 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKilling Two Birds with One Stone: Unifying Retrieval and Ranking with a Single Generative Recommendation Model
Apr 23, 2025In recommendation systems, the traditional multi-stage paradigm, which includes retrieval and ranking, often suffers from information loss between stages and diminishes performance. Recent advances in generative models, inspired by natural language processing, suggest the potential for unifying these stages to mitigate such loss. This paper presents the Unified Generative Recommendation Framework (UniGRF), a novel approach that integrates retrieval and ranking into a single generative model. By treating both stages as sequence generation tasks, UniGRF enables sufficient information sharing without additional computational costs, while remaining model-agnostic. To enhance inter-stage collaboration, UniGRF introduces a ranking-driven enhancer module that leverages the precision of the ranking stage to refine retrieval processes, creating an enhancement loop. Besides, a gradient-guided adaptive weighter is incorporated to dynamically balance the optimization of retrieval and ranking, ensuring synchronized performance improvements. Extensive experiments demonstrate that UniGRF significantly outperforms existing models on benchmark datasets, confirming its effectiveness in facilitating information transfer. Ablation studies and further experiments reveal that UniGRF not only promotes efficient collaboration between stages but also achieves synchronized optimization. UniGRF provides an effective, scalable, and compatible framework for generative recommendation systems.
A Multi-Agent Framework Integrating Large Language Models and Generative AI for Accelerated Metamaterial Design
Mar 25, 2025



Metamaterials, renowned for their exceptional mechanical, electromagnetic, and thermal properties, hold transformative potential across diverse applications, yet their design remains constrained by labor-intensive trial-and-error methods and limited data interoperability. Here, we introduce CrossMatAgent--a novel multi-agent framework that synergistically integrates large language models with state-of-the-art generative AI to revolutionize metamaterial design. By orchestrating a hierarchical team of agents--each specializing in tasks such as pattern analysis, architectural synthesis, prompt engineering, and supervisory feedback--our system leverages the multimodal reasoning of GPT-4o alongside the generative precision of DALL-E 3 and a fine-tuned Stable Diffusion XL model. This integrated approach automates data augmentation, enhances design fidelity, and produces simulation- and 3D printing-ready metamaterial patterns. Comprehensive evaluations, including CLIP-based alignment, SHAP interpretability analyses, and mechanical simulations under varied load conditions, demonstrate the framework's ability to generate diverse, reproducible, and application-ready designs. CrossMatAgent thus establishes a scalable, AI-driven paradigm that bridges the gap between conceptual innovation and practical realization, paving the way for accelerated metamaterial development.
A Universal Framework for Compressing Embeddings in CTR Prediction
Feb 21, 2025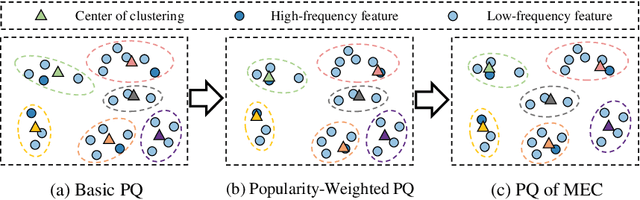
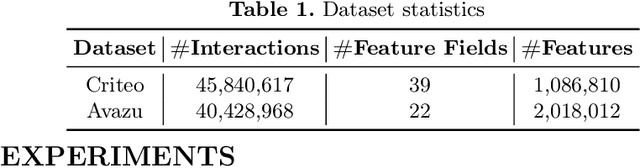
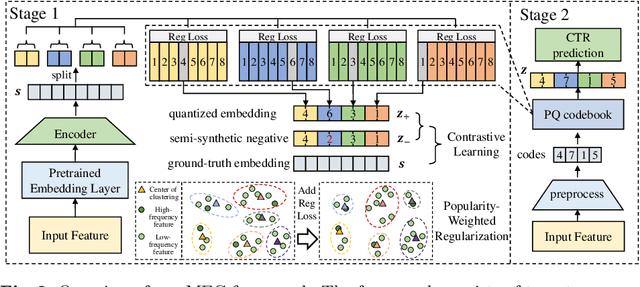
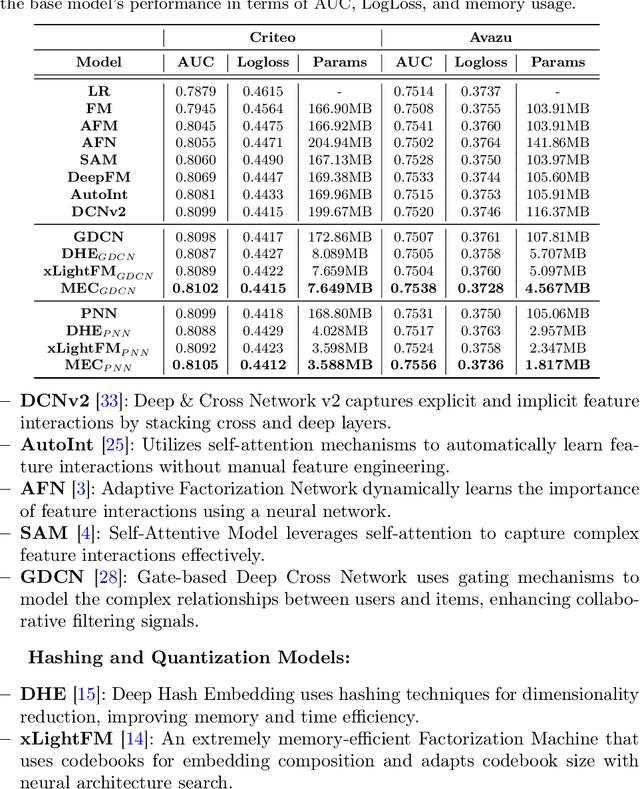
Accurate click-through rate (CTR) prediction is vital for online advertising and recommendation systems. Recent deep learning advancements have improved the ability to capture feature interactions and understand user interests. However, optimizing the embedding layer often remains overlooked. Embedding tables, which represent categorical and sequential features, can become excessively large, surpassing GPU memory limits and necessitating storage in CPU memory. This results in high memory consumption and increased latency due to frequent GPU-CPU data transfers. To tackle these challenges, we introduce a Model-agnostic Embedding Compression (MEC) framework that compresses embedding tables by quantizing pre-trained embeddings, without sacrificing recommendation quality. Our approach consists of two stages: first, we apply popularity-weighted regularization to balance code distribution between high- and low-frequency features. Then, we integrate a contrastive learning mechanism to ensure a uniform distribution of quantized codes, enhancing the distinctiveness of embeddings. Experiments on three datasets reveal that our method reduces memory usage by over 50x while maintaining or improving recommendation performance compared to existing models. The implementation code is accessible in our project repository https://github.com/USTC-StarTeam/MEC.
Large Language Models for Bioinformatics
Jan 10, 2025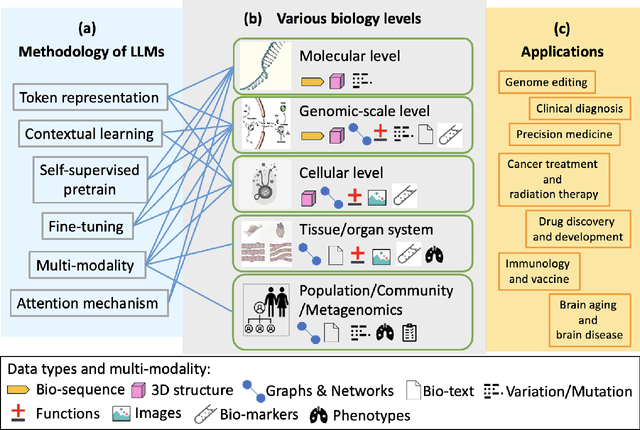
With the rapid advancements in large language model (LLM) technology and the emergence of bioinformatics-specific language models (BioLMs), there is a growing need for a comprehensive analysis of the current landscape, computational characteristics, and diverse applications. This survey aims to address this need by providing a thorough review of BioLMs, focusing on their evolution, classification, and distinguishing features, alongside a detailed examination of training methodologies, datasets, and evaluation frameworks. We explore the wide-ranging applications of BioLMs in critical areas such as disease diagnosis, drug discovery, and vaccine development, highlighting their impact and transformative potential in bioinformatics. We identify key challenges and limitations inherent in BioLMs, including data privacy and security concerns, interpretability issues, biases in training data and model outputs, and domain adaptation complexities. Finally, we highlight emerging trends and future directions, offering valuable insights to guide researchers and clinicians toward advancing BioLMs for increasingly sophisticated biological and clinical applications.
Scaling New Frontiers: Insights into Large Recommendation Models
Dec 01, 2024



Recommendation systems are essential for filtering data and retrieving relevant information across various applications. Recent advancements have seen these systems incorporate increasingly large embedding tables, scaling up to tens of terabytes for industrial use. However, the expansion of network parameters in traditional recommendation models has plateaued at tens of millions, limiting further benefits from increased embedding parameters. Inspired by the success of large language models (LLMs), a new approach has emerged that scales network parameters using innovative structures, enabling continued performance improvements. A significant development in this area is Meta's generative recommendation model HSTU, which illustrates the scaling laws of recommendation systems by expanding parameters to thousands of billions. This new paradigm has achieved substantial performance gains in online experiments. In this paper, we aim to enhance the understanding of scaling laws by conducting comprehensive evaluations of large recommendation models. Firstly, we investigate the scaling laws across different backbone architectures of the large recommendation models. Secondly, we conduct comprehensive ablation studies to explore the origins of these scaling laws. We then further assess the performance of HSTU, as the representative of large recommendation models, on complex user behavior modeling tasks to evaluate its applicability. Notably, we also analyze its effectiveness in ranking tasks for the first time. Finally, we offer insights into future directions for large recommendation models. Supplementary materials for our research are available on GitHub at https://github.com/USTC-StarTeam/Large-Recommendation-Models.
Large Language Models for Manufacturing
Oct 28, 2024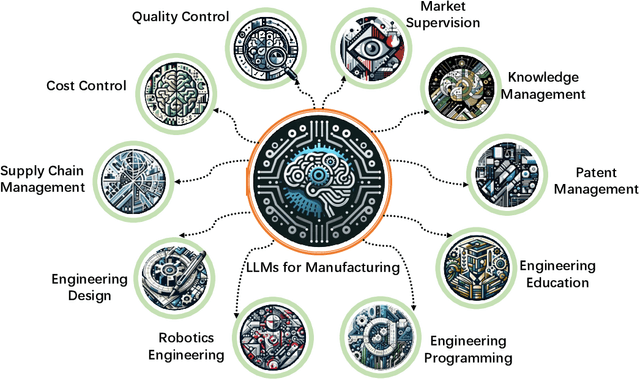


The rapid advances in Large Language Models (LLMs) have the potential to transform manufacturing industry, offering new opportunities to optimize processes, improve efficiency, and drive innovation. This paper provides a comprehensive exploration of the integration of LLMs into the manufacturing domain, focusing on their potential to automate and enhance various aspects of manufacturing, from product design and development to quality control, supply chain optimization, and talent management. Through extensive evaluations across multiple manufacturing tasks, we demonstrate the remarkable capabilities of state-of-the-art LLMs, such as GPT-4V, in understanding and executing complex instructions, extracting valuable insights from vast amounts of data, and facilitating knowledge sharing. We also delve into the transformative potential of LLMs in reshaping manufacturing education, automating coding processes, enhancing robot control systems, and enabling the creation of immersive, data-rich virtual environments through the industrial metaverse. By highlighting the practical applications and emerging use cases of LLMs in manufacturing, this paper aims to provide a valuable resource for professionals, researchers, and decision-makers seeking to harness the power of these technologies to address real-world challenges, drive operational excellence, and unlock sustainable growth in an increasingly competitive landscape.