 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-CNN Cohort: Semi-supervised Semantic Segmentation by the Best of Both Students
Paper and Code
Sep 06, 2022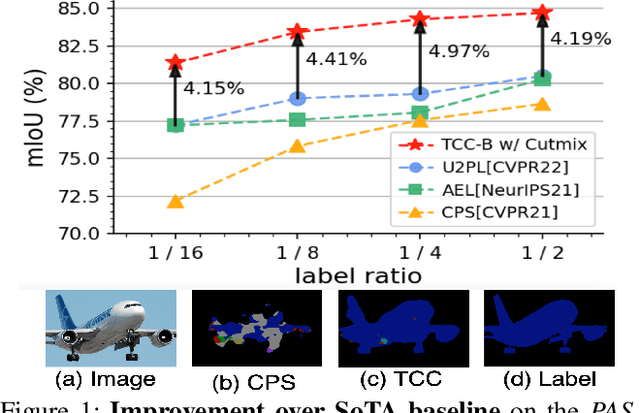
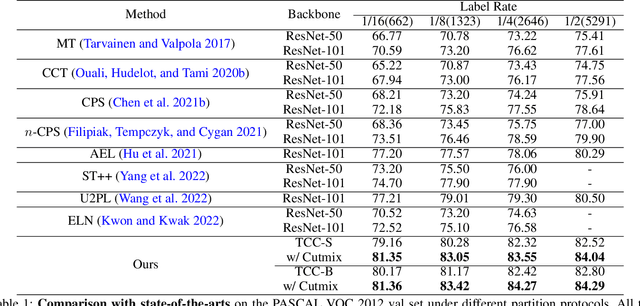
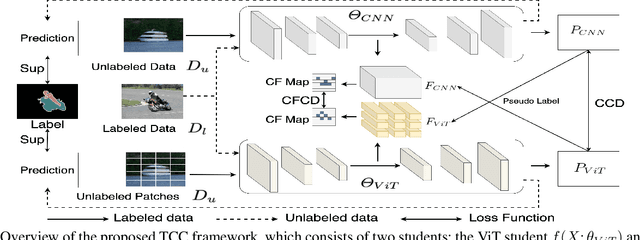
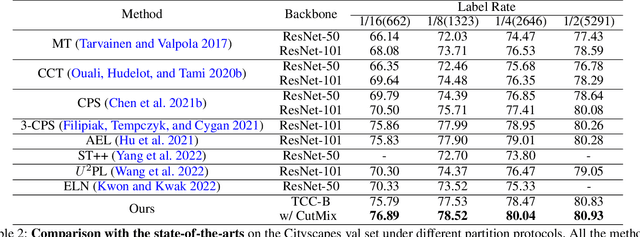
The popular methods for semi-supervised semantic segmentation mostly adopt a unitary network model using convolutional neural networks (CNNs) and enforce consistency of the model predictions over small perturbations applied to the inputs or model. However, such a learning paradigm suffers from a) limited learning capability of the CNN-based model; b) limited capacity of learning the discriminative features for the unlabeled data; c) limited learning for both global and local information from the whole image. In this paper, we propose a novel Semi-supervised Learning approach, called Transformer-CNN Cohort (TCC), that consists of two students with one based on the vision transformer (ViT) and the other based on the CNN. Our method subtly incorporates the multi-level consistency regularization on the predictions and the heterogeneous feature spaces via pseudo labeling for the unlabeled data. First, as the inputs of the ViT student are image patches, the feature maps extracted encode crucial class-wise statistics. To this end, we propose class-aware feature consistency distillation (CFCD) that first leverages the outputs of each student as the pseudo labels and generates class-aware feature (CF) maps. It then transfers knowledge via the CF maps between the students. Second, as the ViT student has more uniform representations for all layers, we propose consistency-aware cross distillation to transfer knowledge between the pixel-wise predictions from the cohort. We validate the TCC framework on Cityscapes and Pascal VOC 2012 datasets, which significantly outperforms existing semi-supervised methods by a large margin.