 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Models are Strong Learners for Multi-View Human Mesh Recovery
Mar 20, 2026Multi-view human mesh recovery (HMR) is broadly deployed in diverse domains where high accuracy and strong generalization are essential. Existing approaches can be broadly grouped into geometry-based and learning-based methods. However, geometry-based methods (e.g., triangulation) rely on cumbersome camera calibration, while learning-based approaches often generalize poorly to unseen camera configurations due to the lack of multi-view training data, limiting their performance in real-world scenarios. To enable calibration-free reconstruction that generalizes to arbitrary camera setups, we propose a training-free framework that leverages pretrained single-view HMR models as strong priors, eliminating the need for multi-view training data. Our method first constructs a robust and consistent multi-view initialization from single-view predictions, and then refines it via test-time optimization guided by multi-view consistency and anatomical constraints. Extensive experiments demonstrate state-of-the-art performance on standard benchmarks, surpassing multi-view models trained with explicit multi-view supervision.
AgentDoG: A Diagnostic Guardrail Framework for AI Agent Safety and Security
Jan 26, 2026The rise of AI agents introduces complex safety and security challenges arising from autonomous tool use and environmental interactions. Current guardrail models lack agentic risk awareness and transparency in risk diagnosis. To introduce an agentic guardrail that covers complex and numerous risky behaviors, we first propose a unified three-dimensional taxonomy that orthogonally categorizes agentic risks by their source (where), failure mode (how), and consequence (what). Guided by this structured and hierarchical taxonomy, we introduce a new fine-grained agentic safety benchmark (ATBench) and a Diagnostic Guardrail framework for agent safety and security (AgentDoG). AgentDoG provides fine-grained and contextual monitoring across agent trajectories. More Crucially, AgentDoG can diagnose the root causes of unsafe actions and seemingly safe but unreasonable actions, offering provenance and transparency beyond binary labels to facilitate effective agent alignment. AgentDoG variants are available in three sizes (4B, 7B, and 8B parameters) across Qwen and Llama model families. Extensive experimental results demonstrate that AgentDoG achieves state-of-the-art performance in agentic safety moderation in diverse and complex interactive scenarios. All models and datasets are openly released.
Language Model Based Text-to-Audio Generation: Anti-Causally Aligned Collaborative Residual Transformers
Oct 06, 2025While language models (LMs) paired with residual vector quantization (RVQ) tokenizers have shown promise in text-to-audio (T2A) generation, they still lag behind diffusion-based models by a non-trivial margin. We identify a critical dilemma underpinning this gap: incorporating more RVQ layers improves audio reconstruction fidelity but exceeds the generation capacity of conventional LMs. To address this, we first analyze RVQ dynamics and uncover two key limitations: 1) orthogonality of features across RVQ layers hinders effective LMs training, and 2) descending semantic richness in tokens from deeper RVQ layers exacerbates exposure bias during autoregressive decoding. Based on these insights, we propose Siren, a novel LM-based framework that employs multiple isolated transformers with causal conditioning and anti-causal alignment via reinforcement learning. Extensive experiments demonstrate that Siren outperforms both existing LM-based and diffusion-based T2A systems, achieving state-of-the-art results. By bridging the representational strengths of LMs with the fidelity demands of audio synthesis, our approach repositions LMs as competitive contenders against diffusion models in T2A tasks. Moreover, by aligning audio representations with linguistic structures, Siren facilitates a promising pathway toward unified multi-modal generation frameworks.
Decomposing and Fusing Intra- and Inter-Sensor Spatio-Temporal Signal for Multi-Sensor Wearable Human Activity Recognition
Jan 19, 2025



Wearable Human Activity Recognition (WHAR) is a prominent research area within ubiquitous computing. Multi-sensor synchronous measurement has proven to be more effective for WHAR than using a single sensor. However, existing WHAR methods use shared convolutional kernels for indiscriminate temporal feature extraction across each sensor variable, which fails to effectively capture spatio-temporal relationships of intra-sensor and inter-sensor variables. We propose the DecomposeWHAR model consisting of a decomposition phase and a fusion phase to better model the relationships between modality variables. The decomposition creates high-dimensional representations of each intra-sensor variable through the improved Depth Separable Convolution to capture local temporal features while preserving their unique characteristics. The fusion phase begins by capturing relationships between intra-sensor variables and fusing their features at both the channel and variable levels. Long-range temporal dependencies are modeled using the State Space Model (SSM), and later cross-sensor interactions are dynamically captured through a self-attention mechanism, highlighting inter-sensor spatial correlations. Our model demonstrates superior performance on three widely used WHAR datasets, significantly outperforming state-of-the-art models while maintaining acceptable computational efficiency. Our codes and supplementary materials are available at https://github.com/Anakin2555/DecomposeWHAR.
FaceChain-FACT: Face Adapter with Decoupled Training for Identity-preserved Personalization
Oct 16, 2024



In the field of human-centric personalized image generation, the adapter-based method obtains the ability to customize and generate portraits by text-to-image training on facial data. This allows for identity-preserved personalization without additional fine-tuning in inference. Although there are improvements in efficiency and fidelity, there is often a significant performance decrease in test following ability, controllability, and diversity of generated faces compared to the base model. In this paper, we analyze that the performance degradation is attributed to the failure to decouple identity features from other attributes during extraction, as well as the failure to decouple the portrait generation training from the overall generation task. To address these issues, we propose the Face Adapter with deCoupled Training (FACT) framework, focusing on both model architecture and training strategy. To decouple identity features from others, we leverage a transformer-based face-export encoder and harness fine-grained identity features. To decouple the portrait generation training, we propose Face Adapting Increment Regularization~(FAIR), which effectively constrains the effect of face adapters on the facial region, preserving the generative ability of the base model. Additionally, we incorporate a face condition drop and shuffle mechanism, combined with curriculum learning, to enhance facial controllability and diversity. As a result, FACT solely learns identity preservation from training data, thereby minimizing the impact on the original text-to-image capabilities of the base model. Extensive experiments show that FACT has both controllability and fidelity in both text-to-image generation and inpainting solutions for portrait generation.
TopoFR: A Closer Look at Topology Alignment on Face Recognition
Oct 14, 2024



The field of face recognition (FR) has undergone significant advancements with the rise of deep learning. Recently, the success of unsupervised learning and graph neural networks has demonstrated the effectiveness of data structure information. Considering that the FR task can leverage large-scale training data, which intrinsically contains significant structure information, we aim to investigate how to encode such critical structure information into the latent space. As revealed from our observations, directly aligning the structure information between the input and latent spaces inevitably suffers from an overfitting problem, leading to a structure collapse phenomenon in the latent space. To address this problem, we propose TopoFR, a novel FR model that leverages a topological structure alignment strategy called PTSA and a hard sample mining strategy named SDE. Concretely, PTSA uses persistent homology to align the topological structures of the input and latent spaces, effectively preserving the structure information and improving the generalization performance of FR model. To mitigate the impact of hard samples on the latent space structure, SDE accurately identifies hard samples by automatically computing structure damage score (SDS) for each sample, and directs the model to prioritize optimizing these samples. Experimental results on popular face benchmarks demonstrate the superiority of our TopoFR over the state-of-the-art methods. Code and models are available at: https://github.com/modelscope/facechain/tree/main/face_module/TopoFR.
Large-scale Outdoor Cell-free mMIMO Channel Measurement in an Urban Scenario at 3.5 GHz
May 31, 2024
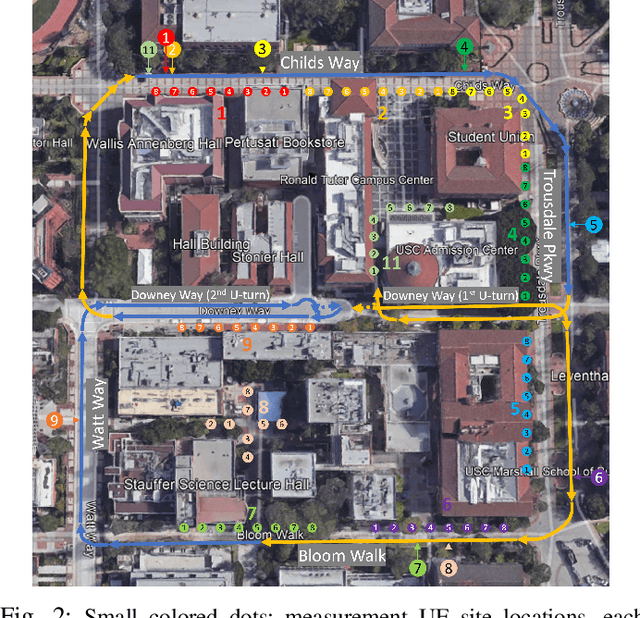


The design of cell-free massive MIMO (CF-mMIMO) systems requires accurate, measurement-based channel models. This paper provides the first results from the by far most extensive outdoor measurement campaign for CF-mMIMO channels in an urban environment. We measured impulse responses between over 20,000 potential access point (AP) locations and 80 user equipments (UEs) at 3.5 GHz with 350 MHz bandwidth (BW). Measurements use a "virtual array" approach at the AP and a hybrid switched/virtual approach at the UE. This paper describes the sounder design, measurement environment, data processing, and sample results, particularly the evolution of the power-delay profiles (PDPs) as a function of the AP locations, and its relation to the propagation environment.
PRCL: Probabilistic Representation Contrastive Learning for Semi-Supervised Semantic Segmentation
Feb 28, 2024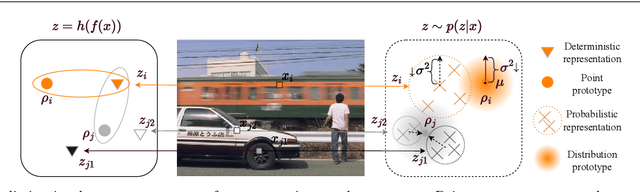
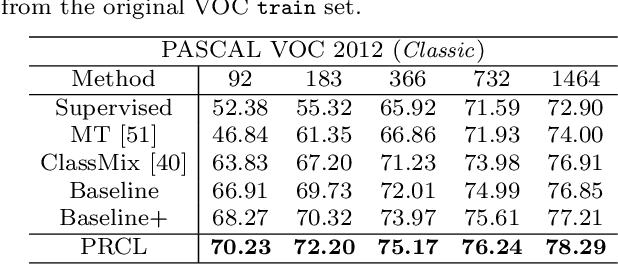
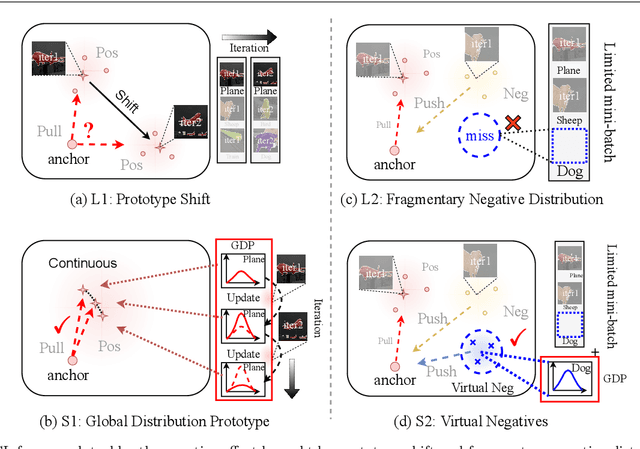
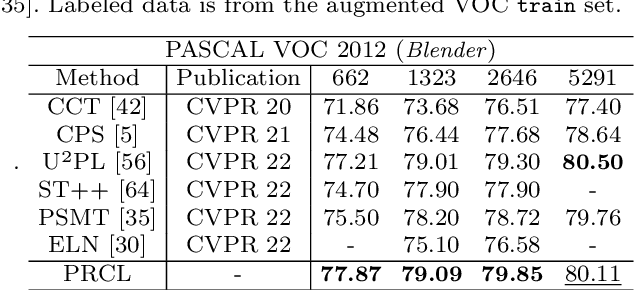
Tremendous breakthroughs have been developed in Semi-Supervised Semantic Segmentation (S4) through contrastive learning. However, due to limited annotations, the guidance on unlabeled images is generated by the model itself, which inevitably exists noise and disturbs the unsupervised training process. To address this issue, we propose a robust contrastive-based S4 framework, termed the Probabilistic Representation Contrastive Learning (PRCL) framework to enhance the robustness of the unsupervised training process. We model the pixel-wise representation as Probabilistic Representations (PR) via multivariate Gaussian distribution and tune the contribution of the ambiguous representations to tolerate the risk of inaccurate guidance in contrastive learning. Furthermore, we introduce Global Distribution Prototypes (GDP) by gathering all PRs throughout the whole training process. Since the GDP contains the information of all representations with the same class, it is robust from the instant noise in representations and bears the intra-class variance of representations. In addition, we generate Virtual Negatives (VNs) based on GDP to involve the contrastive learning process. Extensive experiments on two public benchmarks demonstrate the superiority of our PRCL framework.
LiDAR-based 4D Occupancy Completion and Forecasting
Oct 17, 2023
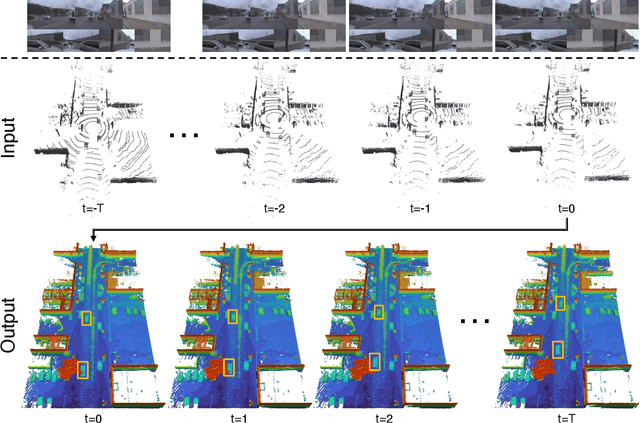
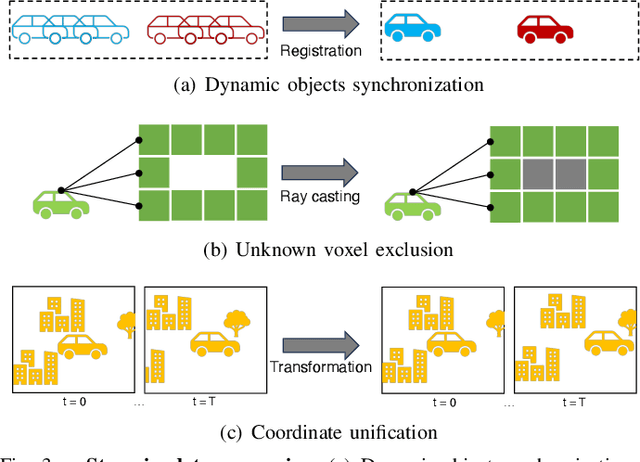
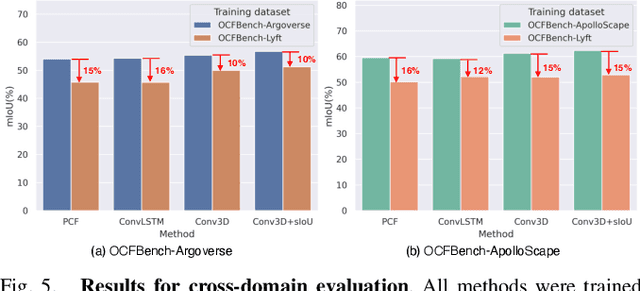
Scene completion and forecasting are two popular perception problems in research for mobile agents like autonomous vehicles. Existing approaches treat the two problems in isolation, resulting in a separate perception of the two aspects. In this paper, we introduce a novel LiDAR perception task of Occupancy Completion and Forecasting (OCF) in the context of autonomous driving to unify these aspects into a cohesive framework. This task requires new algorithms to address three challenges altogether: (1) sparse-to-dense reconstruction, (2) partial-to-complete hallucination, and (3) 3D-to-4D prediction. To enable supervision and evaluation, we curate a large-scale dataset termed OCFBench from public autonomous driving datasets. We analyze the performance of closely related existing baseline models and our own ones on our dataset. We envision that this research will inspire and call for further investigation in this evolving and crucial area of 4D perception. Our code for data curation and baseline implementation is available at https://github.com/ai4ce/Occ4cast.
FaceChain: A Playground for Identity-Preserving Portrait Generation
Aug 28, 2023



Recent advancement in personalized image generation have unveiled the intriguing capability of pre-trained text-to-image models on learning identity information from a collection of portrait images. However, existing solutions can be vulnerable in producing truthful details, and usually suffer from several defects such as (i) The generated face exhibit its own unique characteristics, \ie facial shape and facial feature positioning may not resemble key characteristics of the input, and (ii) The synthesized face may contain warped, blurred or corrupted regions. In this paper, we present FaceChain, a personalized portrait generation framework that combines a series of customized image-generation model and a rich set of face-related perceptual understanding models (\eg, face detection, deep face embedding extraction, and facial attribute recognition), to tackle aforementioned challenges and to generate truthful personalized portraits, with only a handful of portrait images as input. Concretely, we inject several SOTA face models into the generation procedure, achieving a more efficient label-tagging, data-processing, and model post-processing compared to previous solutions, such as DreamBooth ~\cite{ruiz2023dreambooth} , InstantBooth ~\cite{shi2023instantbooth} , or other LoRA-only approaches ~\cite{hu2021lora} . Through the development of FaceChain, we have identified several potential directions to accelerate development of Face/Human-Centric AIGC research and application. We have designed FaceChain as a framework comprised of pluggable components that can be easily adjusted to accommodate different styles and personalized needs. We hope it can grow to serve the burgeoning needs from the communities. FaceChain is open-sourced under Apache-2.0 license at \url{https://github.com/modelscope/facechain}.