 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSIC: Learning Muscle-Driven Dexterous Hand Control
Apr 26, 2026We present a data-driven approach for physics-based, muscle-driven dexterous control that enables musculoskeletal hands to perform precise piano playing for novel pieces of music outside the reference dataset. Our approach combines high-frequency muscle-level control with low-frequency latent-space coordination in a hierarchical architecture. At the low level, general single-hand policies are trained via reinforcement learning to generate dynamic muscle-tendon activations while tracking trajectories from a large reference motion dataset. The resulting tracking policies are then distilled into variational autoencoder (VAE) models, yielding smooth and structured latent spaces that abstract away low-level muscle dynamics. For the high level, we train piece-specific policies to operate in this latent space, coordinating bimanual motions based on specific goals, denoted by note events extracted from given musical scores, to synthesize performances beyond the reference data. In addition, we present an enhanced musculoskeletal hand model that supports fine control of fingers for accurate low-level motion tracking and diverse high-level motion synthesis. We evaluate the control pipeline of our approach on a diverse piano repertoire spanning multiple musical styles and technical demands. Results demonstrate that our approach can synthesize coordinated bimanual motions with accurate key presses, and achieve the state-of-the-art performance of piano playing in physics-based dexterous control. We also show that our musculoskeletal hand model demonstrates superior biomechanical stability and tracking precision compared to the existing model, and validate that our musculoskeletal hand model and muscle-driven controller can generate physiologically plausible activation patterns that align with human electromyography (EMG) recordings.
FuXi-Linear: Unleashing the Power of Linear Attention in Long-term Time-aware Sequential Recommendation
Feb 27, 2026Modern recommendation systems primarily rely on attention mechanisms with quadratic complexity, which limits their ability to handle long user sequences and slows down inference. While linear attention is a promising alternative, existing research faces three critical challenges: (1) temporal signals are often overlooked or integrated via naive coupling that causes mutual interference between temporal and semantic signals while neglecting behavioral periodicity; (2) insufficient positional information provided by existing linear frameworks; and (3) a primary focus on short sequences and shallow architectures. To address these issues, we propose FuXi-Linear, a linear-complexity model designed for efficient long-sequence recommendation. Our approach introduces two key components: (1) a Temporal Retention Channel that independently computes periodic attention weights using temporal data, preventing crosstalk between temporal and semantic signals; (2) a Linear Positional Channel that integrates positional information through learnable kernels within linear complexity. Moreover, we demonstrate that FuXi-Linear exhibits a robust power-law scaling property at a thousand-length scale, a characteristic largely unexplored in prior linear recommendation studies. Extensive experiments on sequences of several thousand tokens demonstrate that FuXi-Linear outperforms state-of-the-art models in recommendation quality, while achieving up to 10$\times$ speedup in the prefill stage and up to 21$\times$ speedup in the decode stage compared to competitive baselines. Our code has been released in a public repository https://github.com/USTC-StarTeam/fuxi-linear.
WHOLE: World-Grounded Hand-Object Lifted from Egocentric Videos
Feb 25, 2026Egocentric manipulation videos are highly challenging due to severe occlusions during interactions and frequent object entries and exits from the camera view as the person moves. Current methods typically focus on recovering either hand or object pose in isolation, but both struggle during interactions and fail to handle out-of-sight cases. Moreover, their independent predictions often lead to inconsistent hand-object relations. We introduce WHOLE, a method that holistically reconstructs hand and object motion in world space from egocentric videos given object templates. Our key insight is to learn a generative prior over hand-object motion to jointly reason about their interactions. At test time, the pretrained prior is guided to generate trajectories that conform to the video observations. This joint generative reconstruction substantially outperforms approaches that process hands and objects separately followed by post-processing. WHOLE achieves state-of-the-art performance on hand motion estimation, 6D object pose estimation, and their relative interaction reconstruction. Project website: https://judyye.github.io/whole-www
Dexterous Manipulation Policies from RGB Human Videos via 4D Hand-Object Trajectory Reconstruction
Feb 09, 2026Multi-finger robotic hand manipulation and grasping are challenging due to the high-dimensional action space and the difficulty of acquiring large-scale training data. Existing approaches largely rely on human teleoperation with wearable devices or specialized sensing equipment to capture hand-object interactions, which limits scalability. In this work, we propose VIDEOMANIP, a device-free framework that learns dexterous manipulation directly from RGB human videos. Leveraging recent advances in computer vision, VIDEOMANIP reconstructs explicit 4D robot-object trajectories from monocular videos by estimating human hand poses, object meshes, and retargets the reconstructed human motions to robotic hands for manipulation learning. To make the reconstructed robot data suitable for dexterous manipulation training, we introduce hand-object contact optimization with interaction-centric grasp modeling, as well as a demonstration synthesis strategy that generates diverse training trajectories from a single video, enabling generalizable policy learning without additional robot demonstrations. In simulation, the learned grasping model achieves a 70.25% success rate across 20 diverse objects using the Inspire Hand. In the real world, manipulation policies trained from RGB videos achieve an average 62.86% success rate across seven tasks using the LEAP Hand, outperforming retargeting-based methods by 15.87%. Project videos are available at videomanip.github.io.
Web2Grasp: Learning Functional Grasps from Web Images of Hand-Object Interactions
May 07, 2025Functional grasp is essential for enabling dexterous multi-finger robot hands to manipulate objects effectively. However, most prior work either focuses on power grasping, which simply involves holding an object still, or relies on costly teleoperated robot demonstrations to teach robots how to grasp each object functionally. Instead, we propose extracting human grasp information from web images since they depict natural and functional object interactions, thereby bypassing the need for curated demonstrations. We reconstruct human hand-object interaction (HOI) 3D meshes from RGB images, retarget the human hand to multi-finger robot hands, and align the noisy object mesh with its accurate 3D shape. We show that these relatively low-quality HOI data from inexpensive web sources can effectively train a functional grasping model. To further expand the grasp dataset for seen and unseen objects, we use the initially-trained grasping policy with web data in the IsaacGym simulator to generate physically feasible grasps while preserving functionality. We train the grasping model on 10 object categories and evaluate it on 9 unseen objects, including challenging items such as syringes, pens, spray bottles, and tongs, which are underrepresented in existing datasets. The model trained on the web HOI dataset, achieving a 75.8% success rate on seen objects and 61.8% across all objects in simulation, with a 6.7% improvement in success rate and a 1.8x increase in functionality ratings over baselines. Simulator-augmented data further boosts performance from 61.8% to 83.4%. The sim-to-real transfer to the LEAP Hand achieves a 85% success rate. Project website is at: https://webgrasp.github.io/.
St4RTrack: Simultaneous 4D Reconstruction and Tracking in the World
Apr 17, 2025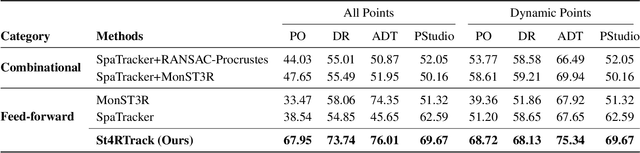
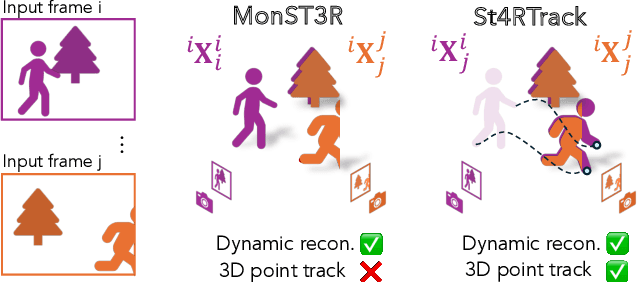
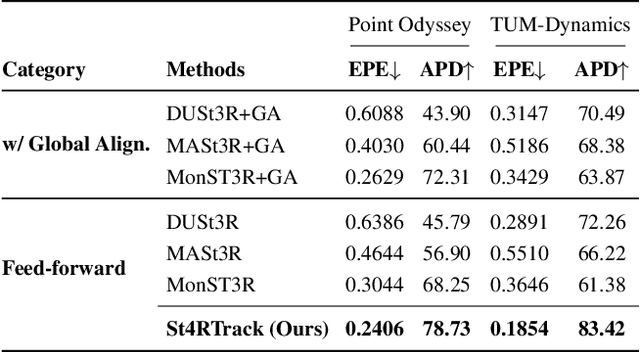
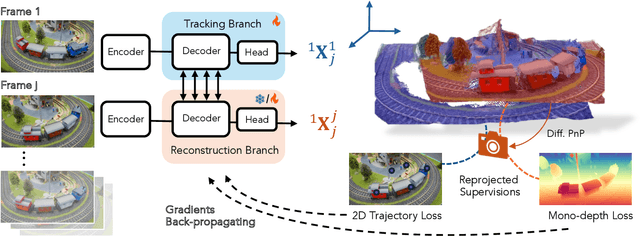
Dynamic 3D reconstruction and point tracking in videos are typically treated as separate tasks, despite their deep connection. We propose St4RTrack, a feed-forward framework that simultaneously reconstructs and tracks dynamic video content in a world coordinate frame from RGB inputs. This is achieved by predicting two appropriately defined pointmaps for a pair of frames captured at different moments. Specifically, we predict both pointmaps at the same moment, in the same world, capturing both static and dynamic scene geometry while maintaining 3D correspondences. Chaining these predictions through the video sequence with respect to a reference frame naturally computes long-range correspondences, effectively combining 3D reconstruction with 3D tracking. Unlike prior methods that rely heavily on 4D ground truth supervision, we employ a novel adaptation scheme based on a reprojection loss. We establish a new extensive benchmark for world-frame reconstruction and tracking, demonstrating the effectiveness and efficiency of our unified, data-driven framework. Our code, model, and benchmark will be released.
Sequential Task Assignment and Resource Allocation in V2X-Enabled Mobile Edge Computing
Mar 26, 2025

Nowadays, the convergence of Mobile Edge Computing (MEC) and vehicular networks has emerged as a vital facilitator for the ever-increasing intelligent onboard applications. This paper introduces a multi-tier task offloading mechanism for MEC-enabled vehicular networks leveraging vehicle-to-everything (V2X) communications. The study focuses on applications with sequential subtasks and explores two tiers of collaboration. In the vehicle tier, we design a needing vehicle (NV)-helping vehicle (HV) matching scheme and inter-vehicle collaborative computation is studied, with joint optimization of task offloading decision, communication, and computation resource allocation to minimize energy consumption and meet latency requirements. In the roadside unit (RSU) tier, collaboration among RSUs is investigated to address multi-access issues of bandwidth and computation resources for multiple vehicles. A two-step method is proposed to solve the subchannel allocation problem. Detailed experiments are conducted to demonstrate the effectiveness of the proposed method and assess the impact of different parameters on system energy consumption.
Generative Large Recommendation Models: Emerging Trends in LLMs for Recommendation
Feb 19, 2025In the era of information overload, recommendation systems play a pivotal role in filtering data and delivering personalized content. Recent advancements in feature interaction and user behavior modeling have significantly enhanced the recall and ranking processes of these systems. With the rise of large language models (LLMs), new opportunities have emerged to further improve recommendation systems. This tutorial explores two primary approaches for integrating LLMs: LLMs-enhanced recommendations, which leverage the reasoning capabilities of general LLMs, and generative large recommendation models, which focus on scaling and sophistication. While the former has been extensively covered in existing literature, the latter remains underexplored. This tutorial aims to fill this gap by providing a comprehensive overview of generative large recommendation models, including their recent advancements, challenges, and potential research directions. Key topics include data quality, scaling laws, user behavior mining, and efficiency in training and inference. By engaging with this tutorial, participants will gain insights into the latest developments and future opportunities in the field, aiding both academic research and practical applications. The timely nature of this exploration supports the rapid evolution of recommendation systems, offering valuable guidance for researchers and practitioners alike.
FuXi-$α$: Scaling Recommendation Model with Feature Interaction Enhanced Transformer
Feb 05, 2025



Inspired by scaling laws and large language models, research on large-scale recommendation models has gained significant attention. Recent advancements have shown that expanding sequential recommendation models to large-scale recommendation models can be an effective strategy. Current state-of-the-art sequential recommendation models primarily use self-attention mechanisms for explicit feature interactions among items, while implicit interactions are managed through Feed-Forward Networks (FFNs). However, these models often inadequately integrate temporal and positional information, either by adding them to attention weights or by blending them with latent representations, which limits their expressive power. A recent model, HSTU, further reduces the focus on implicit feature interactions, constraining its performance. We propose a new model called FuXi-$\alpha$ to address these issues. This model introduces an Adaptive Multi-channel Self-attention mechanism that distinctly models temporal, positional, and semantic features, along with a Multi-stage FFN to enhance implicit feature interactions. Our offline experiments demonstrate that our model outperforms existing models, with its performance continuously improving as the model size increases. Additionally, we conducted an online A/B test within the Huawei Music app, which showed a $4.76\%$ increase in the average number of songs played per user and a $5.10\%$ increase in the average listening duration per user. Our code has been released at https://github.com/USTC-StarTeam/FuXi-alpha.
Predicting 4D Hand Trajectory from Monocular Videos
Jan 14, 2025



We present HaPTIC, an approach that infers coherent 4D hand trajectories from monocular videos. Current video-based hand pose reconstruction methods primarily focus on improving frame-wise 3D pose using adjacent frames rather than studying consistent 4D hand trajectories in space. Despite the additional temporal cues, they generally underperform compared to image-based methods due to the scarcity of annotated video data. To address these issues, we repurpose a state-of-the-art image-based transformer to take in multiple frames and directly predict a coherent trajectory. We introduce two types of lightweight attention layers: cross-view self-attention to fuse temporal information, and global cross-attention to bring in larger spatial context. Our method infers 4D hand trajectories similar to the ground truth while maintaining strong 2D reprojection alignment. We apply the method to both egocentric and allocentric videos. It significantly outperforms existing methods in global trajectory accuracy while being comparable to the state-of-the-art in single-image pose estimation. Project website: https://judyye.github.io/haptic-www