 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuXi-Linear: Unleashing the Power of Linear Attention in Long-term Time-aware Sequential Recommendation
Feb 27, 2026Modern recommendation systems primarily rely on attention mechanisms with quadratic complexity, which limits their ability to handle long user sequences and slows down inference. While linear attention is a promising alternative, existing research faces three critical challenges: (1) temporal signals are often overlooked or integrated via naive coupling that causes mutual interference between temporal and semantic signals while neglecting behavioral periodicity; (2) insufficient positional information provided by existing linear frameworks; and (3) a primary focus on short sequences and shallow architectures. To address these issues, we propose FuXi-Linear, a linear-complexity model designed for efficient long-sequence recommendation. Our approach introduces two key components: (1) a Temporal Retention Channel that independently computes periodic attention weights using temporal data, preventing crosstalk between temporal and semantic signals; (2) a Linear Positional Channel that integrates positional information through learnable kernels within linear complexity. Moreover, we demonstrate that FuXi-Linear exhibits a robust power-law scaling property at a thousand-length scale, a characteristic largely unexplored in prior linear recommendation studies. Extensive experiments on sequences of several thousand tokens demonstrate that FuXi-Linear outperforms state-of-the-art models in recommendation quality, while achieving up to 10$\times$ speedup in the prefill stage and up to 21$\times$ speedup in the decode stage compared to competitive baselines. Our code has been released in a public repository https://github.com/USTC-StarTeam/fuxi-linear.
Why Thinking Hurts? Diagnosing and Rectifying the Reasoning Shift in Foundation Recommender Models
Feb 18, 2026Integrating Chain-of-Thought (CoT) reasoning into Semantic ID-based recommendation foundation models (such as OpenOneRec) often paradoxically degrades recommendation performance. We identify the root cause as textual inertia from the General Subspace, where verbose reasoning dominates inference and causes the model to neglect critical Semantic ID. To address this, we propose a training-free Inference-Time Subspace Alignment framework. By compressing reasoning chains and applying bias-subtracted contrastive decoding, our approach mitigates ungrounded textual drift. Experiments show this effectively calibrates inference, allowing foundation models to leverage reasoning without sacrificing ID-grounded accuracy.
The Next Paradigm Is User-Centric Agent, Not Platform-Centric Service
Feb 17, 2026Modern digital services have evolved into indispensable tools, driving the present large-scale information systems. Yet, the prevailing platform-centric model, where services are optimized for platform-driven metrics such as engagement and conversion, often fails to align with users' true needs. While platform technologies have advanced significantly-especially with the integration of large language models (LLMs)-we argue that improvements in platform service quality do not necessarily translate to genuine user benefit. Instead, platform-centric services prioritize provider objectives over user welfare, resulting in conflicts against user interests. This paper argues that the future of digital services should shift from a platform-centric to a user-centric agent. These user-centric agents prioritize privacy, align with user-defined goals, and grant users control over their preferences and actions. With advancements in LLMs and on-device intelligence, the realization of this vision is now feasible. This paper explores the opportunities and challenges in transitioning to user-centric intelligence, presents a practical device-cloud pipeline for its implementation, and discusses the necessary governance and ecosystem structures for its adoption.
Can Recommender Systems Teach Themselves? A Recursive Self-Improving Framework with Fidelity Control
Feb 17, 2026The scarcity of high-quality training data presents a fundamental bottleneck to scaling machine learning models. This challenge is particularly acute in recommendation systems, where extreme sparsity in user interactions leads to rugged optimization landscapes and poor generalization. We propose the Recursive Self-Improving Recommendation (RSIR) framework, a paradigm in which a model bootstraps its own performance without reliance on external data or teacher models. RSIR operates in a closed loop: the current model generates plausible user interaction sequences, a fidelity-based quality control mechanism filters them for consistency with user's approximate preference manifold, and a successor model is augmented on the enriched dataset. Our theoretical analysis shows that RSIR acts as a data-driven implicit regularizer, smoothing the optimization landscape and guiding models toward more robust solutions. Empirically, RSIR yields consistent, cumulative gains across multiple benchmarks and architectures. Notably, even smaller models benefit, and weak models can generate effective training curricula for stronger ones. These results demonstrate that recursive self-improvement is a general, model-agnostic approach to overcoming data sparsity, suggesting a scalable path forward for recommender systems and beyond. Our anonymized code is available at https://anonymous.4open.science/r/RSIR-7C5B .
Killing Two Birds with One Stone: Unifying Retrieval and Ranking with a Single Generative Recommendation Model
Apr 23, 2025In recommendation systems, the traditional multi-stage paradigm, which includes retrieval and ranking, often suffers from information loss between stages and diminishes performance. Recent advances in generative models, inspired by natural language processing, suggest the potential for unifying these stages to mitigate such loss. This paper presents the Unified Generative Recommendation Framework (UniGRF), a novel approach that integrates retrieval and ranking into a single generative model. By treating both stages as sequence generation tasks, UniGRF enables sufficient information sharing without additional computational costs, while remaining model-agnostic. To enhance inter-stage collaboration, UniGRF introduces a ranking-driven enhancer module that leverages the precision of the ranking stage to refine retrieval processes, creating an enhancement loop. Besides, a gradient-guided adaptive weighter is incorporated to dynamically balance the optimization of retrieval and ranking, ensuring synchronized performance improvements. Extensive experiments demonstrate that UniGRF significantly outperforms existing models on benchmark datasets, confirming its effectiveness in facilitating information transfer. Ablation studies and further experiments reveal that UniGRF not only promotes efficient collaboration between stages but also achieves synchronized optimization. UniGRF provides an effective, scalable, and compatible framework for generative recommendation systems.
Generative Large Recommendation Models: Emerging Trends in LLMs for Recommendation
Feb 19, 2025In the era of information overload, recommendation systems play a pivotal role in filtering data and delivering personalized content. Recent advancements in feature interaction and user behavior modeling have significantly enhanced the recall and ranking processes of these systems. With the rise of large language models (LLMs), new opportunities have emerged to further improve recommendation systems. This tutorial explores two primary approaches for integrating LLMs: LLMs-enhanced recommendations, which leverage the reasoning capabilities of general LLMs, and generative large recommendation models, which focus on scaling and sophistication. While the former has been extensively covered in existing literature, the latter remains underexplored. This tutorial aims to fill this gap by providing a comprehensive overview of generative large recommendation models, including their recent advancements, challenges, and potential research directions. Key topics include data quality, scaling laws, user behavior mining, and efficiency in training and inference. By engaging with this tutorial, participants will gain insights into the latest developments and future opportunities in the field, aiding both academic research and practical applications. The timely nature of this exploration supports the rapid evolution of recommendation systems, offering valuable guidance for researchers and practitioners alike.
Scaling New Frontiers: Insights into Large Recommendation Models
Dec 01, 2024



Recommendation systems are essential for filtering data and retrieving relevant information across various applications. Recent advancements have seen these systems incorporate increasingly large embedding tables, scaling up to tens of terabytes for industrial use. However, the expansion of network parameters in traditional recommendation models has plateaued at tens of millions, limiting further benefits from increased embedding parameters. Inspired by the success of large language models (LLMs), a new approach has emerged that scales network parameters using innovative structures, enabling continued performance improvements. A significant development in this area is Meta's generative recommendation model HSTU, which illustrates the scaling laws of recommendation systems by expanding parameters to thousands of billions. This new paradigm has achieved substantial performance gains in online experiments. In this paper, we aim to enhance the understanding of scaling laws by conducting comprehensive evaluations of large recommendation models. Firstly, we investigate the scaling laws across different backbone architectures of the large recommendation models. Secondly, we conduct comprehensive ablation studies to explore the origins of these scaling laws. We then further assess the performance of HSTU, as the representative of large recommendation models, on complex user behavior modeling tasks to evaluate its applicability. Notably, we also analyze its effectiveness in ranking tasks for the first time. Finally, we offer insights into future directions for large recommendation models. Supplementary materials for our research are available on GitHub at https://github.com/USTC-StarTeam/Large-Recommendation-Models.
Multi-granularity Interest Retrieval and Refinement Network for Long-Term User Behavior Modeling in CTR Prediction
Nov 22, 2024



Click-through Rate (CTR) prediction is crucial for online personalization platforms. Recent advancements have shown that modeling rich user behaviors can significantly improve the performance of CTR prediction. Current long-term user behavior modeling algorithms predominantly follow two cascading stages. The first stage retrieves subsequence related to the target item from the long-term behavior sequence, while the second stage models the relationship between the subsequence and the target item. Despite significant progress, these methods have two critical flaws. First, the retrieval query typically includes only target item information, limiting the ability to capture the user's diverse interests. Second, relational information, such as sequential and interactive information within the subsequence, is frequently overlooked. Therefore, it requires to be further mined to more accurately model user interests. To this end, we propose Multi-granularity Interest Retrieval and Refinement Network (MIRRN). Specifically, we first construct queries based on behaviors observed at different time scales to obtain subsequences, each capturing users' interest at various granularities. We then introduce an noval multi-head Fourier transformer to efficiently learn sequential and interactive information within the subsequences, leading to more accurate modeling of user interests. Finally, we employ multi-head target attention to adaptively assess the impact of these multi-granularity interests on the target item. Extensive experiments have demonstrated that MIRRN significantly outperforms state-of-the-art baselines. Furthermore, an A/B test shows that MIRRN increases the average number of listening songs by 1.32% and the average time of listening songs by 0.55% on a popular music streaming app. The implementation code is publicly available at https://github.com/psycho-demon/MIRRN.
Breaking Determinism: Fuzzy Modeling of Sequential Recommendation Using Discrete State Space Diffusion Model
Oct 31, 2024



Sequential recommendation (SR) aims to predict items that users may be interested in based on their historical behavior sequences. We revisit SR from a novel information-theoretic perspective and find that conventional sequential modeling methods fail to adequately capture the randomness and unpredictability of user behavior. Inspired by fuzzy information processing theory, this paper introduces the DDSR model, which uses fuzzy sets of interaction sequences to overcome the limitations and better capture the evolution of users' real interests. Formally based on diffusion transition processes in discrete state spaces, which is unlike common diffusion models such as DDPM that operate in continuous domains. It is better suited for discrete data, using structured transitions instead of arbitrary noise introduction to avoid information loss. Additionally, to address the inefficiency of matrix transformations due to the vast discrete space, we use semantic labels derived from quantization or RQ-VAE to replace item IDs, enhancing efficiency and improving cold start issues. Testing on three public benchmark datasets shows that DDSR outperforms existing state-of-the-art methods in various settings, demonstrating its potential and effectiveness in handling SR tasks.
A Unified Framework for Adaptive Representation Enhancement and Inversed Learning in Cross-Domain Recommendation
Mar 30, 2024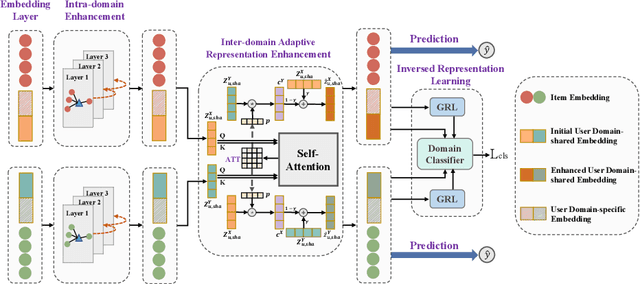
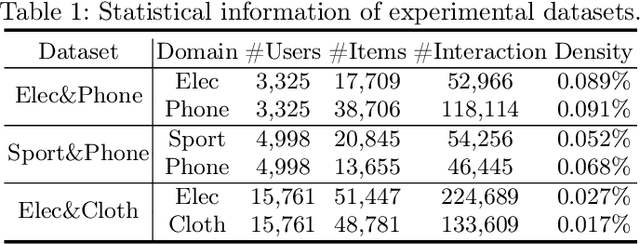
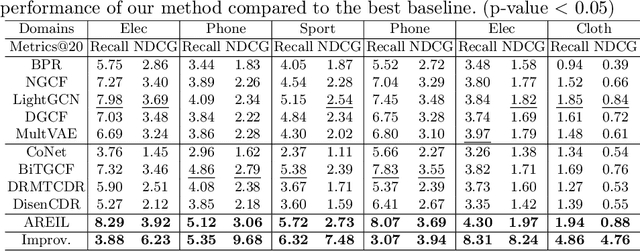
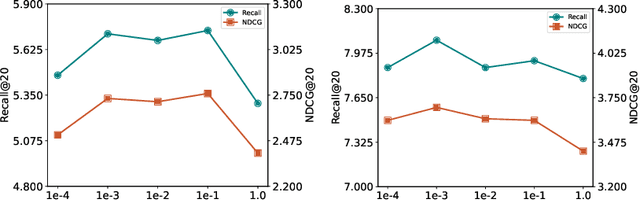
Cross-domain recommendation (CDR), aiming to extract and transfer knowledge across domains, has attracted wide attention for its efficacy in addressing data sparsity and cold-start problems. Despite significant advances in representation disentanglement to capture diverse user preferences, existing methods usually neglect representation enhancement and lack rigorous decoupling constraints, thereby limiting the transfer of relevant information. To this end, we propose a Unified Framework for Adaptive Representation Enhancement and Inversed Learning in Cross-Domain Recommendation (AREIL). Specifically, we first divide user embeddings into domain-shared and domain-specific components to disentangle mixed user preferences. Then, we incorporate intra-domain and inter-domain information to adaptively enhance the ability of user representations. In particular, we propose a graph convolution module to capture high-order information, and a self-attention module to reveal inter-domain correlations and accomplish adaptive fusion. Next, we adopt domain classifiers and gradient reversal layers to achieve inversed representation learning in a unified framework. Finally, we employ a cross-entropy loss for measuring recommendation performance and jointly optimize the entire framework via multi-task learning. Extensive experiments on multiple datasets validate the substantial improvement in the recommendation performance of AREIL. Moreover, ablation studies and representation visualizations further illustrate the effectiveness of adaptive enhancement and inversed learning in CDR.