 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePKRD-CoT: A Unified Chain-of-thought Prompting for Multi-Modal Large Language Models in Autonomous Driving
Dec 02, 2024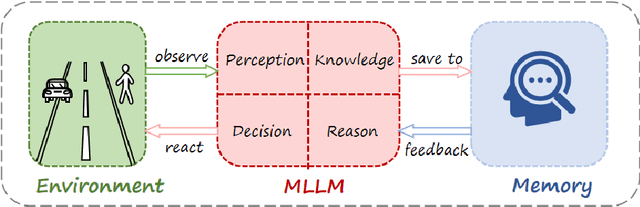


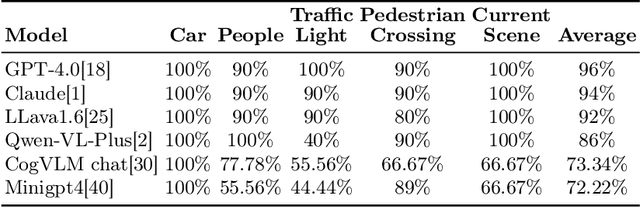
There is growing interest in leveraging the capabilities of robust Multi-Modal Large Language Models (MLLMs) directly within autonomous driving contexts. However, the high costs and complexity of designing and training end-to-end autonomous driving models make them challenging for many enterprises and research entities. To address this, our study explores a seamless integration of MLLMs into autonomous driving systems by proposing a Zero-Shot Chain-of-Thought (Zero-Shot-CoT) prompt design named PKRD-CoT. PKRD-CoT is based on the four fundamental capabilities of autonomous driving: perception, knowledge, reasoning, and decision-making. This makes it particularly suitable for understanding and responding to dynamic driving environments by mimicking human thought processes step by step, thus enhancing decision-making in real-time scenarios. Our design enables MLLMs to tackle problems without prior experience, thereby increasing their utility within unstructured autonomous driving environments. In experiments, we demonstrate the exceptional performance of GPT-4.0 with PKRD-CoT across autonomous driving tasks, highlighting its effectiveness in autonomous driving scenarios. Additionally, our benchmark analysis reveals the promising viability of PKRD-CoT for other MLLMs, such as Claude, LLava1.6, and Qwen-VL-Plus. Overall, this study contributes a novel and unified prompt-design framework for GPT-4.0 and other MLLMs in autonomous driving, while also rigorously evaluating the efficacy of these widely recognized MLLMs in the autonomous driving domain through comprehensive comparisons.
SAU: A Dual-Branch Network to Enhance Long-Tailed Recognition via Generative Models
Aug 29, 2024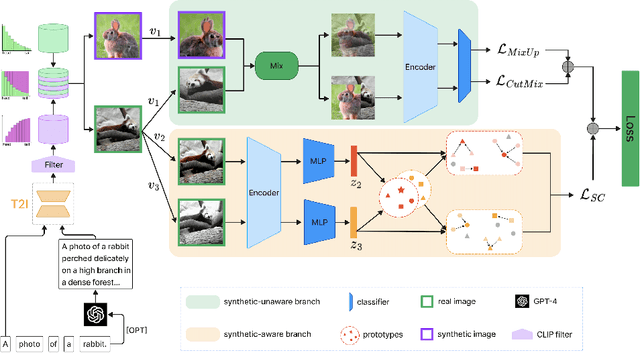
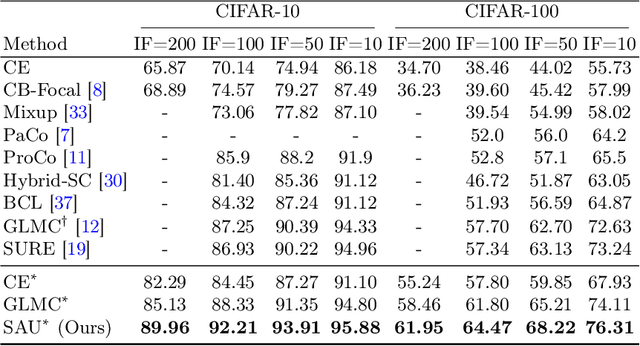
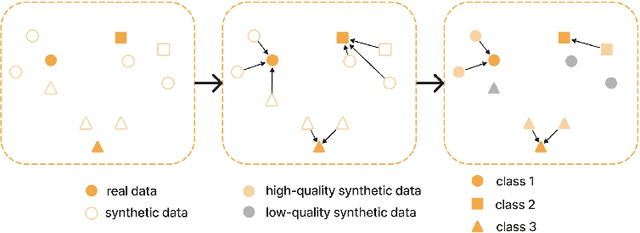
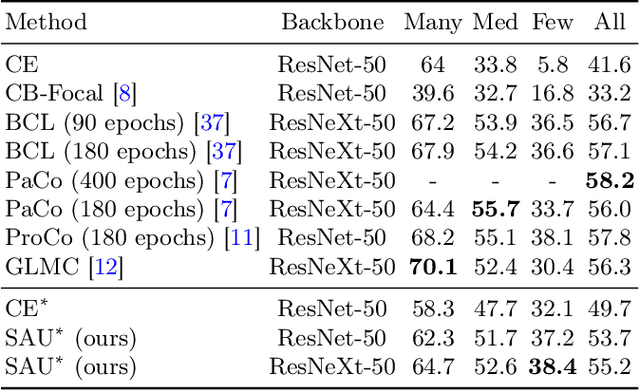
Long-tailed distributions in image recognition pose a considerable challenge due to the severe imbalance between a few dominant classes with numerous examples and many minority classes with few samples. Recently, the use of large generative models to create synthetic data for image classification has been realized, but utilizing synthetic data to address the challenge of long-tailed recognition remains relatively unexplored. In this work, we proposed the use of synthetic data as a complement to long-tailed datasets to eliminate the impact of data imbalance. To tackle this real-synthetic mixed dataset, we designed a two-branch model that contains Synthetic-Aware and Unaware branches (SAU). The core ideas are (1) a synthetic-unaware branch for classification that mixes real and synthetic data and treats all data equally without distinguishing between them. (2) A synthetic-aware branch for improving the robustness of the feature extractor by distinguishing between real and synthetic data and learning their discrepancies. Extensive experimental results demonstrate that our method can improve the accuracy of long-tailed image recognition. Notably, our approach achieves state-of-the-art Top-1 accuracy and significantly surpasses other methods on CIFAR-10-LT and CIFAR-100-LT datasets across various imbalance factors. Our code is available at https://github.com/lgX1123/gm4lt.