaches demonstrate the superiority of proposed PRCL.
Green Hierarchical Vision Transformer for Masked Image Modeling
May 26, 2022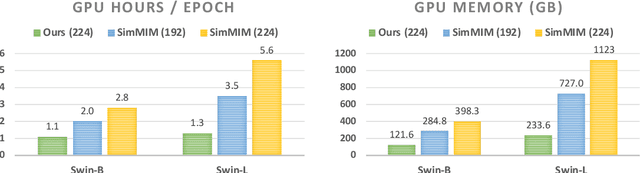
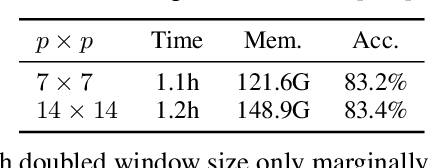
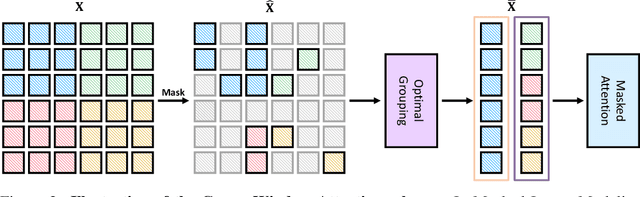
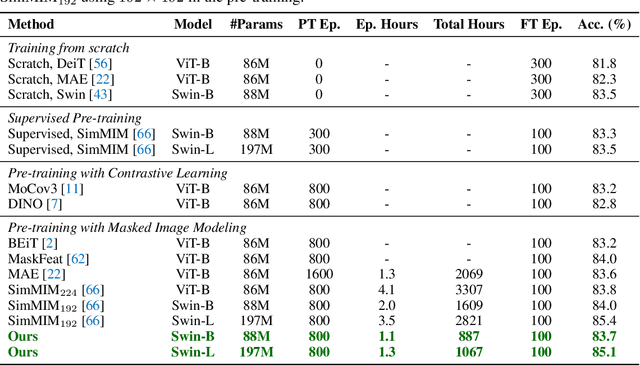
We present an efficient approach for Masked Image Modeling (MIM) with hierarchical Vision Transformers (ViTs), e.g., Swin Transformer, allowing the hierarchical ViTs to discard masked patches and operate only on the visible ones. Our approach consists of two key components. First, for the window attention, we design a Group Window Attention scheme following the Divide-and-Conquer strategy. To mitigate the quadratic complexity of the self-attention w.r.t. the number of patches, group attention encourages a uniform partition that visible patches within each local window of arbitrary size can be grouped with equal size, where masked self-attention is then performed within each group. Second, we further improve the grouping strategy via the Dynamic Programming algorithm to minimize the overall computation cost of the attention on the grouped patches. As a result, MIM now can work on hierarchical ViTs in a green and efficient way. For example, we can train the hierarchical ViTs about 2.7$\times$ faster and reduce the GPU memory usage by 70%, while still enjoying competitive performance on ImageNet classification and the superiority on downstream COCO object detection benchmarks. Code and pre-trained models have been made publicly available at https://github.com/LayneH/GreenMIM.
Learning Where to Learn in Cross-View Self-Supervised Learning
Mar 28, 2022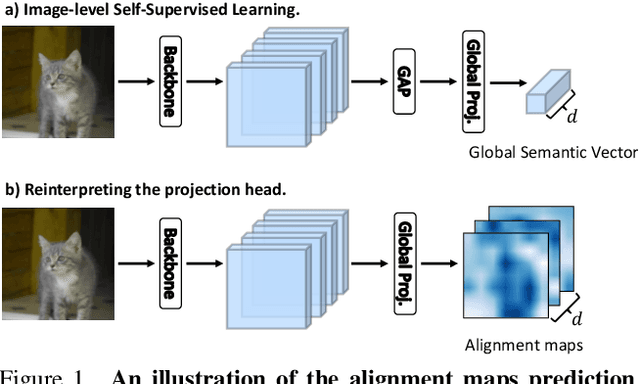
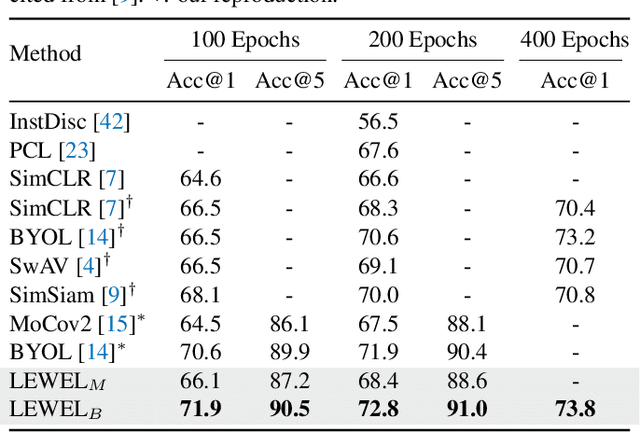
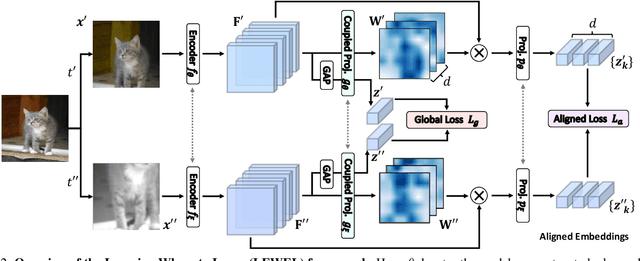
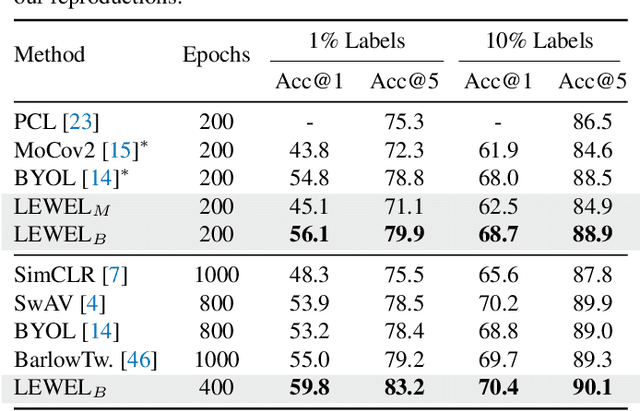
Self-supervised learning (SSL) has made enormous progress and largely narrowed the gap with the supervised ones, where the representation learning is mainly guided by a projection into an embedding space. During the projection, current methods simply adopt uniform aggregation of pixels for embedding; however, this risks involving object-irrelevant nuisances and spatial misalignment for different augmentations. In this paper, we present a new approach, Learning Where to Learn (LEWEL), to adaptively aggregate spatial information of features, so that the projected embeddings could be exactly aligned and thus guide the feature learning better. Concretely, we reinterpret the projection head in SSL as a per-pixel projection and predict a set of spatial alignment maps from the original features by this weight-sharing projection head. A spectrum of aligned embeddings is thus obtained by aggregating the features with spatial weighting according to these alignment maps. As a result of this adaptive alignment, we observe substantial improvements on both image-level prediction and dense prediction at the same time: LEWEL improves MoCov2 by 1.6%/1.3%/0.5%/0.4% points, improves BYOL by 1.3%/1.3%/0.7%/0.6% points, on ImageNet linear/semi-supervised classification, Pascal VOC semantic segmentation, and object detection, respectively.
SimMatch: Semi-supervised Learning with Similarity Matching
Mar 17, 2022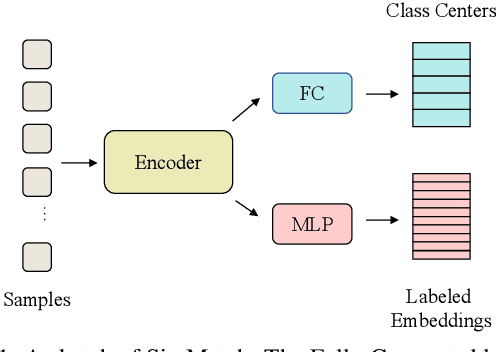
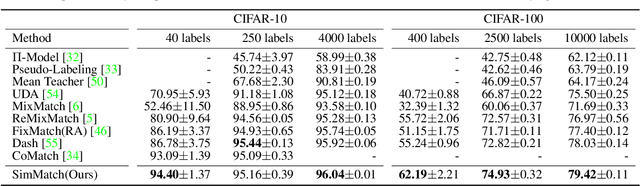
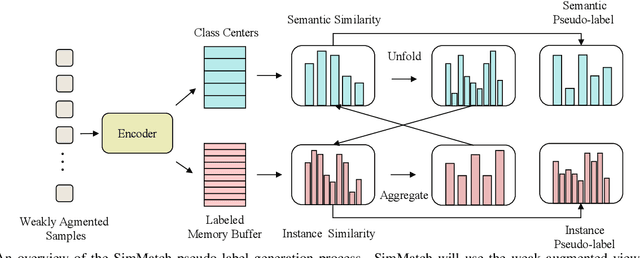
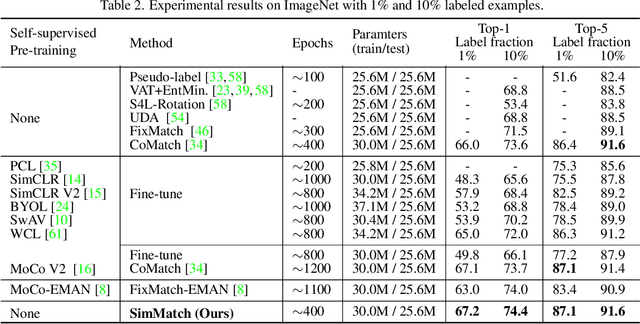
Learning with few labeled data has been a longstanding problem in the computer vision and machine learning research community. In this paper, we introduced a new semi-supervised learning framework, SimMatch, which simultaneously considers semantic similarity and instance similarity. In SimMatch, the consistency regularization will be applied on both semantic-level and instance-level. The different augmented views of the same instance are encouraged to have the same class prediction and similar similarity relationship respected to other instances. Next, we instantiated a labeled memory buffer to fully leverage the ground truth labels on instance-level and bridge the gaps between the semantic and instance similarities. Finally, we proposed the \textit{unfolding} and \textit{aggregation} operation which allows these two similarities be isomorphically transformed with each other. In this way, the semantic and instance pseudo-labels can be mutually propagated to generate more high-quality and reliable matching targets. Extensive experimental results demonstrate that SimMatch improves the performance of semi-supervised learning tasks across different benchmark datasets and different settings. Notably, with 400 epochs of training, SimMatch achieves 67.2\%, and 74.4\% Top-1 Accuracy with 1\% and 10\% labeled examples on ImageNet, which significantly outperforms the baseline methods and is better than previous semi-supervised learning frameworks. Code and pre-trained models are available at https://github.com/KyleZheng1997/simmatch.