 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARTS: A Dual-View Attack Framework for Targeted Manipulation in Federated Sequential Recommendation
Jul 02, 2025Federated recommendation (FedRec) preserves user privacy by enabling decentralized training of personalized models, but this architecture is inherently vulnerable to adversarial attacks. Significant research has been conducted on targeted attacks in FedRec systems, motivated by commercial and social influence considerations. However, much of this work has largely overlooked the differential robustness of recommendation models. Moreover, our empirical findings indicate that existing targeted attack methods achieve only limited effectiveness in Federated Sequential Recommendation(FSR) tasks. Driven by these observations, we focus on investigating targeted attacks in FSR and propose a novel dualview attack framework, named DV-FSR. This attack method uniquely combines a sampling-based explicit strategy with a contrastive learning-based implicit gradient strategy to orchestrate a coordinated attack. Additionally, we introduce a specific defense mechanism tailored for targeted attacks in FSR, aiming to evaluate the mitigation effects of the attack method we proposed. Extensive experiments validate the effectiveness of our proposed approach on representative sequential models. Our codes are publicly available.
Leveraging Prior Experience: An Expandable Auxiliary Knowledge Base for Text-to-SQL
Nov 20, 2024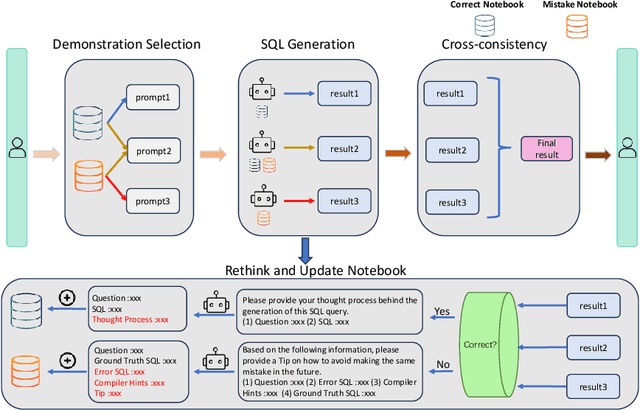

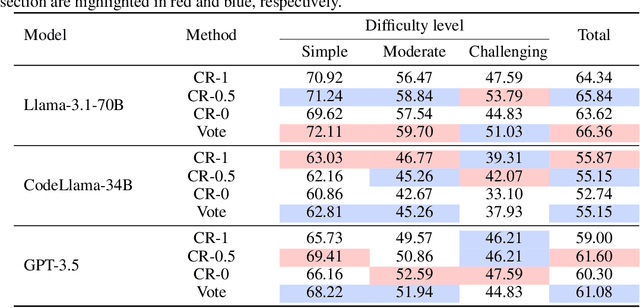

Large Language Models (LLMs) exhibit impressive problem-solving skills across many tasks, but they still underperform compared to humans in various downstream applications, such as text-to-SQL. On the BIRD benchmark leaderboard, human performance achieves an accuracy of 92.96\%, whereas the top-performing method reaches only 72.39\%. Notably, these state-of-the-art (SoTA) methods predominantly rely on in-context learning to simulate human-like reasoning. However, they overlook a critical human skill: continual learning. Inspired by the educational practice of maintaining mistake notebooks during our formative years, we propose LPE-SQL (Leveraging Prior Experience: An Expandable Auxiliary Knowledge Base for Text-to-SQL), a novel framework designed to augment LLMs by enabling continual learning without requiring parameter fine-tuning. LPE-SQL consists of four modules that \textbf{i)} retrieve relevant entries, \textbf{ii)} efficient sql generation, \textbf{iii)} generate the final result through a cross-consistency mechanism and \textbf{iv)} log successful and failed tasks along with their reasoning processes or reflection-generated tips. Importantly, the core module of LPE-SQL is the fourth one, while the other modules employ foundational methods, allowing LPE-SQL to be easily integrated with SoTA technologies to further enhance performance. Our experimental results demonstrate that this continual learning approach yields substantial performance gains, with the smaller Llama-3.1-70B model with surpassing the performance of the larger Llama-3.1-405B model using SoTA methods.
Fairness Definitions in Language Models Explained
Jul 26, 2024



Language Models (LMs) have demonstrated exceptional performance across various Natural Language Processing (NLP) tasks. Despite these advancements, LMs can inherit and amplify societal biases related to sensitive attributes such as gender and race, limiting their adoption in real-world applications. Therefore, fairness has been extensively explored in LMs, leading to the proposal of various fairness notions. However, the lack of clear agreement on which fairness definition to apply in specific contexts (\textit{e.g.,} medium-sized LMs versus large-sized LMs) and the complexity of understanding the distinctions between these definitions can create confusion and impede further progress. To this end, this paper proposes a systematic survey that clarifies the definitions of fairness as they apply to LMs. Specifically, we begin with a brief introduction to LMs and fairness in LMs, followed by a comprehensive, up-to-date overview of existing fairness notions in LMs and the introduction of a novel taxonomy that categorizes these concepts based on their foundational principles and operational distinctions. We further illustrate each definition through experiments, showcasing their practical implications and outcomes. Finally, we discuss current research challenges and open questions, aiming to foster innovative ideas and advance the field. The implementation and additional resources are publicly available at https://github.com/LavinWong/Fairness-in-Large-Language-Models/tree/main/definitions.
Fairness in Large Language Models: A Taxonomic Survey
Mar 31, 2024Large Language Models (LLMs) have demonstrated remarkable success across various domains. However, despite their promising performance in numerous real-world applications, most of these algorithms lack fairness considerations. Consequently, they may lead to discriminatory outcomes against certain communities, particularly marginalized populations, prompting extensive study in fair LLMs. On the other hand, fairness in LLMs, in contrast to fairness in traditional machine learning, entails exclusive backgrounds, taxonomies, and fulfillment techniques. To this end, this survey presents a comprehensive overview of recent advances in the existing literature concerning fair LLMs. Specifically, a brief introduction to LLMs is provided, followed by an analysis of factors contributing to bias in LLMs. Additionally, the concept of fairness in LLMs is discussed categorically, summarizing metrics for evaluating bias in LLMs and existing algorithms for promoting fairness. Furthermore, resources for evaluating bias in LLMs, including toolkits and datasets, are summarized. Finally, existing research challenges and open questions are discussed.
History, Development, and Principles of Large Language Models-An Introductory Survey
Feb 10, 2024
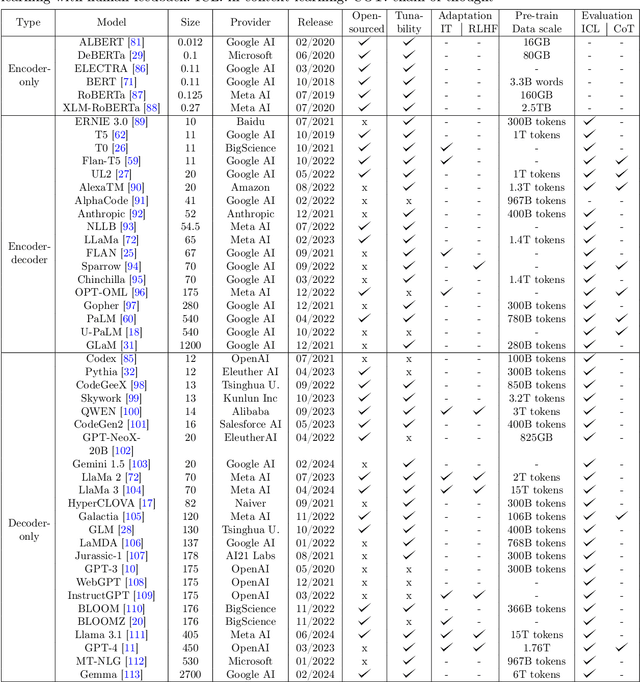


Language models serve as a cornerstone in natural language processing (NLP), utilizing mathematical methods to generalize language laws and knowledge for prediction and generation. Over extensive research spanning decades, language modeling has progressed from initial statistical language models (SLMs) to the contemporary landscape of large language models (LLMs). Notably, the swift evolution of LLMs has reached the ability to process, understand, and generate human-level text. Nevertheless, despite the significant advantages that LLMs offer in improving both work and personal lives, the limited understanding among general practitioners about the background and principles of these models hampers their full potential. Notably, most LLMs reviews focus on specific aspects and utilize specialized language, posing a challenge for practitioners lacking relevant background knowledge. In light of this, this survey aims to present a comprehensible overview of LLMs to assist a broader audience. It strives to facilitate a comprehensive understanding by exploring the historical background of language models and tracing their evolution over time. The survey further investigates the factors influencing the development of LLMs, emphasizing key contributions. Additionally, it concentrates on elucidating the underlying principles of LLMs, equipping audiences with essential theoretical knowledge. The survey also highlights the limitations of existing work and points out promising future directions.