 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Papers to Property Tables: A Priority-Based LLM Workflow for Materials Data Extraction
Apr 08, 2026Scientific data are widely dispersed across research articles and are often reported inconsistently across text, tables, and figures, making manual data extraction and aggregation slow and error-prone. We present a prompt-driven, hierarchical workflow that uses a large language model (LLM) to automatically extract and reconstruct structured, shot-level shock-physics experimental records by integrating information distributed across text, tables, figures, and physics-based derivations from full-text published research articles, using alloy spall strength as a representative case study. The pipeline targeted 37 experimentally relevant fields per shot and applied a three-level priority strategy: (T1) direct extraction from text/tables, (T2) physics-based derivation using verified governing relations, and (T3) digitization from figures when necessary. Extracted values were normalized to canonical units, tagged by priority for traceability, and validated with physics-based consistency and plausibility checks. Evaluated on a benchmark of 30 published research articles comprising 11,967 evaluated data points, the workflow achieved high overall accuracy, with priority-wise accuracies of 94.93% (T1), 92.04% (T2), and 83.49% (T3), and an overall weighted accuracy of 94.69%. Cross-model testing further indicated strong agreement for text/table and equation-derived fields, with lower agreement for figure-based extraction. Implementation through an API interface demonstrated the scalability of the approach, achieving consistent extraction performance and, in a subset of test cases, matching or exceeding chat-based accuracy. This workflow demonstrates a practical approach for converting unstructured technical literature into traceable, analysis-ready datasets without task-specific fine-tuning, enabling scalable database construction in materials science.
Learning Ordinal Probabilistic Reward from Preferences
Feb 13, 2026Reward models are crucial for aligning large language models (LLMs) with human values and intentions. Existing approaches follow either Generative (GRMs) or Discriminative (DRMs) paradigms, yet both suffer from limitations: GRMs typically demand costly point-wise supervision, while DRMs produce uncalibrated relative scores that lack probabilistic interpretation. To address these challenges, we introduce a novel reward modeling paradigm: Probabilistic Reward Model (PRM). Instead of modeling reward as a deterministic scalar, our approach treats it as a random variable, learning a full probability distribution for the quality of each response. To make this paradigm practical, we present its closed-form, discrete realization: the Ordinal Probabilistic Reward Model (OPRM), which discretizes the quality score into a finite set of ordinal ratings. Building on OPRM, we propose a data-efficient training strategy called Region Flooding Tuning (RgFT). It enables rewards to better reflect absolute text quality by incorporating quality-level annotations, which guide the model to concentrate the probability mass within corresponding rating sub-regions. Experiments on various reward model benchmarks show that our method improves accuracy by $\textbf{2.9%}\sim\textbf{7.4%}$ compared to prior reward models, demonstrating strong performance and data efficiency. Analysis of the score distribution provides evidence that our method captures not only relative rankings but also absolute quality.
Song Aesthetics Evaluation with Multi-Stem Attention and Hierarchical Uncertainty Modeling
Jan 18, 2026Music generative artificial intelligence (AI) is rapidly expanding music content, necessitating automated song aesthetics evaluation. However, existing studies largely focus on speech, audio or singing quality, leaving song aesthetics underexplored. Moreover, conventional approaches often predict a precise Mean Opinion Score (MOS) value directly, which struggles to capture the nuances of human perception in song aesthetics evaluation. This paper proposes a song-oriented aesthetics evaluation framework, featuring two novel modules: 1) Multi-Stem Attention Fusion (MSAF) builds bidirectional cross-attention between mixture-vocal and mixture-accompaniment pairs, fusing them to capture complex musical features; 2) Hierarchical Granularity-Aware Interval Aggregation (HiGIA) learns multi-granularity score probability distributions, aggregates them into a score interval, and applies a regression within the interval to produce the final score. We evaluated on two datasets of full-length songs: SongEval dataset (AI-generated) and an internal aesthetics dataset (human-created), and compared with two state-of-the-art (SOTA) models. Results show that the proposed method achieves stronger performance for multi-dimensional song aesthetics evaluation.
MindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
Dec 29, 2025Traditional workflow-based agents exhibit limited intelligence when addressing real-world problems requiring tool invocation. Tool-integrated reasoning (TIR) agents capable of autonomous reasoning and tool invocation are rapidly emerging as a powerful approach for complex decision-making tasks involving multi-step interactions with external environments. In this work, we introduce MindWatcher, a TIR agent integrating interleaved thinking and multimodal chain-of-thought (CoT) reasoning. MindWatcher can autonomously decide whether and how to invoke diverse tools and coordinate their use, without relying on human prompts or workflows. The interleaved thinking paradigm enables the model to switch between thinking and tool calling at any intermediate stage, while its multimodal CoT capability allows manipulation of images during reasoning to yield more precise search results. We implement automated data auditing and evaluation pipelines, complemented by manually curated high-quality datasets for training, and we construct a benchmark, called MindWatcher-Evaluate Bench (MWE-Bench), to evaluate its performance. MindWatcher is equipped with a comprehensive suite of auxiliary reasoning tools, enabling it to address broad-domain multimodal problems. A large-scale, high-quality local image retrieval database, covering eight categories including cars, animals, and plants, endows model with robust object recognition despite its small size. Finally, we design a more efficient training infrastructure for MindWatcher, enhancing training speed and hardware utilization. Experiments not only demonstrate that MindWatcher matches or exceeds the performance of larger or more recent models through superior tool invocation, but also uncover critical insights for agent training, such as the genetic inheritance phenomenon in agentic RL.
Exploring Classical Piano Performance Generation with Expressive Music Variational AutoEncoder
Jul 02, 2025The creativity of classical music arises not only from composers who craft the musical sheets but also from performers who interpret the static notations with expressive nuances. This paper addresses the challenge of generating classical piano performances from scratch, aiming to emulate the dual roles of composer and pianist in the creative process. We introduce the Expressive Compound Word (ECP) representation, which effectively captures both the metrical structure and expressive nuances of classical performances. Building on this, we propose the Expressive Music Variational AutoEncoder (XMVAE), a model featuring two branches: a Vector Quantized Variational AutoEncoder (VQ-VAE) branch that generates score-related content, representing the Composer, and a vanilla VAE branch that produces expressive details, fulfilling the role of Pianist. These branches are jointly trained with similar Seq2Seq architectures, leveraging a multiscale encoder to capture beat-level contextual information and an orthogonal Transformer decoder for efficient compound tokens decoding. Both objective and subjective evaluations demonstrate that XMVAE generates classical performances with superior musical quality compared to state-of-the-art models. Furthermore, pretraining the Composer branch on extra musical score datasets contribute to a significant performance gain.
Uncertainty-Aware Machine-Learning Framework for Predicting Dislocation Plasticity and Stress-Strain Response in FCC Alloys
Jun 25, 2025Machine learning has significantly advanced the understanding and application of structural materials, with an increasing emphasis on integrating existing data and quantifying uncertainties in predictive modeling. This study presents a comprehensive methodology utilizing a mixed density network (MDN) model, trained on extensive experimental data from literature. This approach uniquely predicts the distribution of dislocation density, inferred as a latent variable, and the resulting stress distribution at the grain level. The incorporation of statistical parameters of those predicted distributions into a dislocation-mediated plasticity model allows for accurate stress-strain predictions with explicit uncertainty quantification. This strategy not only improves the accuracy and reliability of mechanical property predictions but also plays a vital role in optimizing alloy design, thereby facilitating the development of new materials in a rapidly evolving industry.
Small Tunes Transformer: Exploring Macro & Micro-Level Hierarchies for Skeleton-Conditioned Melody Generation
Oct 11, 2024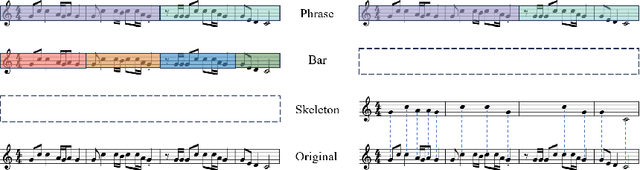
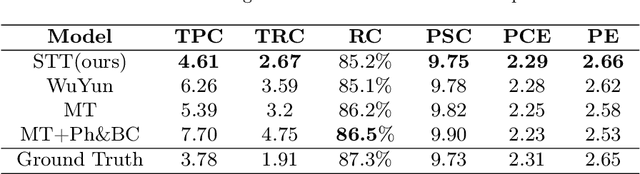
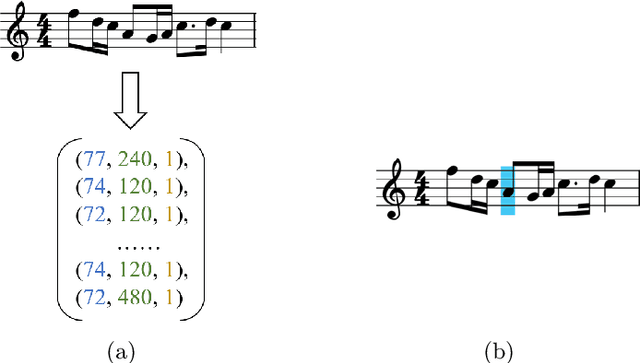

Recently, symbolic music generation has become a focus of numerous deep learning research. Structure as an important part of music, contributes to improving the quality of music, and an increasing number of works start to study the hierarchical structure. In this study, we delve into the multi-level structures within music from macro-level and micro-level hierarchies. At the macro-level hierarchy, we conduct phrase segmentation algorithm to explore how phrases influence the overall development of music, and at the micro-level hierarchy, we design skeleton notes extraction strategy to explore how skeleton notes within each phrase guide the melody generation. Furthermore, we propose a novel Phrase-level Cross-Attention mechanism to capture the intrinsic relationship between macro-level hierarchy and micro-level hierarchy. Moreover, in response to the current lack of research on Chinese-style music, we construct our Small Tunes Dataset: a substantial collection of MIDI files comprising 10088 Small Tunes, a category of traditional Chinese Folk Songs. This dataset serves as the focus of our study. We generate Small Tunes songs utilizing the extracted skeleton notes as conditions, and experiment results indicate that our proposed model, Small Tunes Transformer, outperforms other state-of-the-art models. Besides, we design three novel objective evaluation metrics to evaluate music from both rhythm and melody dimensions.
PersonaMath: Enhancing Math Reasoning through Persona-Driven Data Augmentation
Oct 02, 2024


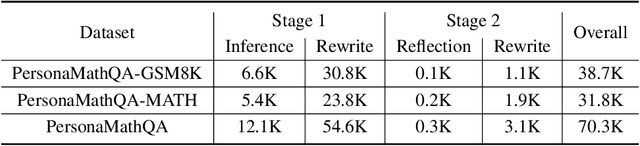
While closed-source Large Language Models (LLMs) demonstrate strong mathematical problem-solving abilities, open-source models continue to struggle with such tasks. To bridge this gap, we propose a data augmentation approach and introduce PersonaMathQA, a dataset derived from MATH and GSM8K, on which we train the PersonaMath models. Our approach consists of two stages: the first stage is learning from Persona Diversification, and the second stage is learning from Reflection. In the first stage, we regenerate detailed chain-of-thought (CoT) solutions as instructions using a closed-source LLM and introduce a novel persona-driven data augmentation technique to enhance the dataset's quantity and diversity. In the second stage, we incorporate reflection to fully leverage more challenging and valuable questions. Evaluation of our PersonaMath models on MATH and GSM8K reveals that the PersonaMath-7B model (based on LLaMA-2-7B) achieves an accuracy of 24.2% on MATH and 68.7% on GSM8K, surpassing all baseline methods and achieving state-of-the-art performance. Notably, our dataset contains only 70.3K data points-merely 17.8% of MetaMathQA and 27% of MathInstruct-yet our model outperforms these baselines, demonstrating the high quality and diversity of our dataset, which enables more efficient model training. We open-source the PersonaMathQA dataset, PersonaMath models, and our code for public usage.
Investigating the Impact of Model Complexity in Large Language Models
Oct 01, 2024Large Language Models (LLMs) based on the pre-trained fine-tuning paradigm have become pivotal in solving natural language processing tasks, consistently achieving state-of-the-art performance. Nevertheless, the theoretical understanding of how model complexity influences fine-tuning performance remains challenging and has not been well explored yet. In this paper, we focus on autoregressive LLMs and propose to employ Hidden Markov Models (HMMs) to model them. Based on the HMM modeling, we investigate the relationship between model complexity and the generalization capability in downstream tasks. Specifically, we consider a popular tuning paradigm for downstream tasks, head tuning, where all pre-trained parameters are frozen and only individual heads are trained atop pre-trained LLMs. Our theoretical analysis reveals that the risk initially increases and then decreases with rising model complexity, showcasing a "double descent" phenomenon. In this case, the initial "descent" is degenerate, signifying that the "sweet spot" where bias and variance are balanced occurs when the model size is zero. Obtaining the presented in this study conclusion confronts several challenges, primarily revolving around effectively modeling autoregressive LLMs and downstream tasks, as well as conducting a comprehensive risk analysis for multivariate regression. Our research is substantiated by experiments conducted on data generated from HMMs, which provided empirical support and alignment with our theoretical insights.
Mirror contrastive loss based sliding window transformer for subject-independent motor imagery based EEG signal recognition
Aug 29, 2024



While deep learning models have been extensively utilized in motor imagery based EEG signal recognition, they often operate as black boxes. Motivated by neurological findings indicating that the mental imagery of left or right-hand movement induces event-related desynchronization (ERD) in the contralateral sensorimotor area of the brain, we propose a Mirror Contrastive Loss based Sliding Window Transformer (MCL-SWT) to enhance subject-independent motor imagery-based EEG signal recognition. Specifically, our proposed mirror contrastive loss enhances sensitivity to the spatial location of ERD by contrasting the original EEG signals with their mirror counterparts-mirror EEG signals generated by interchanging the channels of the left and right hemispheres of the EEG signals. Moreover, we introduce a temporal sliding window transformer that computes self-attention scores from high temporal resolution features, thereby improving model performance with manageable computational complexity. We evaluate the performance of MCL-SWT on subject-independent motor imagery EEG signal recognition tasks, and our experimental results demonstrate that MCL-SWT achieved accuracies of 66.48% and 75.62%, surpassing the state-of-the-art (SOTA) model by 2.82% and 2.17%, respectively. Furthermore, ablation experiments confirm the effectiveness of the proposed mirror contrastive loss. A code demo of MCL-SWT is available at https://github.com/roniusLuo/MCL_SWT.