 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboBrain 2.0 Technical Report
Jul 02, 2025We introduce RoboBrain 2.0, our latest generation of embodied vision-language foundation models, designed to unify perception, reasoning, and planning for complex embodied tasks in physical environments. It comes in two variants: a lightweight 7B model and a full-scale 32B model, featuring a heterogeneous architecture with a vision encoder and a language model. Despite its compact size, RoboBrain 2.0 achieves strong performance across a wide spectrum of embodied reasoning tasks. On both spatial and temporal benchmarks, the 32B variant achieves leading results, surpassing prior open-source and proprietary models. In particular, it supports key real-world embodied AI capabilities, including spatial understanding (e.g., affordance prediction, spatial referring, trajectory forecasting) and temporal decision-making (e.g., closed-loop interaction, multi-agent long-horizon planning, and scene graph updating). This report details the model architecture, data construction, multi-stage training strategies, infrastructure and practical applications. We hope RoboBrain 2.0 advances embodied AI research and serves as a practical step toward building generalist embodied agents. The code, checkpoint and benchmark are available at https://superrobobrain.github.io.
AutoPatent: A Multi-Agent Framework for Automatic Patent Generation
Dec 13, 2024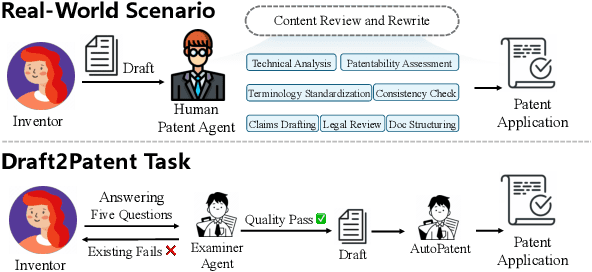
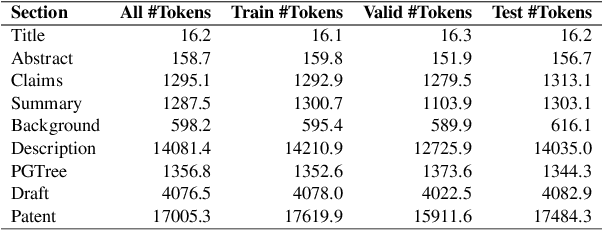
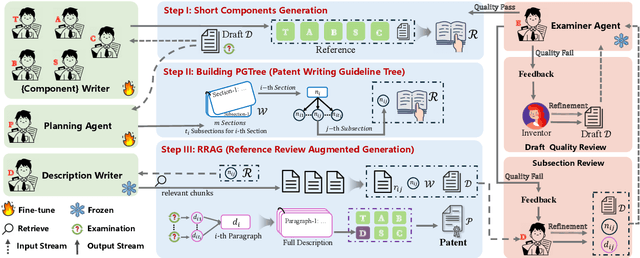
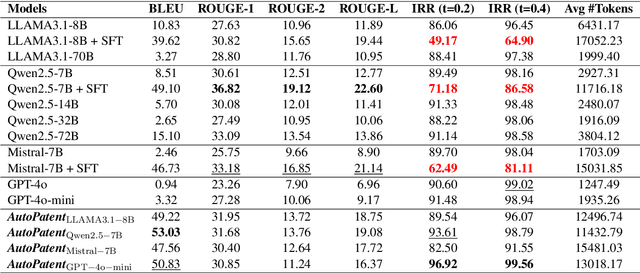
As the capabilities of Large Language Models (LLMs) continue to advance, the field of patent processing has garnered increased attention within the natural language processing community. However, the majority of research has been concentrated on classification tasks, such as patent categorization and examination, or on short text generation tasks like patent summarization and patent quizzes. In this paper, we introduce a novel and practical task known as Draft2Patent, along with its corresponding D2P benchmark, which challenges LLMs to generate full-length patents averaging 17K tokens based on initial drafts. Patents present a significant challenge to LLMs due to their specialized nature, standardized terminology, and extensive length. We propose a multi-agent framework called AutoPatent which leverages the LLM-based planner agent, writer agents, and examiner agent with PGTree and RRAG to generate lengthy, intricate, and high-quality complete patent documents. The experimental results demonstrate that our AutoPatent framework significantly enhances the ability to generate comprehensive patents across various LLMs. Furthermore, we have discovered that patents generated solely with the AutoPatent framework based on the Qwen2.5-7B model outperform those produced by larger and more powerful LLMs, such as GPT-4o, Qwen2.5-72B, and LLAMA3.1-70B, in both objective metrics and human evaluations. We will make the data and code available upon acceptance at \url{https://github.com/QiYao-Wang/AutoPatent}.
Can MLLMs Understand the Deep Implication Behind Chinese Images?
Oct 17, 2024
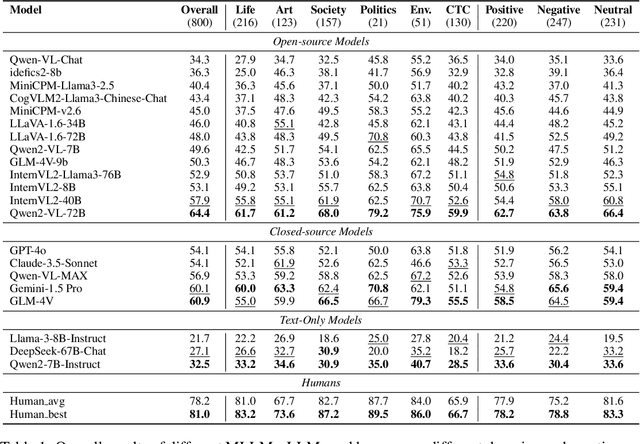
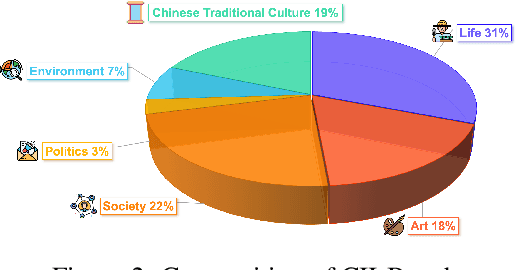
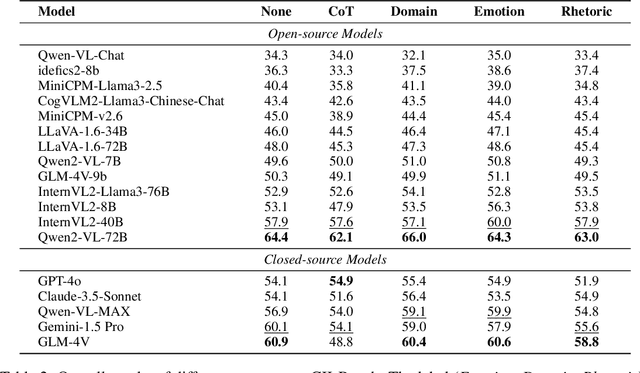
As the capabilities of Multimodal Large Language Models (MLLMs) continue to improve, the need for higher-order capability evaluation of MLLMs is increasing. However, there is a lack of work evaluating MLLM for higher-order perception and understanding of Chinese visual content. To fill the gap, we introduce the **C**hinese **I**mage **I**mplication understanding **Bench**mark, **CII-Bench**, which aims to assess the higher-order perception and understanding capabilities of MLLMs for Chinese images. CII-Bench stands out in several ways compared to existing benchmarks. Firstly, to ensure the authenticity of the Chinese context, images in CII-Bench are sourced from the Chinese Internet and manually reviewed, with corresponding answers also manually crafted. Additionally, CII-Bench incorporates images that represent Chinese traditional culture, such as famous Chinese traditional paintings, which can deeply reflect the model's understanding of Chinese traditional culture. Through extensive experiments on CII-Bench across multiple MLLMs, we have made significant findings. Initially, a substantial gap is observed between the performance of MLLMs and humans on CII-Bench. The highest accuracy of MLLMs attains 64.4%, where as human accuracy averages 78.2%, peaking at an impressive 81.0%. Subsequently, MLLMs perform worse on Chinese traditional culture images, suggesting limitations in their ability to understand high-level semantics and lack a deep knowledge base of Chinese traditional culture. Finally, it is observed that most models exhibit enhanced accuracy when image emotion hints are incorporated into the prompts. We believe that CII-Bench will enable MLLMs to gain a better understanding of Chinese semantics and Chinese-specific images, advancing the journey towards expert artificial general intelligence (AGI). Our project is publicly available at https://cii-bench.github.io/.
II-Bench: An Image Implication Understanding Benchmark for Multimodal Large Language Models
Jun 11, 2024
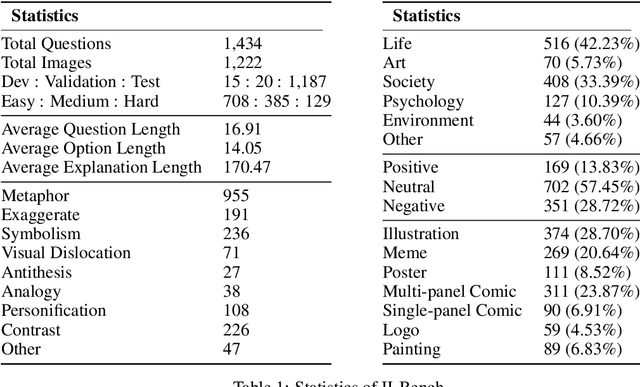
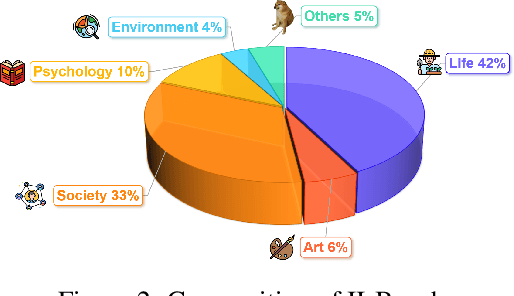
The rapid advancements in the development of multimodal large language models (MLLMs) have consistently led to new breakthroughs on various benchmarks. In response, numerous challenging and comprehensive benchmarks have been proposed to more accurately assess the capabilities of MLLMs. However, there is a dearth of exploration of the higher-order perceptual capabilities of MLLMs. To fill this gap, we propose the Image Implication understanding Benchmark, II-Bench, which aims to evaluate the model's higher-order perception of images. Through extensive experiments on II-Bench across multiple MLLMs, we have made significant findings. Initially, a substantial gap is observed between the performance of MLLMs and humans on II-Bench. The pinnacle accuracy of MLLMs attains 74.8%, whereas human accuracy averages 90%, peaking at an impressive 98%. Subsequently, MLLMs perform worse on abstract and complex images, suggesting limitations in their ability to understand high-level semantics and capture image details. Finally, it is observed that most models exhibit enhanced accuracy when image sentiment polarity hints are incorporated into the prompts. This observation underscores a notable deficiency in their inherent understanding of image sentiment. We believe that II-Bench will inspire the community to develop the next generation of MLLMs, advancing the journey towards expert artificial general intelligence (AGI). II-Bench is publicly available at https://huggingface.co/datasets/m-a-p/II-Bench.
CLHA: A Simple yet Effective Contrastive Learning Framework for Human Alignment
Mar 26, 2024Reinforcement learning from human feedback (RLHF) is a crucial technique in aligning large language models (LLMs) with human preferences, ensuring these LLMs behave in beneficial and comprehensible ways to users. However, a longstanding challenge in human alignment techniques based on reinforcement learning lies in their inherent complexity and difficulty in training. To address this challenge, we present a simple yet effective Contrastive Learning Framework for Human Alignment (CLHA) to align LLMs with human preferences directly. CLHA employs a novel rescoring strategy to evaluate the noise within the data by considering its inherent quality and dynamically adjusting the training process. Simultaneously, CLHA utilizes pairwise contrastive loss and adaptive supervised fine-tuning loss to adaptively modify the likelihood of generating responses, ensuring enhanced alignment with human preferences. Using advanced methods, CLHA surpasses other algorithms, showcasing superior performance in terms of reward model scores, automatic evaluations, and human assessments on the widely used ``Helpful and Harmless'' dataset.
History, Development, and Principles of Large Language Models-An Introductory Survey
Feb 10, 2024
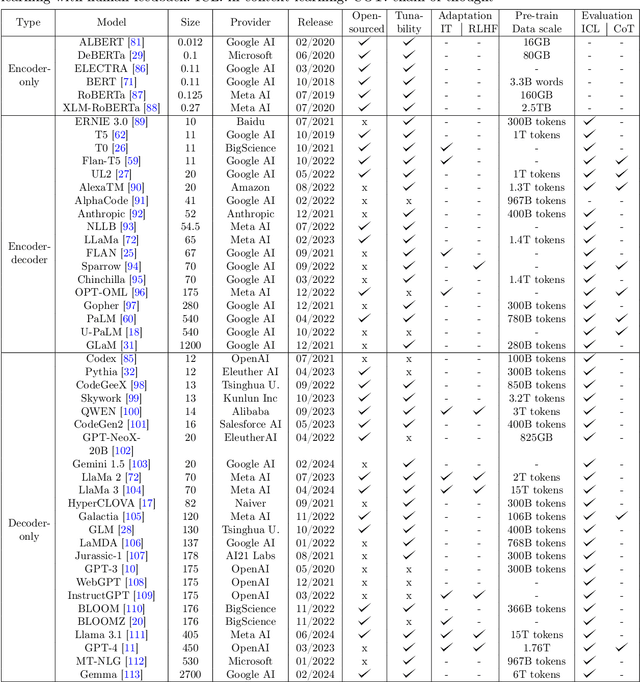


Language models serve as a cornerstone in natural language processing (NLP), utilizing mathematical methods to generalize language laws and knowledge for prediction and generation. Over extensive research spanning decades, language modeling has progressed from initial statistical language models (SLMs) to the contemporary landscape of large language models (LLMs). Notably, the swift evolution of LLMs has reached the ability to process, understand, and generate human-level text. Nevertheless, despite the significant advantages that LLMs offer in improving both work and personal lives, the limited understanding among general practitioners about the background and principles of these models hampers their full potential. Notably, most LLMs reviews focus on specific aspects and utilize specialized language, posing a challenge for practitioners lacking relevant background knowledge. In light of this, this survey aims to present a comprehensible overview of LLMs to assist a broader audience. It strives to facilitate a comprehensive understanding by exploring the historical background of language models and tracing their evolution over time. The survey further investigates the factors influencing the development of LLMs, emphasizing key contributions. Additionally, it concentrates on elucidating the underlying principles of LLMs, equipping audiences with essential theoretical knowledge. The survey also highlights the limitations of existing work and points out promising future directions.