 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAU: A Dual-Branch Network to Enhance Long-Tailed Recognition via Generative Models
Paper and Code
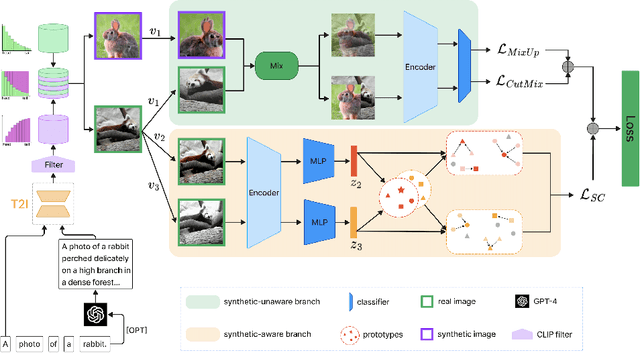
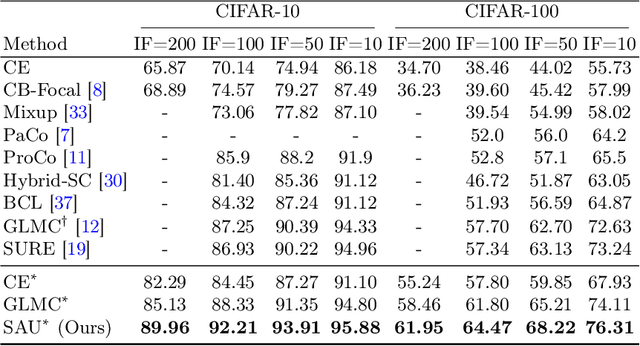
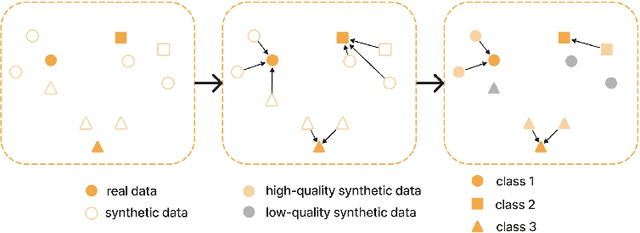
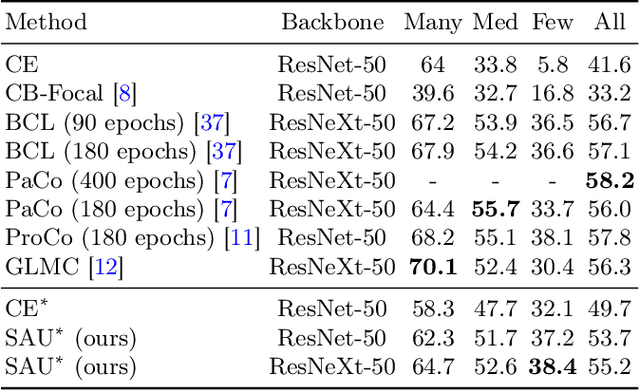
Long-tailed distributions in image recognition pose a considerable challenge due to the severe imbalance between a few dominant classes with numerous examples and many minority classes with few samples. Recently, the use of large generative models to create synthetic data for image classification has been realized, but utilizing synthetic data to address the challenge of long-tailed recognition remains relatively unexplored. In this work, we proposed the use of synthetic data as a complement to long-tailed datasets to eliminate the impact of data imbalance. To tackle this real-synthetic mixed dataset, we designed a two-branch model that contains Synthetic-Aware and Unaware branches (SAU). The core ideas are (1) a synthetic-unaware branch for classification that mixes real and synthetic data and treats all data equally without distinguishing between them. (2) A synthetic-aware branch for improving the robustness of the feature extractor by distinguishing between real and synthetic data and learning their discrepancies. Extensive experimental results demonstrate that our method can improve the accuracy of long-tailed image recognition. Notably, our approach achieves state-of-the-art Top-1 accuracy and significantly surpasses other methods on CIFAR-10-LT and CIFAR-100-LT datasets across various imbalance factors. Our code is available at https://github.com/lgX1123/gm4lt.