 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBurn-After-Use for Preventing Data Leakage through a Secure Multi-Tenant Architecture in Enterprise LLM
Jan 10, 2026This study presents a Secure Multi-Tenant Architecture (SMTA) combined with a novel concept Burn-After-Use (BAU) mechanism for enterprise LLM environments to effectively prevent data leakage. As institutions increasingly adopt LLMs across departments, the risks of data leakage have become a critical security and compliance concern. The proposed SMTA isolates LLM instances across departments and enforces rigorous context ownership boundaries within an internally deployed infrastructure. The BAU mechanism introduces data confidentiality by enforcing ephemeral conversational contexts that are automatically destroyed after use, preventing cross-session or cross-user inference. The evaluation to SMTA and BAU is through two sets of realistic and reproducible experiments comprising of 127 test iterations. One aspect of this experiment is to assess prompt-based and semantic leakage attacks in a multi-tenant architecture (Appendix A) across 55 infrastructure-level attack tests, including vector-database credential compromise and shared logging pipeline exposure. SMTA achieves 92% defense success rate, demonstrating strong semantic isolation while highlighting residual risks from credential misconfiguration and observability pipelines. Another aspect is to evaluate the robustness of BAU under realistic failure scenarios (Appendix B) using four empirical metrics: Local Residual Persistence Rate (LRPR), Remote Residual Persistence Rate (RRPR), Image Frame Exposure Rate (IFER), and Burn Timer Persistence Rate (BTPR). Across 72 test iterations, BAU achieves a 76.75% success rate in mitigating post-session leakage threats across the client, server, application, infrastructure, and cache layers. These results show that SMTA and BAU together enforce strict isolation, complete session ephemerality, strong confidentiality guarantees, non-persistence, and policy-aligned behavior for enterprise LLMs.
I2E: From Image Pixels to Actionable Interactive Environments for Text-Guided Image Editing
Jan 07, 2026Existing text-guided image editing methods primarily rely on end-to-end pixel-level inpainting paradigm. Despite its success in simple scenarios, this paradigm still significantly struggles with compositional editing tasks that require precise local control and complex multi-object spatial reasoning. This paradigm is severely limited by 1) the implicit coupling of planning and execution, 2) the lack of object-level control granularity, and 3) the reliance on unstructured, pixel-centric modeling. To address these limitations, we propose I2E, a novel "Decompose-then-Action" paradigm that revisits image editing as an actionable interaction process within a structured environment. I2E utilizes a Decomposer to transform unstructured images into discrete, manipulable object layers and then introduces a physics-aware Vision-Language-Action Agent to parse complex instructions into a series of atomic actions via Chain-of-Thought reasoning. Further, we also construct I2E-Bench, a benchmark designed for multi-instance spatial reasoning and high-precision editing. Experimental results on I2E-Bench and multiple public benchmarks demonstrate that I2E significantly outperforms state-of-the-art methods in handling complex compositional instructions, maintaining physical plausibility, and ensuring multi-turn editing stability.
E3-Rewrite: Learning to Rewrite SQL for Executability, Equivalence,and Efficiency
Aug 12, 2025SQL query rewriting aims to reformulate a query into a more efficient form while preserving equivalence. Most existing methods rely on predefined rewrite rules. However, such rule-based approaches face fundamental limitations: (1) fixed rule sets generalize poorly to novel query patterns and struggle with complex queries; (2) a wide range of effective rewriting strategies cannot be fully captured by declarative rules. To overcome these issues, we propose using large language models (LLMs) to generate rewrites. LLMs can capture complex strategies, such as evaluation reordering and CTE rewriting. Despite this potential, directly applying LLMs often results in suboptimal or non-equivalent rewrites due to a lack of execution awareness and semantic grounding. To address these challenges, We present E3-Rewrite, an LLM-based SQL rewriting framework that produces executable, equivalent, and efficient queries. It integrates two core components: a context construction module and a reinforcement learning framework. First, the context module leverages execution plans and retrieved demonstrations to build bottleneck-aware prompts that guide inference-time rewriting. Second, we design a reward function targeting executability, equivalence, and efficiency, evaluated via syntax checks, equivalence verification, and cost estimation. Third, to ensure stable multi-objective learning, we adopt a staged curriculum that first emphasizes executability and equivalence, then gradually incorporates efficiency. Extensive experiments show that E3-Rewrite achieves up to a 25.6\% reduction in query execution time compared to state-of-the-art methods across multiple SQL benchmarks. Moreover, it delivers up to 24.4\% more successful rewrites, expanding coverage to complex queries that previous systems failed to handle.
Training Superior Sparse Autoencoders for Instruct Models
Jun 09, 2025As large language models (LLMs) grow in scale and capability, understanding their internal mechanisms becomes increasingly critical. Sparse autoencoders (SAEs) have emerged as a key tool in mechanistic interpretability, enabling the extraction of human-interpretable features from LLMs. However, existing SAE training methods are primarily designed for base models, resulting in reduced reconstruction quality and interpretability when applied to instruct models. To bridge this gap, we propose $\underline{\textbf{F}}$inetuning-$\underline{\textbf{a}}$ligned $\underline{\textbf{S}}$equential $\underline{\textbf{T}}$raining ($\textit{FAST}$), a novel training method specifically tailored for instruct models. $\textit{FAST}$ aligns the training process with the data distribution and activation patterns characteristic of instruct models, resulting in substantial improvements in both reconstruction and feature interpretability. On Qwen2.5-7B-Instruct, $\textit{FAST}$ achieves a mean squared error of 0.6468 in token reconstruction, significantly outperforming baseline methods with errors of 5.1985 and 1.5096. In feature interpretability, $\textit{FAST}$ yields a higher proportion of high-quality features, for Llama3.2-3B-Instruct, $21.1\%$ scored in the top range, compared to $7.0\%$ and $10.2\%$ for $\textit{BT(P)}$ and $\textit{BT(F)}$. Surprisingly, we discover that intervening on the activations of special tokens via the SAEs leads to improvements in output quality, suggesting new opportunities for fine-grained control of model behavior. Code, data, and 240 trained SAEs are available at https://github.com/Geaming2002/FAST.
ReactDiff: Latent Diffusion for Facial Reaction Generation
May 20, 2025Given the audio-visual clip of the speaker, facial reaction generation aims to predict the listener's facial reactions. The challenge lies in capturing the relevance between video and audio while balancing appropriateness, realism, and diversity. While prior works have mostly focused on uni-modal inputs or simplified reaction mappings, recent approaches such as PerFRDiff have explored multi-modal inputs and the one-to-many nature of appropriate reaction mappings. In this work, we propose the Facial Reaction Diffusion (ReactDiff) framework that uniquely integrates a Multi-Modality Transformer with conditional diffusion in the latent space for enhanced reaction generation. Unlike existing methods, ReactDiff leverages intra- and inter-class attention for fine-grained multi-modal interaction, while the latent diffusion process between the encoder and decoder enables diverse yet contextually appropriate outputs. Experimental results demonstrate that ReactDiff significantly outperforms existing approaches, achieving a facial reaction correlation of 0.26 and diversity score of 0.094 while maintaining competitive realism. The code is open-sourced at \href{https://github.com/Hunan-Tiger/ReactDiff}{github}.
IPBench: Benchmarking the Knowledge of Large Language Models in Intellectual Property
Apr 22, 2025

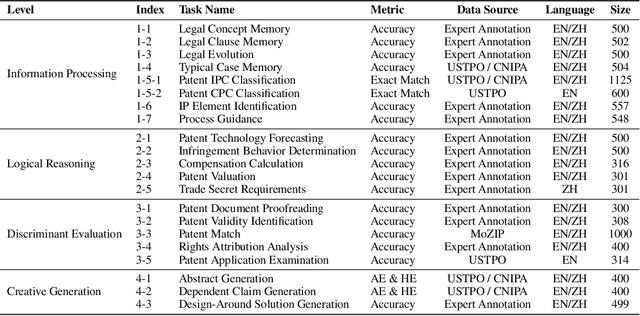
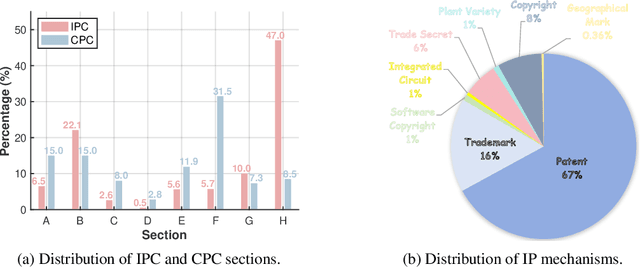
Intellectual Property (IP) is a unique domain that integrates technical and legal knowledge, making it inherently complex and knowledge-intensive. As large language models (LLMs) continue to advance, they show great potential for processing IP tasks, enabling more efficient analysis, understanding, and generation of IP-related content. However, existing datasets and benchmarks either focus narrowly on patents or cover limited aspects of the IP field, lacking alignment with real-world scenarios. To bridge this gap, we introduce the first comprehensive IP task taxonomy and a large, diverse bilingual benchmark, IPBench, covering 8 IP mechanisms and 20 tasks. This benchmark is designed to evaluate LLMs in real-world intellectual property applications, encompassing both understanding and generation. We benchmark 16 LLMs, ranging from general-purpose to domain-specific models, and find that even the best-performing model achieves only 75.8% accuracy, revealing substantial room for improvement. Notably, open-source IP and law-oriented models lag behind closed-source general-purpose models. We publicly release all data and code of IPBench and will continue to update it with additional IP-related tasks to better reflect real-world challenges in the intellectual property domain.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
Med-LEGO: Editing and Adapting toward Generalist Medical Image Diagnosis
Mar 03, 2025


The adoption of visual foundation models has become a common practice in computer-aided diagnosis (CAD). While these foundation models provide a viable solution for creating generalist medical AI, privacy concerns make it difficult to pre-train or continuously update such models across multiple domains and datasets, leading many studies to focus on specialist models. To address this challenge, we propose Med-LEGO, a training-free framework that enables the seamless integration or updating of a generalist CAD model by combining multiple specialist models, similar to assembling LEGO bricks. Med-LEGO enhances LoRA (low-rank adaptation) by incorporating singular value decomposition (SVD) to efficiently capture the domain expertise of each specialist model with minimal additional parameters. By combining these adapted weights through simple operations, Med-LEGO allows for the easy integration or modification of specific diagnostic capabilities without the need for original data or retraining. Finally, the combined model can be further adapted to new diagnostic tasks, making it a versatile generalist model. Our extensive experiments demonstrate that Med-LEGO outperforms existing methods in both cross-domain and in-domain medical tasks while using only 0.18% of full model parameters. These merged models show better convergence and generalization to new tasks, providing an effective path toward generalist medical AI.
MITracker: Multi-View Integration for Visual Object Tracking
Feb 27, 2025Multi-view object tracking (MVOT) offers promising solutions to challenges such as occlusion and target loss, which are common in traditional single-view tracking. However, progress has been limited by the lack of comprehensive multi-view datasets and effective cross-view integration methods. To overcome these limitations, we compiled a Multi-View object Tracking (MVTrack) dataset of 234K high-quality annotated frames featuring 27 distinct objects across various scenes. In conjunction with this dataset, we introduce a novel MVOT method, Multi-View Integration Tracker (MITracker), to efficiently integrate multi-view object features and provide stable tracking outcomes. MITracker can track any object in video frames of arbitrary length from arbitrary viewpoints. The key advancements of our method over traditional single-view approaches come from two aspects: (1) MITracker transforms 2D image features into a 3D feature volume and compresses it into a bird's eye view (BEV) plane, facilitating inter-view information fusion; (2) we propose an attention mechanism that leverages geometric information from fused 3D feature volume to refine the tracking results at each view. MITracker outperforms existing methods on the MVTrack and GMTD datasets, achieving state-of-the-art performance. The code and the new dataset will be available at https://mii-laboratory.github.io/MITracker/.
OpenOmni: Large Language Models Pivot Zero-shot Omnimodal Alignment across Language with Real-time Self-Aware Emotional Speech Synthesis
Jan 08, 2025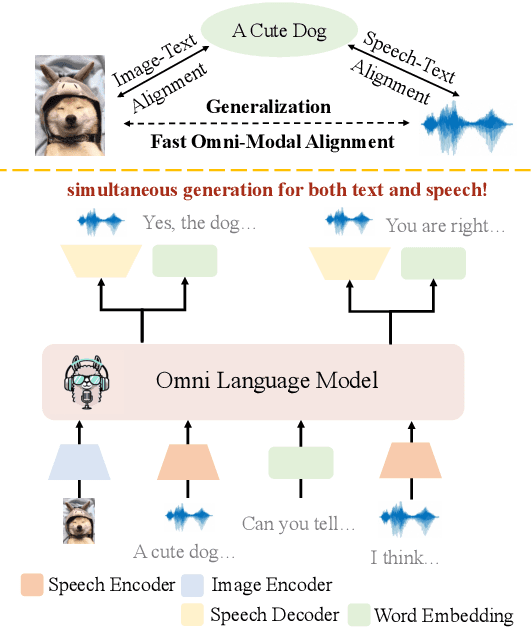
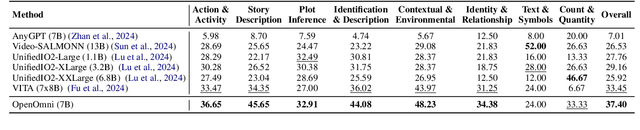
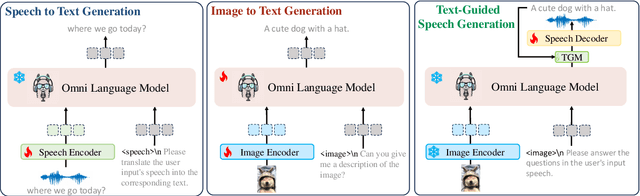

Recent advancements in omnimodal learning have been achieved in understanding and generation across images, text, and speech, though mainly within proprietary models. Limited omnimodal datasets and the inherent challenges associated with real-time emotional speech generation have hindered open-source progress. To address these issues, we propose openomni, a two-stage training method combining omnimodal alignment and speech generation to develop a state-of-the-art omnimodal large language model. In the alignment phase, a pre-trained speech model is further trained on text-image tasks to generalize from vision to speech in a (near) zero-shot manner, outperforming models trained on tri-modal datasets. In the speech generation phase, a lightweight decoder facilitates real-time emotional speech through training on speech tasks and preference learning. Experiments demonstrate that openomni consistently improves across omnimodal, vision-language, and speech-language evaluations, enabling natural, emotion-rich dialogues and real-time emotional speech generation.