 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARTS: A Dual-View Attack Framework for Targeted Manipulation in Federated Sequential Recommendation
Jul 02, 2025Federated recommendation (FedRec) preserves user privacy by enabling decentralized training of personalized models, but this architecture is inherently vulnerable to adversarial attacks. Significant research has been conducted on targeted attacks in FedRec systems, motivated by commercial and social influence considerations. However, much of this work has largely overlooked the differential robustness of recommendation models. Moreover, our empirical findings indicate that existing targeted attack methods achieve only limited effectiveness in Federated Sequential Recommendation(FSR) tasks. Driven by these observations, we focus on investigating targeted attacks in FSR and propose a novel dualview attack framework, named DV-FSR. This attack method uniquely combines a sampling-based explicit strategy with a contrastive learning-based implicit gradient strategy to orchestrate a coordinated attack. Additionally, we introduce a specific defense mechanism tailored for targeted attacks in FSR, aiming to evaluate the mitigation effects of the attack method we proposed. Extensive experiments validate the effectiveness of our proposed approach on representative sequential models. Our codes are publicly available.
Molar: Multimodal LLMs with Collaborative Filtering Alignment for Enhanced Sequential Recommendation
Dec 24, 2024Sequential recommendation (SR) systems have evolved significantly over the past decade, transitioning from traditional collaborative filtering to deep learning approaches and, more recently, to large language models (LLMs). While the adoption of LLMs has driven substantial advancements, these models inherently lack collaborative filtering information, relying primarily on textual content data neglecting other modalities and thus failing to achieve optimal recommendation performance. To address this limitation, we propose Molar, a Multimodal large language sequential recommendation framework that integrates multiple content modalities with ID information to capture collaborative signals effectively. Molar employs an MLLM to generate unified item representations from both textual and non-textual data, facilitating comprehensive multimodal modeling and enriching item embeddings. Additionally, it incorporates collaborative filtering signals through a post-alignment mechanism, which aligns user representations from content-based and ID-based models, ensuring precise personalization and robust performance. By seamlessly combining multimodal content with collaborative filtering insights, Molar captures both user interests and contextual semantics, leading to superior recommendation accuracy. Extensive experiments validate that Molar significantly outperforms traditional and LLM-based baselines, highlighting its strength in utilizing multimodal data and collaborative signals for sequential recommendation tasks. The source code is available at https://anonymous.4open.science/r/Molar-8B06/.
Leveraging Prior Experience: An Expandable Auxiliary Knowledge Base for Text-to-SQL
Nov 20, 2024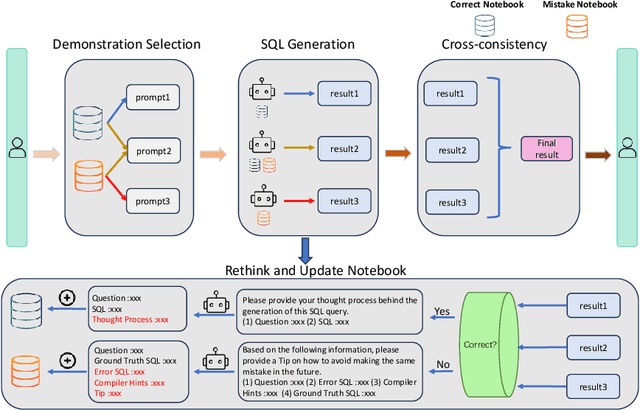

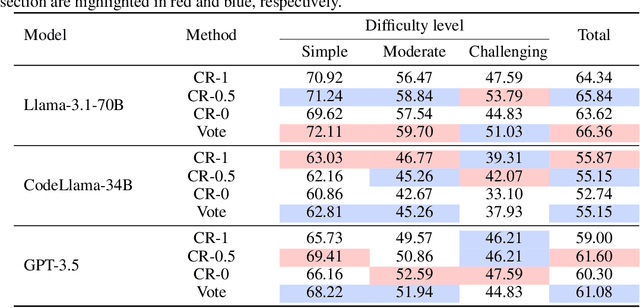

Large Language Models (LLMs) exhibit impressive problem-solving skills across many tasks, but they still underperform compared to humans in various downstream applications, such as text-to-SQL. On the BIRD benchmark leaderboard, human performance achieves an accuracy of 92.96\%, whereas the top-performing method reaches only 72.39\%. Notably, these state-of-the-art (SoTA) methods predominantly rely on in-context learning to simulate human-like reasoning. However, they overlook a critical human skill: continual learning. Inspired by the educational practice of maintaining mistake notebooks during our formative years, we propose LPE-SQL (Leveraging Prior Experience: An Expandable Auxiliary Knowledge Base for Text-to-SQL), a novel framework designed to augment LLMs by enabling continual learning without requiring parameter fine-tuning. LPE-SQL consists of four modules that \textbf{i)} retrieve relevant entries, \textbf{ii)} efficient sql generation, \textbf{iii)} generate the final result through a cross-consistency mechanism and \textbf{iv)} log successful and failed tasks along with their reasoning processes or reflection-generated tips. Importantly, the core module of LPE-SQL is the fourth one, while the other modules employ foundational methods, allowing LPE-SQL to be easily integrated with SoTA technologies to further enhance performance. Our experimental results demonstrate that this continual learning approach yields substantial performance gains, with the smaller Llama-3.1-70B model with surpassing the performance of the larger Llama-3.1-405B model using SoTA methods.
DV-FSR: A Dual-View Target Attack Framework for Federated Sequential Recommendation
Sep 10, 2024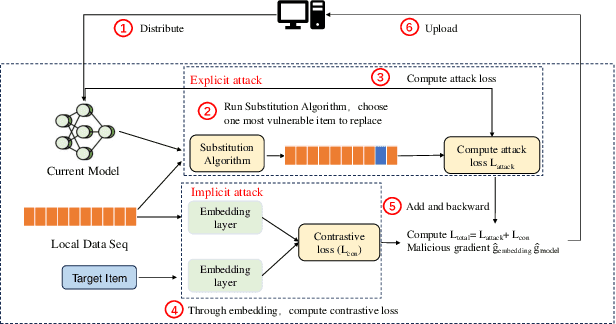
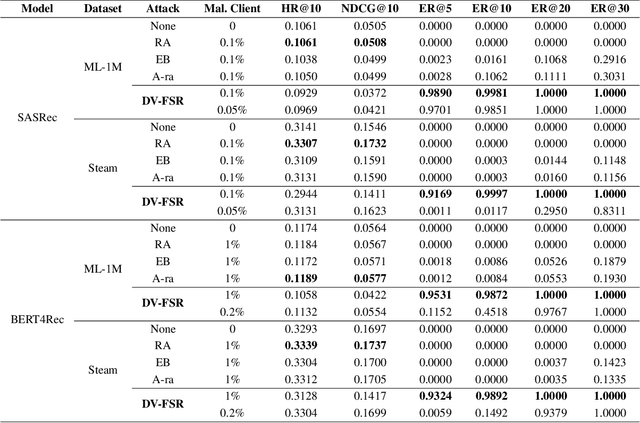

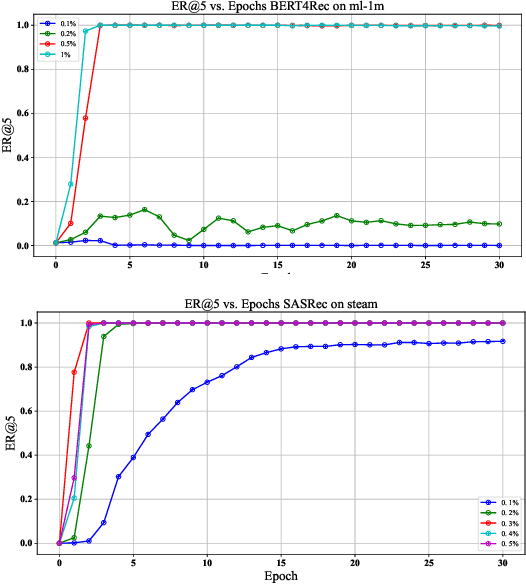
Federated recommendation (FedRec) preserves user privacy by enabling decentralized training of personalized models, but this architecture is inherently vulnerable to adversarial attacks. Significant research has been conducted on targeted attacks in FedRec systems, motivated by commercial and social influence considerations. However, much of this work has largely overlooked the differential robustness of recommendation models. Moreover, our empirical findings indicate that existing targeted attack methods achieve only limited effectiveness in Federated Sequential Recommendation (FSR) tasks. Driven by these observations, we focus on investigating targeted attacks in FSR and propose a novel dualview attack framework, named DV-FSR. This attack method uniquely combines a sampling-based explicit strategy with a contrastive learning-based implicit gradient strategy to orchestrate a coordinated attack. Additionally, we introduce a specific defense mechanism tailored for targeted attacks in FSR, aiming to evaluate the mitigation effects of the attack method we proposed. Extensive experiments validate the effectiveness of our proposed approach on representative sequential models.