 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaMath: Enhancing Math Reasoning through Persona-Driven Data Augmentation
Paper and Code
Oct 02, 2024


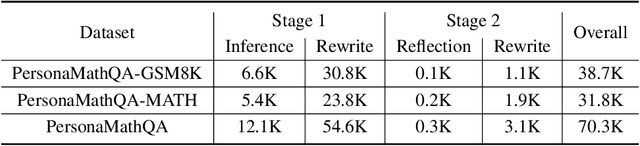
While closed-source Large Language Models (LLMs) demonstrate strong mathematical problem-solving abilities, open-source models continue to struggle with such tasks. To bridge this gap, we propose a data augmentation approach and introduce PersonaMathQA, a dataset derived from MATH and GSM8K, on which we train the PersonaMath models. Our approach consists of two stages: the first stage is learning from Persona Diversification, and the second stage is learning from Reflection. In the first stage, we regenerate detailed chain-of-thought (CoT) solutions as instructions using a closed-source LLM and introduce a novel persona-driven data augmentation technique to enhance the dataset's quantity and diversity. In the second stage, we incorporate reflection to fully leverage more challenging and valuable questions. Evaluation of our PersonaMath models on MATH and GSM8K reveals that the PersonaMath-7B model (based on LLaMA-2-7B) achieves an accuracy of 24.2% on MATH and 68.7% on GSM8K, surpassing all baseline methods and achieving state-of-the-art performance. Notably, our dataset contains only 70.3K data points-merely 17.8% of MetaMathQA and 27% of MathInstruct-yet our model outperforms these baselines, demonstrating the high quality and diversity of our dataset, which enables more efficient model training. We open-source the PersonaMathQA dataset, PersonaMath models, and our code for public usage.