 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenKI: Enhancing Open-Domain Question Answering with Knowledge Integration and Controllable Generation in Large Language Models
May 26, 2025Open-domain question answering (OpenQA) represents a cornerstone in natural language processing (NLP), primarily focused on extracting answers from unstructured textual data. With the rapid advancements in Large Language Models (LLMs), LLM-based OpenQA methods have reaped the benefits of emergent understanding and answering capabilities enabled by massive parameters compared to traditional methods. However, most of these methods encounter two critical challenges: how to integrate knowledge into LLMs effectively and how to adaptively generate results with specific answer formats for various task situations. To address these challenges, we propose a novel framework named GenKI, which aims to improve the OpenQA performance by exploring Knowledge Integration and controllable Generation on LLMs simultaneously. Specifically, we first train a dense passage retrieval model to retrieve associated knowledge from a given knowledge base. Subsequently, we introduce a novel knowledge integration model that incorporates the retrieval knowledge into instructions during fine-tuning to intensify the model. Furthermore, to enable controllable generation in LLMs, we leverage a certain fine-tuned LLM and an ensemble based on text consistency incorporating all coherence, fluency, and answer format assurance. Finally, extensive experiments conducted on the TriviaQA, MSMARCO, and CMRC2018 datasets, featuring diverse answer formats, have demonstrated the effectiveness of GenKI with comparison of state-of-the-art baselines. Moreover, ablation studies have disclosed a linear relationship between the frequency of retrieved knowledge and the model's ability to recall knowledge accurately against the ground truth. Our code of GenKI is available at https://github.com/USTC-StarTeam/GenKI
Predictive Models in Sequential Recommendations: Bridging Performance Laws with Data Quality Insights
Dec 03, 2024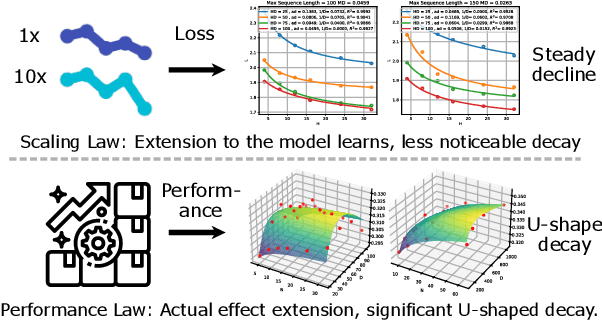
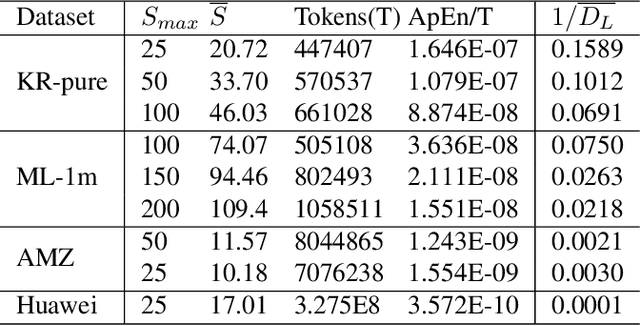
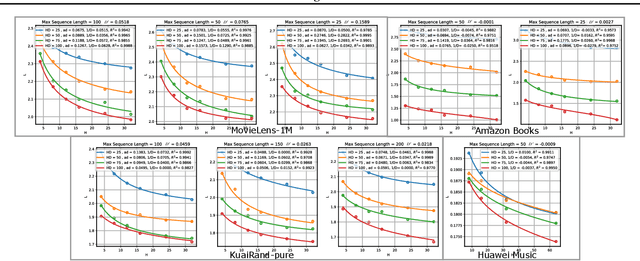
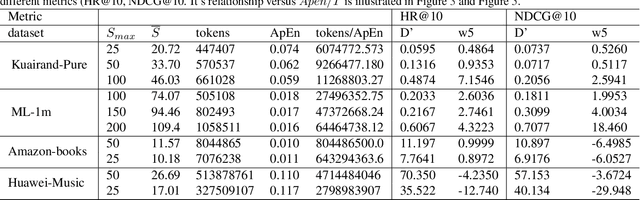
Sequential Recommendation (SR) plays a critical role in predicting users' sequential preferences. Despite its growing prominence in various industries, the increasing scale of SR models incurs substantial computational costs and unpredictability, challenging developers to manage resources efficiently. Under this predicament, Scaling Laws have achieved significant success by examining the loss as models scale up. However, there remains a disparity between loss and model performance, which is of greater concern in practical applications. Moreover, as data continues to expand, it incorporates repetitive and inefficient data. In response, we introduce the Performance Law for SR models, which aims to theoretically investigate and model the relationship between model performance and data quality. Specifically, we first fit the HR and NDCG metrics to transformer-based SR models. Subsequently, we propose Approximate Entropy (ApEn) to assess data quality, presenting a more nuanced approach compared to traditional data quantity metrics. Our method enables accurate predictions across various dataset scales and model sizes, demonstrating a strong correlation in large SR models and offering insights into achieving optimal performance for any given model configuration.
Scaling New Frontiers: Insights into Large Recommendation Models
Dec 01, 2024



Recommendation systems are essential for filtering data and retrieving relevant information across various applications. Recent advancements have seen these systems incorporate increasingly large embedding tables, scaling up to tens of terabytes for industrial use. However, the expansion of network parameters in traditional recommendation models has plateaued at tens of millions, limiting further benefits from increased embedding parameters. Inspired by the success of large language models (LLMs), a new approach has emerged that scales network parameters using innovative structures, enabling continued performance improvements. A significant development in this area is Meta's generative recommendation model HSTU, which illustrates the scaling laws of recommendation systems by expanding parameters to thousands of billions. This new paradigm has achieved substantial performance gains in online experiments. In this paper, we aim to enhance the understanding of scaling laws by conducting comprehensive evaluations of large recommendation models. Firstly, we investigate the scaling laws across different backbone architectures of the large recommendation models. Secondly, we conduct comprehensive ablation studies to explore the origins of these scaling laws. We then further assess the performance of HSTU, as the representative of large recommendation models, on complex user behavior modeling tasks to evaluate its applicability. Notably, we also analyze its effectiveness in ranking tasks for the first time. Finally, we offer insights into future directions for large recommendation models. Supplementary materials for our research are available on GitHub at https://github.com/USTC-StarTeam/Large-Recommendation-Models.
Exploring User Retrieval Integration towards Large Language Models for Cross-Domain Sequential Recommendation
Jun 05, 2024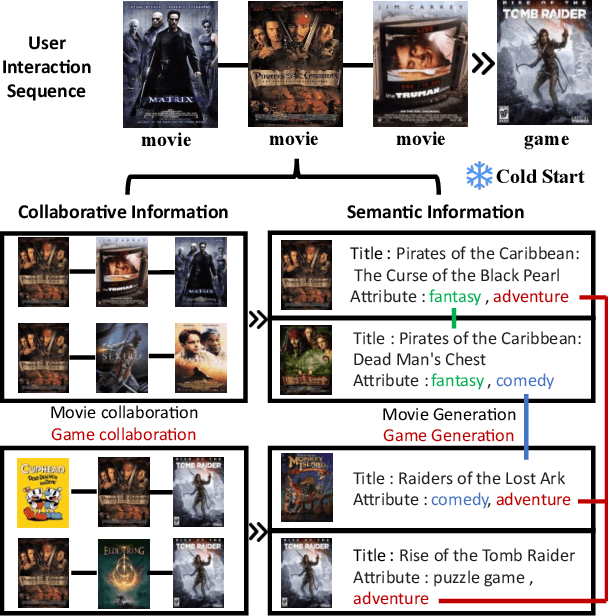
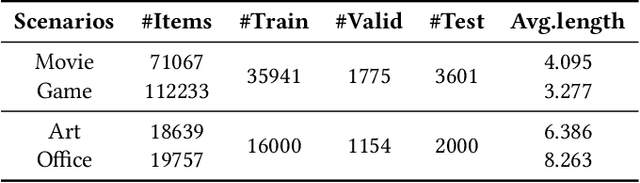
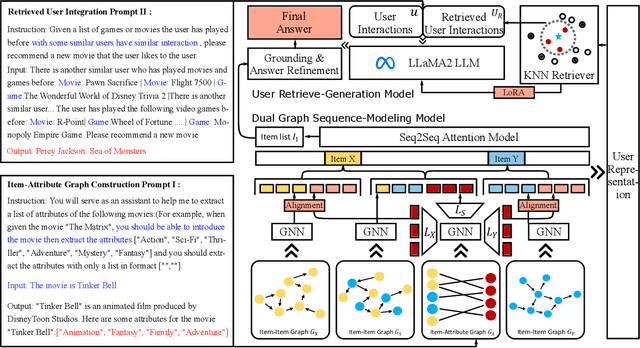
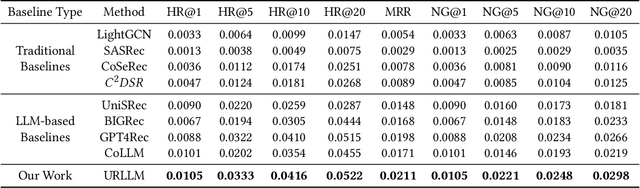
Cross-Domain Sequential Recommendation (CDSR) aims to mine and transfer users' sequential preferences across different domains to alleviate the long-standing cold-start issue. Traditional CDSR models capture collaborative information through user and item modeling while overlooking valuable semantic information. Recently, Large Language Model (LLM) has demonstrated powerful semantic reasoning capabilities, motivating us to introduce them to better capture semantic information. However, introducing LLMs to CDSR is non-trivial due to two crucial issues: seamless information integration and domain-specific generation. To this end, we propose a novel framework named URLLM, which aims to improve the CDSR performance by exploring the User Retrieval approach and domain grounding on LLM simultaneously. Specifically, we first present a novel dual-graph sequential model to capture the diverse information, along with an alignment and contrastive learning method to facilitate domain knowledge transfer. Subsequently, a user retrieve-generation model is adopted to seamlessly integrate the structural information into LLM, fully harnessing its emergent inferencing ability. Furthermore, we propose a domain-specific strategy and a refinement module to prevent out-of-domain generation. Extensive experiments on Amazon demonstrated the information integration and domain-specific generation ability of URLLM in comparison to state-of-the-art baselines. Our code is available at https://github.com/TingJShen/URLLM
A Survey on Large Language Models for Recommendation
Jun 01, 2023



Large Language Models (LLMs) have emerged as powerful tools in the field of Natural Language Processing (NLP) and have recently gained significant attention in the domain of Recommendation Systems (RS). These models, trained on massive amounts of data using self-supervised learning, have demonstrated remarkable success in learning universal representations and have the potential to enhance various aspects of recommendation systems by some effective transfer techniques such as fine-tuning and prompt tuning, and so on. The crucial aspect of harnessing the power of language models in enhancing recommendation quality is the utilization of their high-quality representations of textual features and their extensive coverage of external knowledge to establish correlations between items and users. To provide a comprehensive understanding of the existing LLM-based recommendation systems, this survey presents a taxonomy that categorizes these models into two major paradigms, respectively Discriminative LLM for Recommendation (DLLM4Rec) and Generative LLM for Recommendation (GLLM4Rec), with the latter being systematically sorted out for the first time. Furthermore, we systematically review and analyze existing LLM-based recommendation systems within each paradigm, providing insights into their methodologies, techniques, and performance. Additionally, we identify key challenges and several valuable findings to provide researchers and practitioners with inspiration. We have also created a GitHub repository to index relevant papers on LLMs for recommendation, https://github.com/WLiK/LLM4Rec.