 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRCL: Probabilistic Representation Contrastive Learning for Semi-Supervised Semantic Segmentation
Feb 28, 2024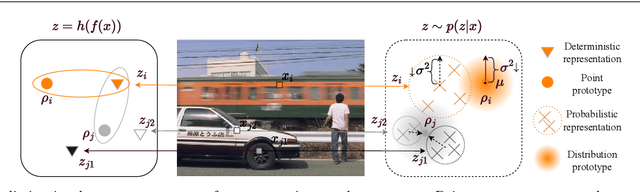
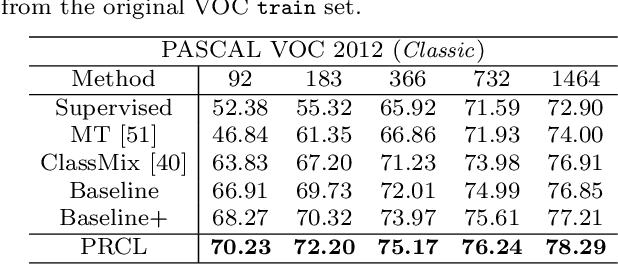
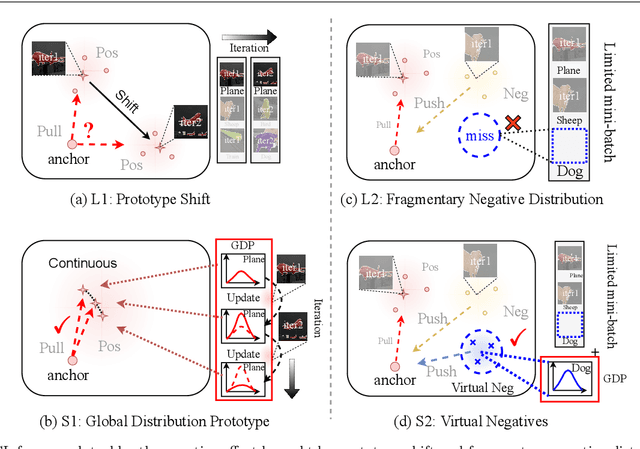
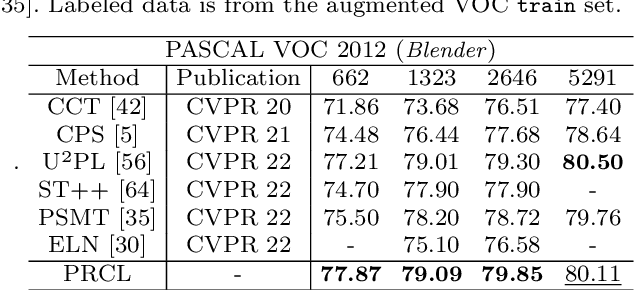
Tremendous breakthroughs have been developed in Semi-Supervised Semantic Segmentation (S4) through contrastive learning. However, due to limited annotations, the guidance on unlabeled images is generated by the model itself, which inevitably exists noise and disturbs the unsupervised training process. To address this issue, we propose a robust contrastive-based S4 framework, termed the Probabilistic Representation Contrastive Learning (PRCL) framework to enhance the robustness of the unsupervised training process. We model the pixel-wise representation as Probabilistic Representations (PR) via multivariate Gaussian distribution and tune the contribution of the ambiguous representations to tolerate the risk of inaccurate guidance in contrastive learning. Furthermore, we introduce Global Distribution Prototypes (GDP) by gathering all PRs throughout the whole training process. Since the GDP contains the information of all representations with the same class, it is robust from the instant noise in representations and bears the intra-class variance of representations. In addition, we generate Virtual Negatives (VNs) based on GDP to involve the contrastive learning process. Extensive experiments on two public benchmarks demonstrate the superiority of our PRCL framework.
Space Engage: Collaborative Space Supervision for Contrastive-based Semi-Supervised Semantic Segmentation
Jul 19, 2023
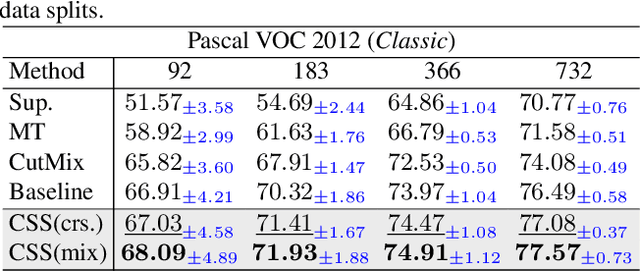

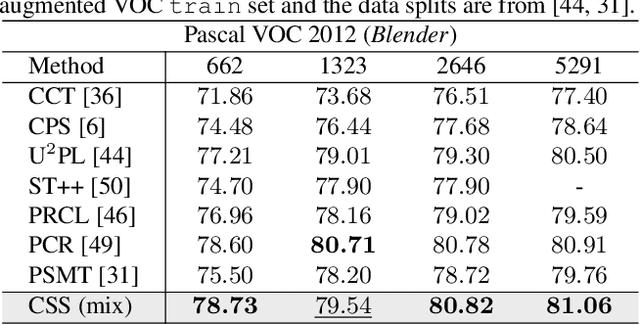
Semi-Supervised Semantic Segmentation (S4) aims to train a segmentation model with limited labeled images and a substantial volume of unlabeled images. To improve the robustness of representations, powerful methods introduce a pixel-wise contrastive learning approach in latent space (i.e., representation space) that aggregates the representations to their prototypes in a fully supervised manner. However, previous contrastive-based S4 methods merely rely on the supervision from the model's output (logits) in logit space during unlabeled training. In contrast, we utilize the outputs in both logit space and representation space to obtain supervision in a collaborative way. The supervision from two spaces plays two roles: 1) reduces the risk of over-fitting to incorrect semantic information in logits with the help of representations; 2) enhances the knowledge exchange between the two spaces. Furthermore, unlike previous approaches, we use the similarity between representations and prototypes as a new indicator to tilt training those under-performing representations and achieve a more efficient contrastive learning process. Results on two public benchmarks demonstrate the competitive performance of our method compared with state-of-the-art methods.
Both Style and Distortion Matter: Dual-Path Unsupervised Domain Adaptation for Panoramic Semantic Segmentation
Mar 25, 2023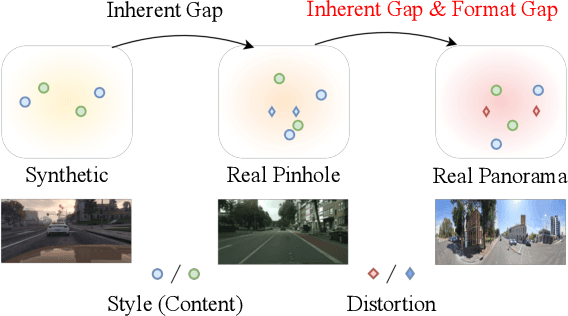
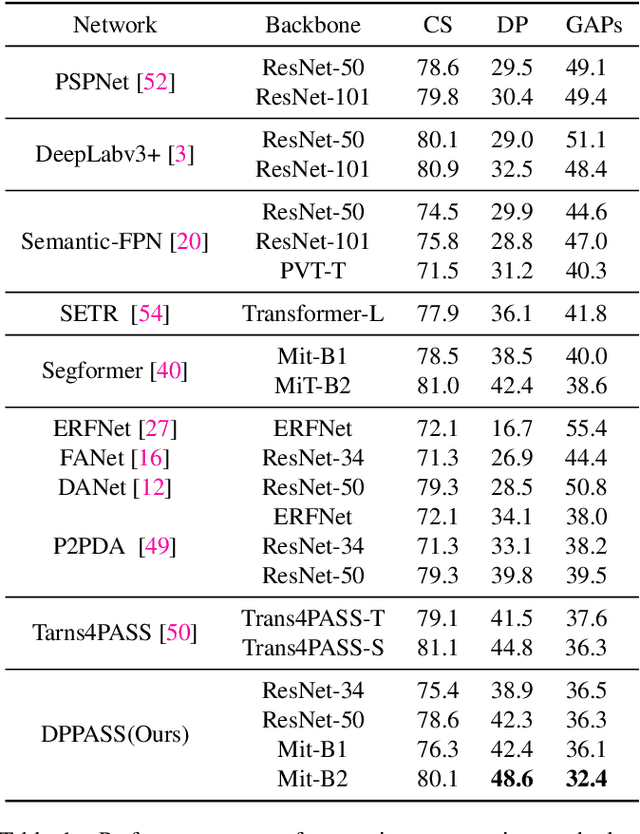
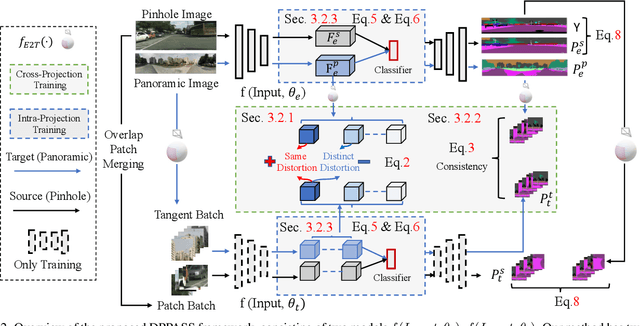
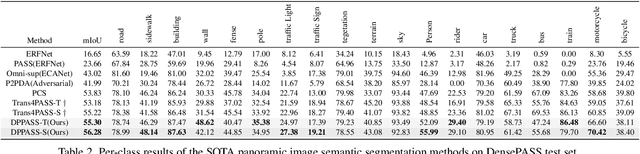
The ability of scene understanding has sparked active research for panoramic image semantic segmentation. However, the performance is hampered by distortion of the equirectangular projection (ERP) and a lack of pixel-wise annotations. For this reason, some works treat the ERP and pinhole images equally and transfer knowledge from the pinhole to ERP images via unsupervised domain adaptation (UDA). However, they fail to handle the domain gaps caused by: 1) the inherent differences between camera sensors and captured scenes; 2) the distinct image formats (e.g., ERP and pinhole images). In this paper, we propose a novel yet flexible dual-path UDA framework, DPPASS, taking ERP and tangent projection (TP) images as inputs. To reduce the domain gaps, we propose cross-projection and intra-projection training. The cross-projection training includes tangent-wise feature contrastive training and prediction consistency training. That is, the former formulates the features with the same projection locations as positive examples and vice versa, for the models' awareness of distortion, while the latter ensures the consistency of cross-model predictions between the ERP and TP. Moreover, adversarial intra-projection training is proposed to reduce the inherent gap, between the features of the pinhole images and those of the ERP and TP images, respectively. Importantly, the TP path can be freely removed after training, leading to no additional inference cost. Extensive experiments on two benchmarks show that our DPPASS achieves +1.06$\%$ mIoU increment than the state-of-the-art approaches.
FreeEagle: Detecting Complex Neural Trojans in Data-Free Cases
Feb 28, 2023



Trojan attack on deep neural networks, also known as backdoor attack, is a typical threat to artificial intelligence. A trojaned neural network behaves normally with clean inputs. However, if the input contains a particular trigger, the trojaned model will have attacker-chosen abnormal behavior. Although many backdoor detection methods exist, most of them assume that the defender has access to a set of clean validation samples or samples with the trigger, which may not hold in some crucial real-world cases, e.g., the case where the defender is the maintainer of model-sharing platforms. Thus, in this paper, we propose FreeEagle, the first data-free backdoor detection method that can effectively detect complex backdoor attacks on deep neural networks, without relying on the access to any clean samples or samples with the trigger. The evaluation results on diverse datasets and model architectures show that FreeEagle is effective against various complex backdoor attacks, even outperforming some state-of-the-art non-data-free backdoor detection methods.
Transformer-CNN Cohort: Semi-supervised Semantic Segmentation by the Best of Both Students
Sep 06, 2022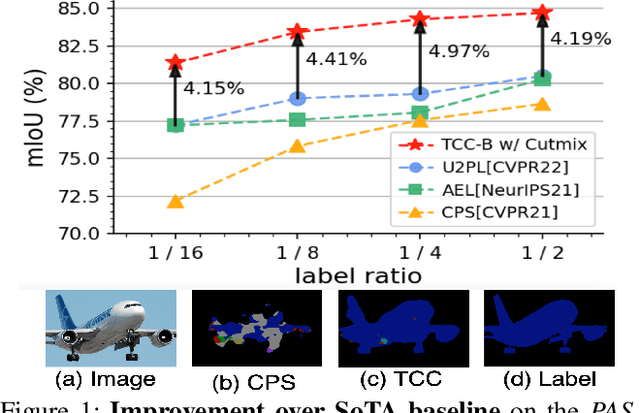
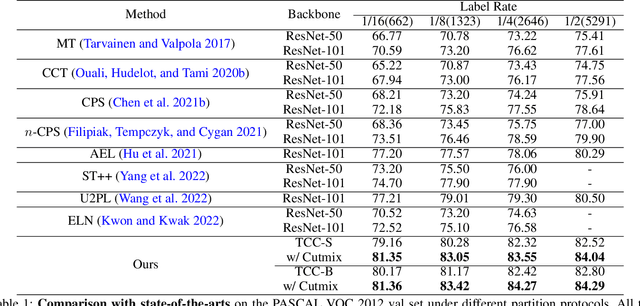
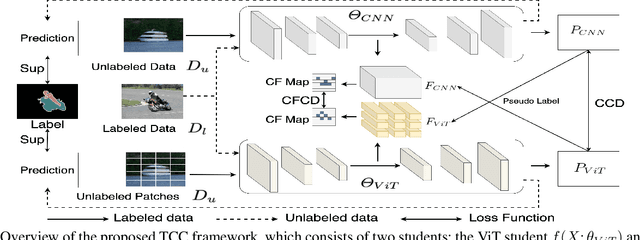
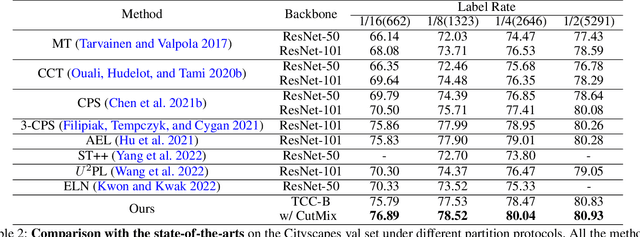
The popular methods for semi-supervised semantic segmentation mostly adopt a unitary network model using convolutional neural networks (CNNs) and enforce consistency of the model predictions over small perturbations applied to the inputs or model. However, such a learning paradigm suffers from a) limited learning capability of the CNN-based model; b) limited capacity of learning the discriminative features for the unlabeled data; c) limited learning for both global and local information from the whole image. In this paper, we propose a novel Semi-supervised Learning approach, called Transformer-CNN Cohort (TCC), that consists of two students with one based on the vision transformer (ViT) and the other based on the CNN. Our method subtly incorporates the multi-level consistency regularization on the predictions and the heterogeneous feature spaces via pseudo labeling for the unlabeled data. First, as the inputs of the ViT student are image patches, the feature maps extracted encode crucial class-wise statistics. To this end, we propose class-aware feature consistency distillation (CFCD) that first leverages the outputs of each student as the pseudo labels and generates class-aware feature (CF) maps. It then transfers knowledge via the CF maps between the students. Second, as the ViT student has more uniform representations for all layers, we propose consistency-aware cross distillation to transfer knowledge between the pixel-wise predictions from the cohort. We validate the TCC framework on Cityscapes and Pascal VOC 2012 datasets, which significantly outperforms existing semi-supervised methods by a large margin.
Transfer Attacks Revisited: A Large-Scale Empirical Study in Real Computer Vision Settings
Apr 07, 2022

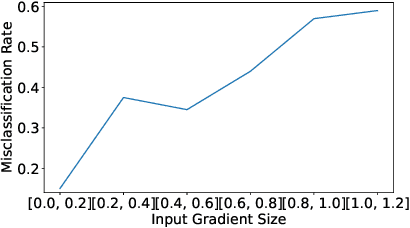
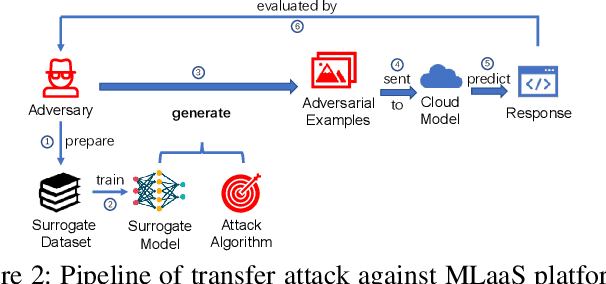
One intriguing property of adversarial attacks is their "transferability" -- an adversarial example crafted with respect to one deep neural network (DNN) model is often found effective against other DNNs as well. Intensive research has been conducted on this phenomenon under simplistic controlled conditions. Yet, thus far, there is still a lack of comprehensive understanding about transferability-based attacks ("transfer attacks") in real-world environments. To bridge this critical gap, we conduct the first large-scale systematic empirical study of transfer attacks against major cloud-based MLaaS platforms, taking the components of a real transfer attack into account. The study leads to a number of interesting findings which are inconsistent to the existing ones, including: (1) Simple surrogates do not necessarily improve real transfer attacks. (2) No dominant surrogate architecture is found in real transfer attacks. (3) It is the gap between posterior (output of the softmax layer) rather than the gap between logit (so-called $\kappa$ value) that increases transferability. Moreover, by comparing with prior works, we demonstrate that transfer attacks possess many previously unknown properties in real-world environments, such as (1) Model similarity is not a well-defined concept. (2) $L_2$ norm of perturbation can generate high transferability without usage of gradient and is a more powerful source than $L_\infty$ norm. We believe this work sheds light on the vulnerabilities of popular MLaaS platforms and points to a few promising research directions.
CatchBackdoor: Backdoor Testing by Critical Trojan Neural Path Identification via Differential Fuzzing
Dec 24, 2021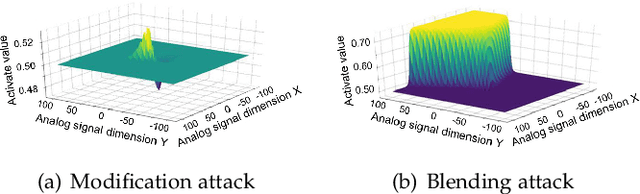
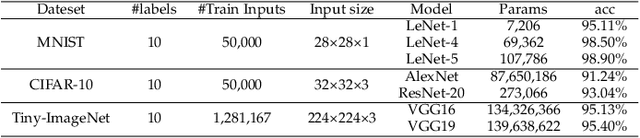
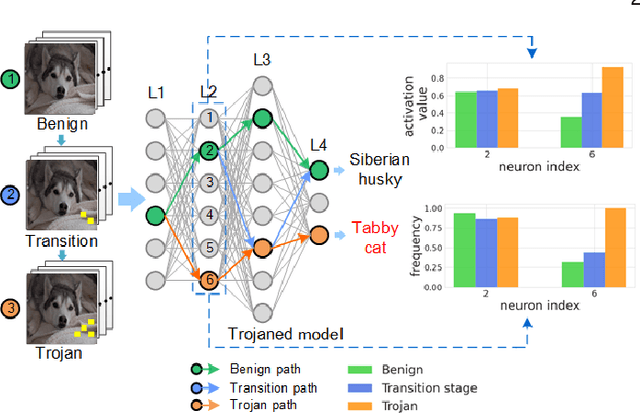
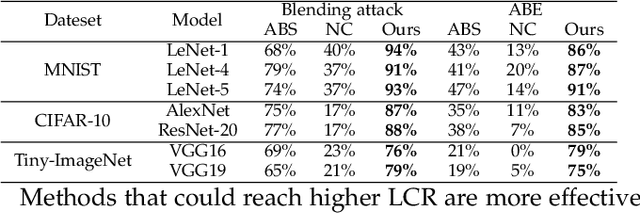
The success of deep neural networks (DNNs) in real-world applications has benefited from abundant pre-trained models. However, the backdoored pre-trained models can pose a significant trojan threat to the deployment of downstream DNNs. Existing DNN testing methods are mainly designed to find incorrect corner case behaviors in adversarial settings but fail to discover the backdoors crafted by strong trojan attacks. Observing the trojan network behaviors shows that they are not just reflected by a single compromised neuron as proposed by previous work but attributed to the critical neural paths in the activation intensity and frequency of multiple neurons. This work formulates the DNN backdoor testing and proposes the CatchBackdoor framework. Via differential fuzzing of critical neurons from a small number of benign examples, we identify the trojan paths and particularly the critical ones, and generate backdoor testing examples by simulating the critical neurons in the identified paths. Extensive experiments demonstrate the superiority of CatchBackdoor, with higher detection performance than existing methods. CatchBackdoor works better on detecting backdoors by stealthy blending and adaptive attacks, which existing methods fail to detect. Moreover, our experiments show that CatchBackdoor may reveal the potential backdoors of models in Model Zoo.
Uncertainty-Aware Deep Co-training for Semi-supervised Medical Image Segmentation
Dec 02, 2021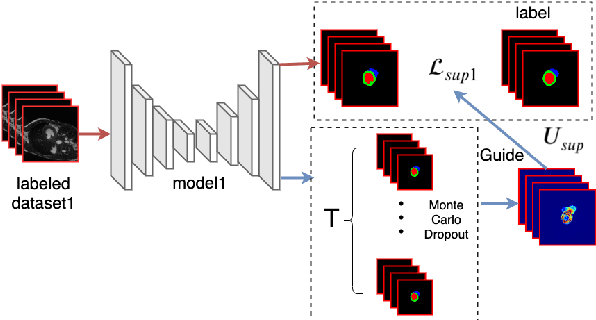
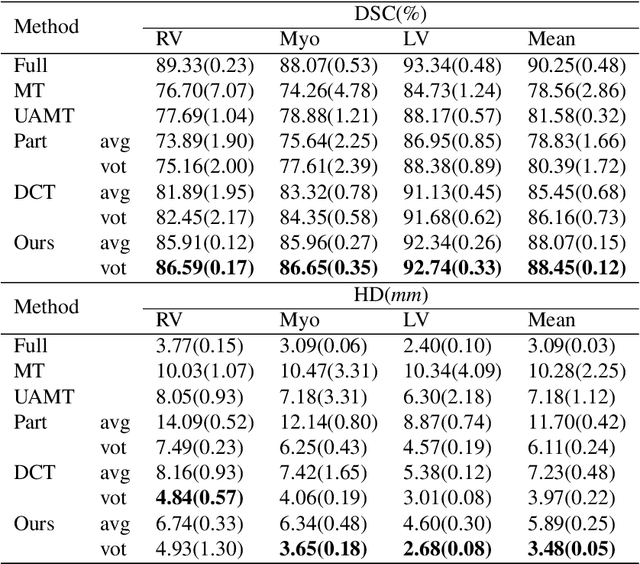
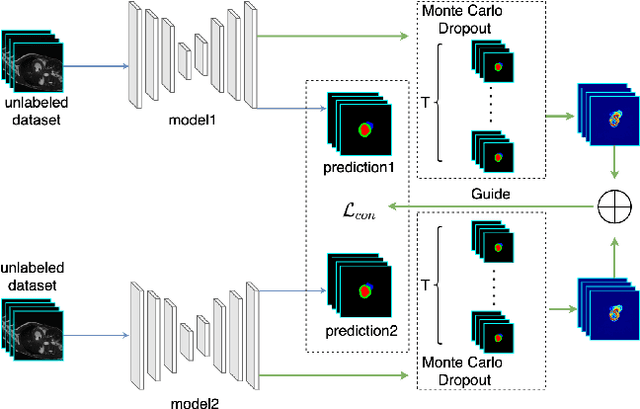
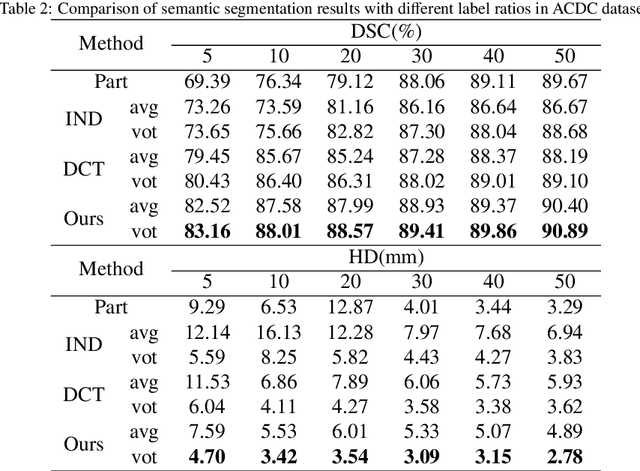
Semi-supervised learning has made significant strides in the medical domain since it alleviates the heavy burden of collecting abundant pixel-wise annotated data for semantic segmentation tasks. Existing semi-supervised approaches enhance the ability to extract features from unlabeled data with prior knowledge obtained from limited labeled data. However, due to the scarcity of labeled data, the features extracted by the models are limited in supervised learning, and the quality of predictions for unlabeled data also cannot be guaranteed. Both will impede consistency training. To this end, we proposed a novel uncertainty-aware scheme to make models learn regions purposefully. Specifically, we employ Monte Carlo Sampling as an estimation method to attain an uncertainty map, which can serve as a weight for losses to force the models to focus on the valuable region according to the characteristics of supervised learning and unsupervised learning. Simultaneously, in the backward process, we joint unsupervised and supervised losses to accelerate the convergence of the network via enhancing the gradient flow between different tasks. Quantitatively, we conduct extensive experiments on three challenging medical datasets. Experimental results show desirable improvements to state-of-the-art counterparts.
A More Compact Object Detector Head Network with Feature Enhancement and Relational Reasoning
Jul 03, 2021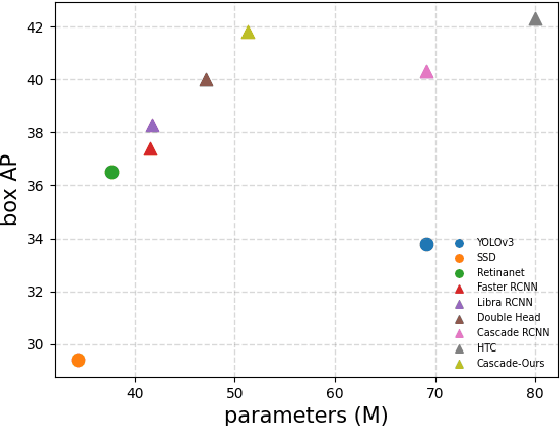
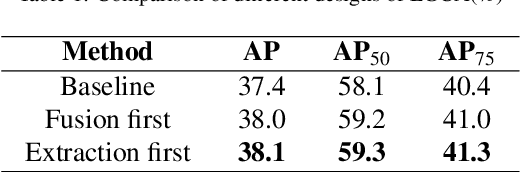
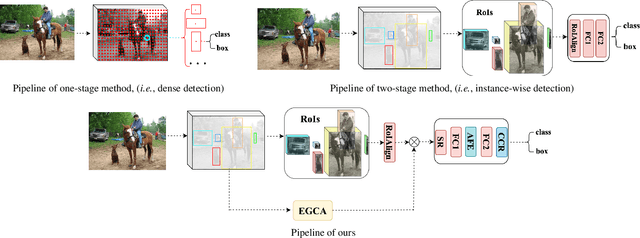
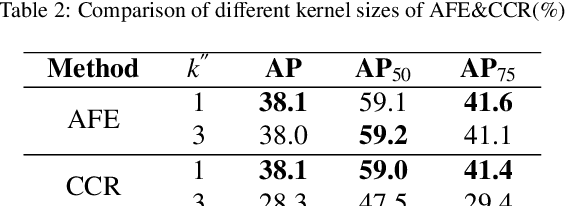
Modeling implicit feature interaction patterns is of significant importance to object detection tasks. However, in the two-stage detectors, due to the excessive use of hand-crafted components, it is very difficult to reason about the implicit relationship of the instance features. To tackle this problem, we analyze three different levels of feature interaction relationships, namely, the dependency relationship between the cropped local features and global features, the feature autocorrelation within the instance, and the cross-correlation relationship between the instances. To this end, we propose a more compact object detector head network (CODH), which can not only preserve global context information and condense the information density, but also allows instance-wise feature enhancement and relational reasoning in a larger matrix space. Without bells and whistles, our method can effectively improve the detection performance while significantly reducing the parameters of the model, e.g., with our method, the parameters of the head network is 0.6 times smaller than the state-of-the-art Cascade R-CNN, yet the performance boost is 1.3% on COCO test-dev. Without losing generality, we can also build a more lighter head network for other multi-stage detectors by assembling our method.
Global Context Aware RCNN for Object Detection
Dec 04, 2020
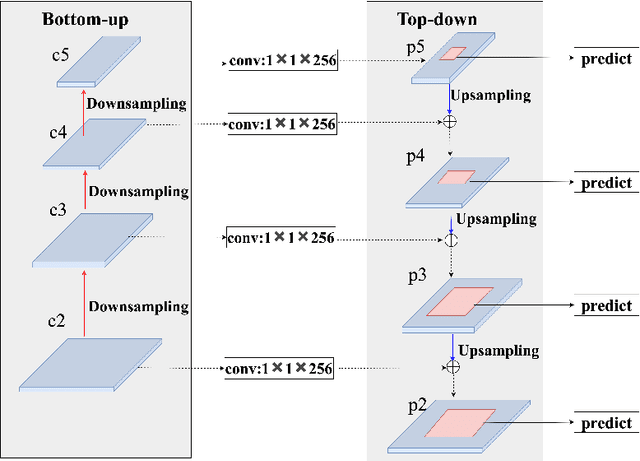
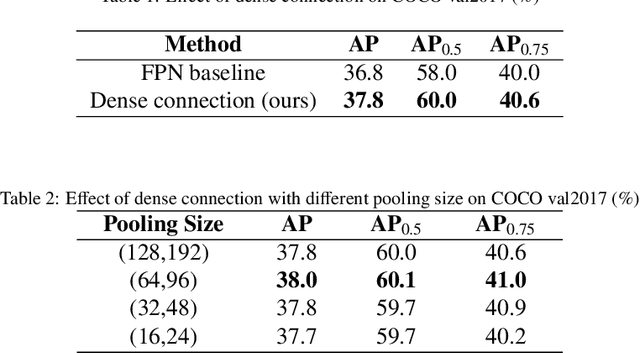
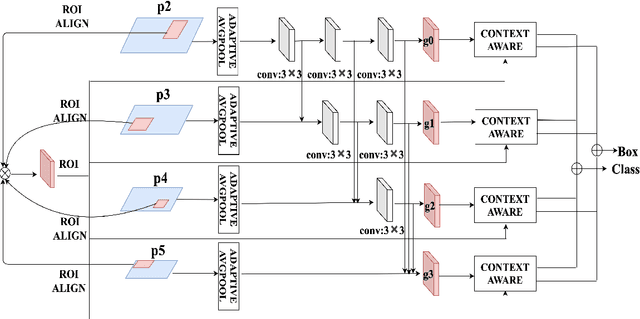
RoIPool/RoIAlign is an indispensable process for the typical two-stage object detection algorithm, it is used to rescale the object proposal cropped from the feature pyramid to generate a fixed size feature map. However, these cropped feature maps of local receptive fields will heavily lose global context information. To tackle this problem, we propose a novel end-to-end trainable framework, called Global Context Aware (GCA) RCNN, aiming at assisting the neural network in strengthening the spatial correlation between the background and the foreground by fusing global context information. The core component of our GCA framework is a context aware mechanism, in which both global feature pyramid and attention strategies are used for feature extraction and feature refinement, respectively. Specifically, we leverage the dense connection to improve the information flow of the global context at different stages in the top-down process of FPN, and further use the attention mechanism to refine the global context at each level in the feature pyramid. In the end, we also present a lightweight version of our method, which only slightly increases model complexity and computational burden. Experimental results on COCO benchmark dataset demonstrate the significant advantages of our approach.