 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Trajectory Stitching through Diffusion Composition
Mar 07, 2025



Effective trajectory stitching for long-horizon planning is a significant challenge in robotic decision-making. While diffusion models have shown promise in planning, they are limited to solving tasks similar to those seen in their training data. We propose CompDiffuser, a novel generative approach that can solve new tasks by learning to compositionally stitch together shorter trajectory chunks from previously seen tasks. Our key insight is modeling the trajectory distribution by subdividing it into overlapping chunks and learning their conditional relationships through a single bidirectional diffusion model. This allows information to propagate between segments during generation, ensuring physically consistent connections. We conduct experiments on benchmark tasks of various difficulties, covering different environment sizes, agent state dimension, trajectory types, training data quality, and show that CompDiffuser significantly outperforms existing methods.
Engaging with AI: How Interface Design Shapes Human-AI Collaboration in High-Stakes Decision-Making
Jan 28, 2025As reliance on AI systems for decision-making grows, it becomes critical to ensure that human users can appropriately balance trust in AI suggestions with their own judgment, especially in high-stakes domains like healthcare. However, human + AI teams have been shown to perform worse than AI alone, with evidence indicating automation bias as the reason for poorer performance, particularly because humans tend to follow AI's recommendations even when they are incorrect. In many existing human + AI systems, decision-making support is typically provided in the form of text explanations (XAI) to help users understand the AI's reasoning. Since human decision-making often relies on System 1 thinking, users may ignore or insufficiently engage with the explanations, leading to poor decision-making. Previous research suggests that there is a need for new approaches that encourage users to engage with the explanations and one proposed method is the use of cognitive forcing functions (CFFs). In this work, we examine how various decision-support mechanisms impact user engagement, trust, and human-AI collaborative task performance in a diabetes management decision-making scenario. In a controlled experiment with 108 participants, we evaluated the effects of six decision-support mechanisms split into two categories of explanations (text, visual) and four CFFs. Our findings reveal that mechanisms like AI confidence levels, text explanations, and performance visualizations enhanced human-AI collaborative task performance, and improved trust when AI reasoning clues were provided. Mechanisms like human feedback and AI-driven questions encouraged deeper reflection but often reduced task performance by increasing cognitive effort, which in turn affected trust. Simple mechanisms like visual explanations had little effect on trust, highlighting the importance of striking a balance in CFF and XAI design.
Grounding Video Models to Actions through Goal Conditioned Exploration
Nov 11, 2024



Large video models, pretrained on massive amounts of Internet video, provide a rich source of physical knowledge about the dynamics and motions of objects and tasks. However, video models are not grounded in the embodiment of an agent, and do not describe how to actuate the world to reach the visual states depicted in a video. To tackle this problem, current methods use a separate vision-based inverse dynamic model trained on embodiment-specific data to map image states to actions. Gathering data to train such a model is often expensive and challenging, and this model is limited to visual settings similar to the ones in which data are available. In this paper, we investigate how to directly ground video models to continuous actions through self-exploration in the embodied environment -- using generated video states as visual goals for exploration. We propose a framework that uses trajectory level action generation in combination with video guidance to enable an agent to solve complex tasks without any external supervision, e.g., rewards, action labels, or segmentation masks. We validate the proposed approach on 8 tasks in Libero, 6 tasks in MetaWorld, 4 tasks in Calvin, and 12 tasks in iThor Visual Navigation. We show how our approach is on par with or even surpasses multiple behavior cloning baselines trained on expert demonstrations while without requiring any action annotations.
Potential Based Diffusion Motion Planning
Jul 08, 2024Effective motion planning in high dimensional spaces is a long-standing open problem in robotics. One class of traditional motion planning algorithms corresponds to potential-based motion planning. An advantage of potential based motion planning is composability -- different motion constraints can be easily combined by adding corresponding potentials. However, constructing motion paths from potentials requires solving a global optimization across configuration space potential landscape, which is often prone to local minima. We propose a new approach towards learning potential based motion planning, where we train a neural network to capture and learn an easily optimizable potentials over motion planning trajectories. We illustrate the effectiveness of such approach, significantly outperforming both classical and recent learned motion planning approaches and avoiding issues with local minima. We further illustrate its inherent composability, enabling us to generalize to a multitude of different motion constraints.
Semi-supervised Semantic Segmentation via Boosting Uncertainty on Unlabeled Data
Nov 30, 2023We bring a new perspective to semi-supervised semantic segmentation by providing an analysis on the labeled and unlabeled distributions in training datasets. We first figure out that the distribution gap between labeled and unlabeled datasets cannot be ignored, even though the two datasets are sampled from the same distribution. To address this issue, we theoretically analyze and experimentally prove that appropriately boosting uncertainty on unlabeled data can help minimize the distribution gap, which benefits the generalization of the model. We propose two strategies and design an uncertainty booster algorithm, specially for semi-supervised semantic segmentation. Extensive experiments are carried out based on these theories, and the results confirm the efficacy of the algorithm and strategies. Our plug-and-play uncertainty booster is tiny, efficient, and robust to hyperparameters but can significantly promote performance. Our approach achieves state-of-the-art performance in our experiments compared to the current semi-supervised semantic segmentation methods on the popular benchmarks: Cityscapes and PASCAL VOC 2012 with different train settings.
Distilling Efficient Vision Transformers from CNNs for Semantic Segmentation
Oct 11, 2023In this paper, we tackle a new problem: how to transfer knowledge from the pre-trained cumbersome yet well-performed CNN-based model to learn a compact Vision Transformer (ViT)-based model while maintaining its learning capacity? Due to the completely different characteristics of ViT and CNN and the long-existing capacity gap between teacher and student models in Knowledge Distillation (KD), directly transferring the cross-model knowledge is non-trivial. To this end, we subtly leverage the visual and linguistic-compatible feature character of ViT (i.e., student), and its capacity gap with the CNN (i.e., teacher) and propose a novel CNN-to-ViT KD framework, dubbed C2VKD. Importantly, as the teacher's features are heterogeneous to those of the student, we first propose a novel visual-linguistic feature distillation (VLFD) module that explores efficient KD among the aligned visual and linguistic-compatible representations. Moreover, due to the large capacity gap between the teacher and student and the inevitable prediction errors of the teacher, we then propose a pixel-wise decoupled distillation (PDD) module to supervise the student under the combination of labels and teacher's predictions from the decoupled target and non-target classes. Experiments on three semantic segmentation benchmark datasets consistently show that the increment of mIoU of our method is over 200% of the SoTA KD methods
Look at the Neighbor: Distortion-aware Unsupervised Domain Adaptation for Panoramic Semantic Segmentation
Aug 10, 2023Endeavors have been recently made to transfer knowledge from the labeled pinhole image domain to the unlabeled panoramic image domain via Unsupervised Domain Adaptation (UDA). The aim is to tackle the domain gaps caused by the style disparities and distortion problem from the non-uniformly distributed pixels of equirectangular projection (ERP). Previous works typically focus on transferring knowledge based on geometric priors with specially designed multi-branch network architectures. As a result, considerable computational costs are induced, and meanwhile, their generalization abilities are profoundly hindered by the variation of distortion among pixels. In this paper, we find that the pixels' neighborhood regions of the ERP indeed introduce less distortion. Intuitively, we propose a novel UDA framework that can effectively address the distortion problems for panoramic semantic segmentation. In comparison, our method is simpler, easier to implement, and more computationally efficient. Specifically, we propose distortion-aware attention (DA) capturing the neighboring pixel distribution without using any geometric constraints. Moreover, we propose a class-wise feature aggregation (CFA) module to iteratively update the feature representations with a memory bank. As such, the feature similarity between two domains can be consistently optimized. Extensive experiments show that our method achieves new state-of-the-art performance while remarkably reducing 80% parameters.
A Good Student is Cooperative and Reliable: CNN-Transformer Collaborative Learning for Semantic Segmentation
Jul 24, 2023In this paper, we strive to answer the question "how to collaboratively learn convolutional neural network (CNN)-based and vision transformer (ViT)-based models by selecting and exchanging the reliable knowledge between them for semantic segmentation?" Accordingly, we propose an online knowledge distillation (KD) framework that can simultaneously learn compact yet effective CNN-based and ViT-based models with two key technical breakthroughs to take full advantage of CNNs and ViT while compensating their limitations. Firstly, we propose heterogeneous feature distillation (HFD) to improve students' consistency in low-layer feature space by mimicking heterogeneous features between CNNs and ViT. Secondly, to facilitate the two students to learn reliable knowledge from each other, we propose bidirectional selective distillation (BSD) that can dynamically transfer selective knowledge. This is achieved by 1) region-wise BSD determining the directions of knowledge transferred between the corresponding regions in the feature space and 2) pixel-wise BSD discerning which of the prediction knowledge to be transferred in the logit space. Extensive experiments on three benchmark datasets demonstrate that our proposed framework outperforms the state-of-the-art online distillation methods by a large margin, and shows its efficacy in learning collaboratively between ViT-based and CNN-based models.
Inter-Rater Uncertainty Quantification in Medical Image Segmentation via Rater-Specific Bayesian Neural Networks
Jun 28, 2023
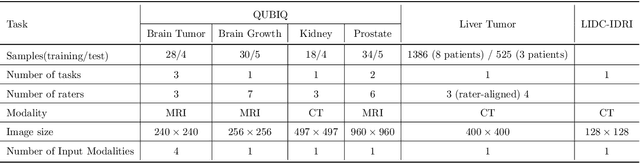


Automated medical image segmentation inherently involves a certain degree of uncertainty. One key factor contributing to this uncertainty is the ambiguity that can arise in determining the boundaries of a target region of interest, primarily due to variations in image appearance. On top of this, even among experts in the field, different opinions can emerge regarding the precise definition of specific anatomical structures. This work specifically addresses the modeling of segmentation uncertainty, known as inter-rater uncertainty. Its primary objective is to explore and analyze the variability in segmentation outcomes that can occur when multiple experts in medical imaging interpret and annotate the same images. We introduce a novel Bayesian neural network-based architecture to estimate inter-rater uncertainty in medical image segmentation. Our approach has three key advancements. Firstly, we introduce a one-encoder-multi-decoder architecture specifically tailored for uncertainty estimation, enabling us to capture the rater-specific representation of each expert involved. Secondly, we propose Bayesian modeling for the new architecture, allowing efficient capture of the inter-rater distribution, particularly in scenarios with limited annotations. Lastly, we enhance the rater-specific representation by integrating an attention module into each decoder. This module facilitates focused and refined segmentation results for each rater. We conduct extensive evaluations using synthetic and real-world datasets to validate our technical innovations rigorously. Our method surpasses existing baseline methods in five out of seven diverse tasks on the publicly available \emph{QUBIQ} dataset, considering two evaluation metrics encompassing different uncertainty aspects. Our codes, models, and the new dataset are available through our GitHub repository: https://github.com/HaoWang420/bOEMD-net .
Transformer-CNN Cohort: Semi-supervised Semantic Segmentation by the Best of Both Students
Sep 06, 2022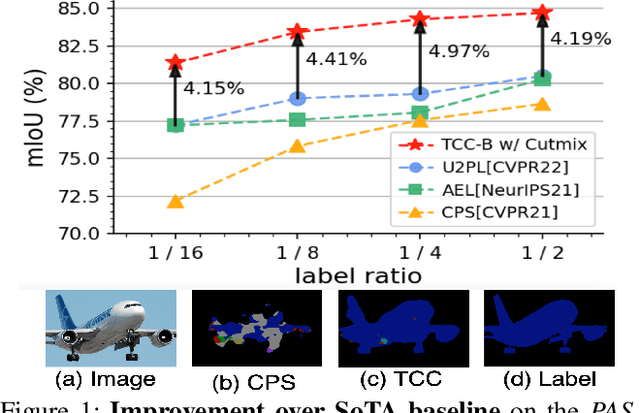
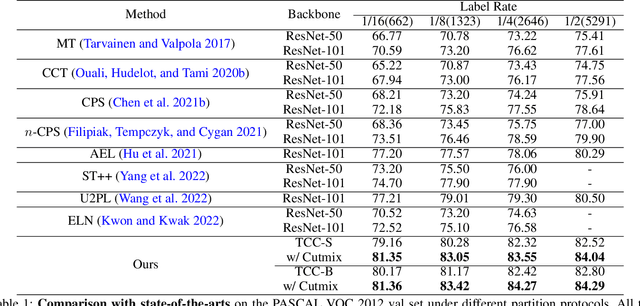
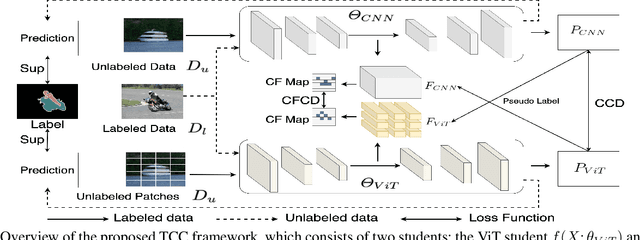
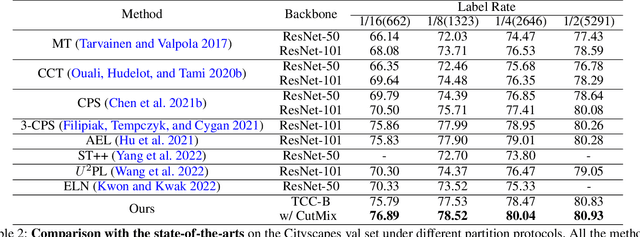
The popular methods for semi-supervised semantic segmentation mostly adopt a unitary network model using convolutional neural networks (CNNs) and enforce consistency of the model predictions over small perturbations applied to the inputs or model. However, such a learning paradigm suffers from a) limited learning capability of the CNN-based model; b) limited capacity of learning the discriminative features for the unlabeled data; c) limited learning for both global and local information from the whole image. In this paper, we propose a novel Semi-supervised Learning approach, called Transformer-CNN Cohort (TCC), that consists of two students with one based on the vision transformer (ViT) and the other based on the CNN. Our method subtly incorporates the multi-level consistency regularization on the predictions and the heterogeneous feature spaces via pseudo labeling for the unlabeled data. First, as the inputs of the ViT student are image patches, the feature maps extracted encode crucial class-wise statistics. To this end, we propose class-aware feature consistency distillation (CFCD) that first leverages the outputs of each student as the pseudo labels and generates class-aware feature (CF) maps. It then transfers knowledge via the CF maps between the students. Second, as the ViT student has more uniform representations for all layers, we propose consistency-aware cross distillation to transfer knowledge between the pixel-wise predictions from the cohort. We validate the TCC framework on Cityscapes and Pascal VOC 2012 datasets, which significantly outperforms existing semi-supervised methods by a large margin.