 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Practical Large-scale Dynamical Heterogeneous Graph Embedding: Cold-start Resilient Recommendation
Dec 15, 2025Deploying dynamic heterogeneous graph embeddings in production faces key challenges of scalability, data freshness, and cold-start. This paper introduces a practical, two-stage solution that balances deep graph representation with low-latency incremental updates. Our framework combines HetSGFormer, a scalable graph transformer for static learning, with Incremental Locally Linear Embedding (ILLE), a lightweight, CPU-based algorithm for real-time updates. HetSGFormer captures global structure with linear scalability, while ILLE provides rapid, targeted updates to incorporate new data, thus avoiding costly full retraining. This dual approach is cold-start resilient, leveraging the graph to create meaningful embeddings from sparse data. On billion-scale graphs, A/B tests show HetSGFormer achieved up to a 6.11% lift in Advertiser Value over previous methods, while the ILLE module added another 3.22% lift and improved embedding refresh timeliness by 83.2%. Our work provides a validated framework for deploying dynamic graph learning in production environments.
DAMS:Dual-Branch Adaptive Multiscale Spatiotemporal Framework for Video Anomaly Detection
Jul 28, 2025



The goal of video anomaly detection is tantamount to performing spatio-temporal localization of abnormal events in the video. The multiscale temporal dependencies, visual-semantic heterogeneity, and the scarcity of labeled data exhibited by video anomalies collectively present a challenging research problem in computer vision. This study offers a dual-path architecture called the Dual-Branch Adaptive Multiscale Spatiotemporal Framework (DAMS), which is based on multilevel feature decoupling and fusion, enabling efficient anomaly detection modeling by integrating hierarchical feature learning and complementary information. The main processing path of this framework integrates the Adaptive Multiscale Time Pyramid Network (AMTPN) with the Convolutional Block Attention Mechanism (CBAM). AMTPN enables multigrained representation and dynamically weighted reconstruction of temporal features through a three-level cascade structure (time pyramid pooling, adaptive feature fusion, and temporal context enhancement). CBAM maximizes the entropy distribution of feature channels and spatial dimensions through dual attention mapping. Simultaneously, the parallel path driven by CLIP introduces a contrastive language-visual pre-training paradigm. Cross-modal semantic alignment and a multiscale instance selection mechanism provide high-order semantic guidance for spatio-temporal features. This creates a complete inference chain from the underlying spatio-temporal features to high-level semantic concepts. The orthogonal complementarity of the two paths and the information fusion mechanism jointly construct a comprehensive representation and identification capability for anomalous events. Extensive experimental results on the UCF-Crime and XD-Violence benchmarks establish the effectiveness of the DAMS framework.
DLF: Enhancing Explicit-Implicit Interaction via Dynamic Low-Order-Aware Fusion for CTR Prediction
May 25, 2025Click-through rate (CTR) prediction is a critical task in online advertising and recommender systems, relying on effective modeling of feature interactions. Explicit interactions capture predefined relationships, such as inner products, but often suffer from data sparsity, while implicit interactions excel at learning complex patterns through non-linear transformations but lack inductive biases for efficient low-order modeling. Existing two-stream architectures integrate these paradigms but face challenges such as limited information sharing, gradient imbalance, and difficulty preserving low-order signals in sparse CTR data. We propose a novel framework, Dynamic Low-Order-Aware Fusion (DLF), which addresses these limitations through two key components: a Residual-Aware Low-Order Interaction Network (RLI) and a Network-Aware Attention Fusion Module (NAF). RLI explicitly preserves low-order signals while mitigating redundancy from residual connections, and NAF dynamically integrates explicit and implicit representations at each layer, enhancing information sharing and alleviating gradient imbalance. Together, these innovations balance low-order and high-order interactions, improving model expressiveness. Extensive experiments on public datasets demonstrate that DLF achieves state-of-the-art performance in CTR prediction, addressing key limitations of existing models. The implementation is publicly available at https://github.com/USTC-StarTeam/DLF.
A Universal Framework for Compressing Embeddings in CTR Prediction
Feb 21, 2025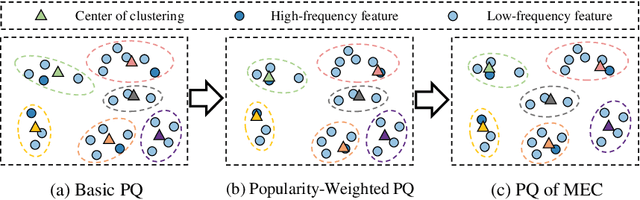
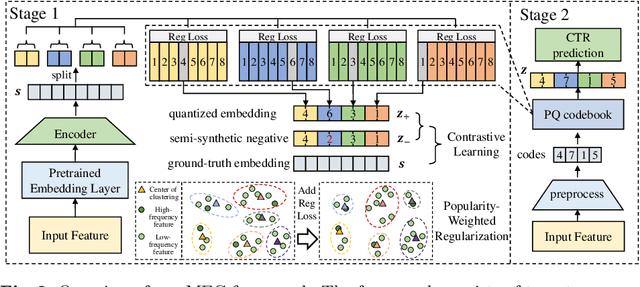
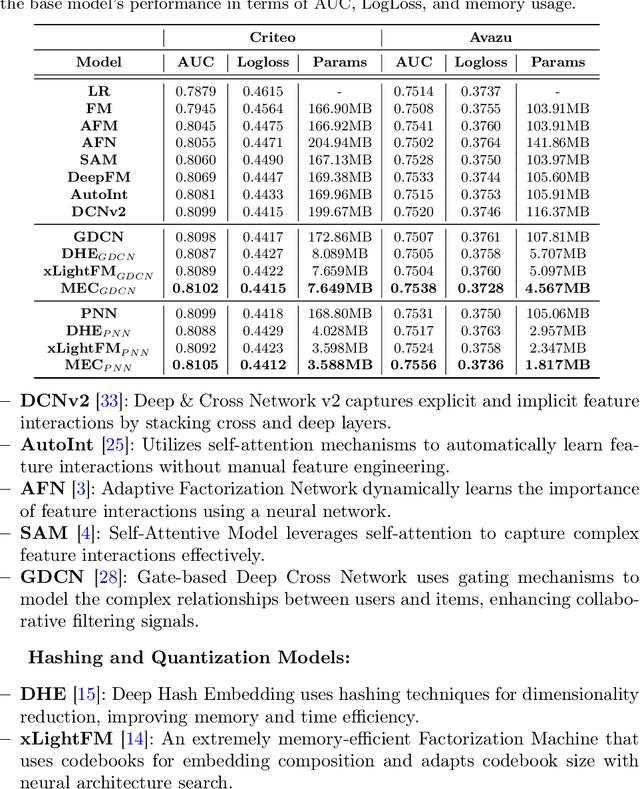
Accurate click-through rate (CTR) prediction is vital for online advertising and recommendation systems. Recent deep learning advancements have improved the ability to capture feature interactions and understand user interests. However, optimizing the embedding layer often remains overlooked. Embedding tables, which represent categorical and sequential features, can become excessively large, surpassing GPU memory limits and necessitating storage in CPU memory. This results in high memory consumption and increased latency due to frequent GPU-CPU data transfers. To tackle these challenges, we introduce a Model-agnostic Embedding Compression (MEC) framework that compresses embedding tables by quantizing pre-trained embeddings, without sacrificing recommendation quality. Our approach consists of two stages: first, we apply popularity-weighted regularization to balance code distribution between high- and low-frequency features. Then, we integrate a contrastive learning mechanism to ensure a uniform distribution of quantized codes, enhancing the distinctiveness of embeddings. Experiments on three datasets reveal that our method reduces memory usage by over 50x while maintaining or improving recommendation performance compared to existing models. The implementation code is accessible in our project repository https://github.com/USTC-StarTeam/MEC.
Molar: Multimodal LLMs with Collaborative Filtering Alignment for Enhanced Sequential Recommendation
Dec 24, 2024Sequential recommendation (SR) systems have evolved significantly over the past decade, transitioning from traditional collaborative filtering to deep learning approaches and, more recently, to large language models (LLMs). While the adoption of LLMs has driven substantial advancements, these models inherently lack collaborative filtering information, relying primarily on textual content data neglecting other modalities and thus failing to achieve optimal recommendation performance. To address this limitation, we propose Molar, a Multimodal large language sequential recommendation framework that integrates multiple content modalities with ID information to capture collaborative signals effectively. Molar employs an MLLM to generate unified item representations from both textual and non-textual data, facilitating comprehensive multimodal modeling and enriching item embeddings. Additionally, it incorporates collaborative filtering signals through a post-alignment mechanism, which aligns user representations from content-based and ID-based models, ensuring precise personalization and robust performance. By seamlessly combining multimodal content with collaborative filtering insights, Molar captures both user interests and contextual semantics, leading to superior recommendation accuracy. Extensive experiments validate that Molar significantly outperforms traditional and LLM-based baselines, highlighting its strength in utilizing multimodal data and collaborative signals for sequential recommendation tasks. The source code is available at https://anonymous.4open.science/r/Molar-8B06/.
Scaling New Frontiers: Insights into Large Recommendation Models
Dec 01, 2024



Recommendation systems are essential for filtering data and retrieving relevant information across various applications. Recent advancements have seen these systems incorporate increasingly large embedding tables, scaling up to tens of terabytes for industrial use. However, the expansion of network parameters in traditional recommendation models has plateaued at tens of millions, limiting further benefits from increased embedding parameters. Inspired by the success of large language models (LLMs), a new approach has emerged that scales network parameters using innovative structures, enabling continued performance improvements. A significant development in this area is Meta's generative recommendation model HSTU, which illustrates the scaling laws of recommendation systems by expanding parameters to thousands of billions. This new paradigm has achieved substantial performance gains in online experiments. In this paper, we aim to enhance the understanding of scaling laws by conducting comprehensive evaluations of large recommendation models. Firstly, we investigate the scaling laws across different backbone architectures of the large recommendation models. Secondly, we conduct comprehensive ablation studies to explore the origins of these scaling laws. We then further assess the performance of HSTU, as the representative of large recommendation models, on complex user behavior modeling tasks to evaluate its applicability. Notably, we also analyze its effectiveness in ranking tasks for the first time. Finally, we offer insights into future directions for large recommendation models. Supplementary materials for our research are available on GitHub at https://github.com/USTC-StarTeam/Large-Recommendation-Models.
Denoising Pre-Training and Customized Prompt Learning for Efficient Multi-Behavior Sequential Recommendation
Aug 21, 2024

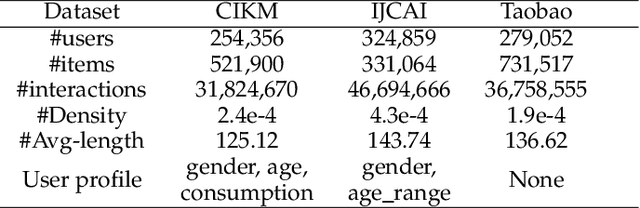
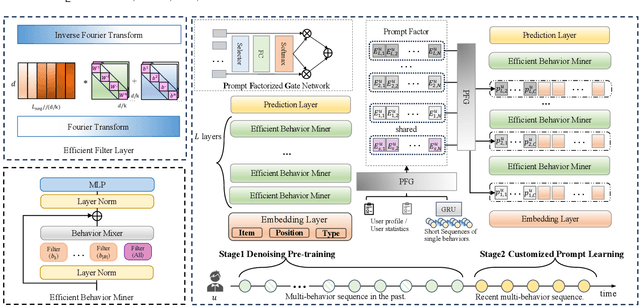
In the realm of recommendation systems, users exhibit a diverse array of behaviors when interacting with items. This phenomenon has spurred research into learning the implicit semantic relationships between these behaviors to enhance recommendation performance. However, these methods often entail high computational complexity. To address concerns regarding efficiency, pre-training presents a viable solution. Its objective is to extract knowledge from extensive pre-training data and fine-tune the model for downstream tasks. Nevertheless, previous pre-training methods have primarily focused on single-behavior data, while multi-behavior data contains significant noise. Additionally, the fully fine-tuning strategy adopted by these methods still imposes a considerable computational burden. In response to this challenge, we propose DPCPL, the first pre-training and prompt-tuning paradigm tailored for Multi-Behavior Sequential Recommendation. Specifically, in the pre-training stage, we commence by proposing a novel Efficient Behavior Miner (EBM) to filter out the noise at multiple time scales, thereby facilitating the comprehension of the contextual semantics of multi-behavior sequences. Subsequently, we propose to tune the pre-trained model in a highly efficient manner with the proposed Customized Prompt Learning (CPL) module, which generates personalized, progressive, and diverse prompts to fully exploit the potential of the pre-trained model effectively. Extensive experiments on three real-world datasets have unequivocally demonstrated that DPCPL not only exhibits high efficiency and effectiveness, requiring minimal parameter adjustments but also surpasses the state-of-the-art performance across a diverse range of downstream tasks.
END4Rec: Efficient Noise-Decoupling for Multi-Behavior Sequential Recommendation
Mar 26, 2024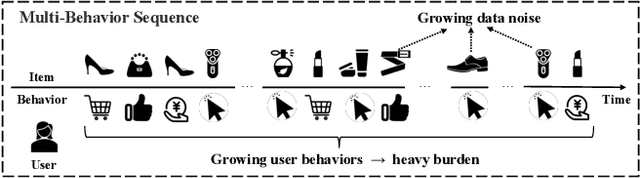
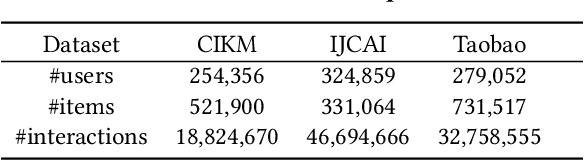
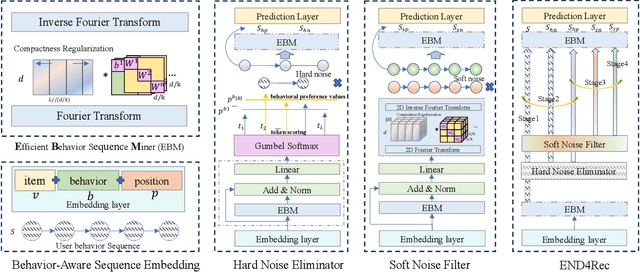
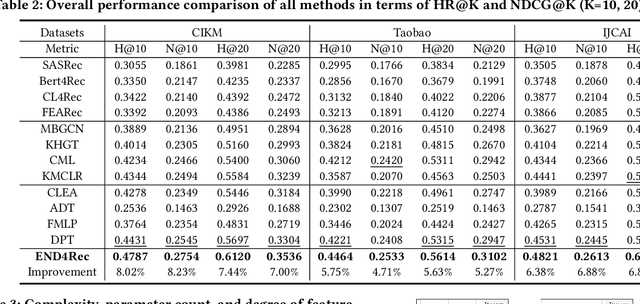
In recommendation systems, users frequently engage in multiple types of behaviors, such as clicking, adding to a cart, and purchasing. However, with diversified behavior data, user behavior sequences will become very long in the short term, which brings challenges to the efficiency of the sequence recommendation model. Meanwhile, some behavior data will also bring inevitable noise to the modeling of user interests. To address the aforementioned issues, firstly, we develop the Efficient Behavior Sequence Miner (EBM) that efficiently captures intricate patterns in user behavior while maintaining low time complexity and parameter count. Secondly, we design hard and soft denoising modules for different noise types and fully explore the relationship between behaviors and noise. Finally, we introduce a contrastive loss function along with a guided training strategy to compare the valid information in the data with the noisy signal, and seamlessly integrate the two denoising processes to achieve a high degree of decoupling of the noisy signal. Sufficient experiments on real-world datasets demonstrate the effectiveness and efficiency of our approach in dealing with multi-behavior sequential recommendation.