 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFingerEye: Continuous and Unified Vision-Tactile Sensing for Dexterous Manipulation
Apr 22, 2026Dexterous robotic manipulation requires comprehensive perception across all phases of interaction: pre-contact, contact initiation, and post-contact. Such continuous feedback allows a robot to adapt its actions throughout interaction. However, many existing tactile sensors, such as GelSight and its variants, only provide feedback after contact is established, limiting a robot's ability to precisely initiate contact. We introduce FingerEye, a compact and cost-effective sensor that provides continuous vision-tactile feedback throughout the interaction process. FingerEye integrates binocular RGB cameras to provide close-range visual perception with implicit stereo depth. Upon contact, external forces and torques deform a compliant ring structure; these deformations are captured via marker-based pose estimation and serve as a proxy for contact wrench sensing. This design enables a perception stream that smoothly transitions from pre-contact visual cues to post-contact tactile feedback. Building on this sensing capability, we develop a vision-tactile imitation learning policy that fuses signals from multiple FingerEye sensors to learn dexterous manipulation behaviors from limited real-world data. We further develop a digital twin of our sensor and robot platform to improve policy generalization. By combining real demonstrations with visually augmented simulated observations for representation learning, the learned policies become more robust to object appearance variations. Together, these design aspects enable dexterous manipulation across diverse object properties and interaction regimes, including coin standing, chip picking, letter retrieving, and syringe manipulation. The hardware design, code, appendix, and videos are available on our project website: https://nus-lins-lab.github.io/FingerEyeWeb/
Contact Coverage-Guided Exploration for General-Purpose Dexterous Manipulation
Mar 11, 2026Deep Reinforcement learning (DRL) has achieved remarkable success in domains with well-defined reward structures, such as Atari games and locomotion. In contrast, dexterous manipulation lacks general-purpose reward formulations and typically depends on task-specific, handcrafted priors to guide hand-object interactions. We propose Contact Coverage-Guided Exploration (CCGE), a general exploration method designed for general-purpose dexterous manipulation tasks. CCGE represents contact state as the intersection between object surface points and predefined hand keypoints, encouraging dexterous hands to discover diverse and novel contact patterns, namely which fingers contact which object regions. It maintains a contact counter conditioned on discretized object states obtained via learned hash codes, capturing how frequently each finger interacts with different object regions. This counter is leveraged in two complementary ways: (1) to assign a count-based contact coverage reward that promotes exploration of novel contact patterns, and (2) an energy-based reaching reward that guides the agent toward under-explored contact regions. We evaluate CCGE on a diverse set of dexterous manipulation tasks, including cluttered object singulation, constrained object retrieval, in-hand reorientation, and bimanual manipulation. Experimental results show that CCGE substantially improves training efficiency and success rates over existing exploration methods, and that the contact patterns learned with CCGE transfer robustly to real-world robotic systems. Project page is https://contact-coverage-guided-exploration.github.io.
AdaClearGrasp: Learning Adaptive Clearing for Zero-Shot Robust Dexterous Grasping in Densely Cluttered Environments
Mar 11, 2026In densely cluttered environments, physical interference, visual occlusions, and unstable contacts often cause direct dexterous grasping to fail, while aggressive singulation strategies may compromise safety. Enabling robots to adaptively decide whether to clear surrounding objects or directly grasp the target is therefore crucial for robust manipulation. We propose AdaClearGrasp, a closed-loop decision-execution framework for adaptive clearing and zero-shot dexterous grasping in densely cluttered environments. The framework formulates manipulation as a controllable high-level decision process that determines whether to directly grasp the target or first clear surrounding objects. A pretrained vision-language model (VLM) interprets visual observations and language task descriptions to reason about grasp interference and generate a high-level planning skeleton, which invokes structured atomic skills through a unified action interface. For dexterous grasping, we train a reinforcement learning policy with a relative hand-object distance representation, enabling zero-shot generalization across diverse object geometries and physical properties. During execution, visual feedback monitors outcomes and triggers replanning upon failures, forming a closed-loop correction mechanism. To evaluate language-conditioned dexterous grasping in clutter, we introduce Clutter-Bench, the first simulation benchmark with graded clutter complexity. It includes seven target objects across three clutter levels, yielding 210 task scenarios. We further perform sim-to-real experiments on three objects under three clutter levels (18 scenarios). Results demonstrate that AdaClearGrasp significantly improves grasp success rates in densely cluttered environments. For more videos and code, please visit our project website: https://chenzixuan99.github.io/adaclear-grasp.github.io/.
T(R,O) Grasp: Efficient Graph Diffusion of Robot-Object Spatial Transformation for Cross-Embodiment Dexterous Grasping
Oct 14, 2025Dexterous grasping remains a central challenge in robotics due to the complexity of its high-dimensional state and action space. We introduce T(R,O) Grasp, a diffusion-based framework that efficiently generates accurate and diverse grasps across multiple robotic hands. At its core is the T(R,O) Graph, a unified representation that models spatial transformations between robotic hands and objects while encoding their geometric properties. A graph diffusion model, coupled with an efficient inverse kinematics solver, supports both unconditioned and conditioned grasp synthesis. Extensive experiments on a diverse set of dexterous hands show that T(R,O) Grasp achieves average success rate of 94.83%, inference speed of 0.21s, and throughput of 41 grasps per second on an NVIDIA A100 40GB GPU, substantially outperforming existing baselines. In addition, our approach is robust and generalizable across embodiments while significantly reducing memory consumption. More importantly, the high inference speed enables closed-loop dexterous manipulation, underscoring the potential of T(R,O) Grasp to scale into a foundation model for dexterous grasping.
Web2Grasp: Learning Functional Grasps from Web Images of Hand-Object Interactions
May 07, 2025Functional grasp is essential for enabling dexterous multi-finger robot hands to manipulate objects effectively. However, most prior work either focuses on power grasping, which simply involves holding an object still, or relies on costly teleoperated robot demonstrations to teach robots how to grasp each object functionally. Instead, we propose extracting human grasp information from web images since they depict natural and functional object interactions, thereby bypassing the need for curated demonstrations. We reconstruct human hand-object interaction (HOI) 3D meshes from RGB images, retarget the human hand to multi-finger robot hands, and align the noisy object mesh with its accurate 3D shape. We show that these relatively low-quality HOI data from inexpensive web sources can effectively train a functional grasping model. To further expand the grasp dataset for seen and unseen objects, we use the initially-trained grasping policy with web data in the IsaacGym simulator to generate physically feasible grasps while preserving functionality. We train the grasping model on 10 object categories and evaluate it on 9 unseen objects, including challenging items such as syringes, pens, spray bottles, and tongs, which are underrepresented in existing datasets. The model trained on the web HOI dataset, achieving a 75.8% success rate on seen objects and 61.8% across all objects in simulation, with a 6.7% improvement in success rate and a 1.8x increase in functionality ratings over baselines. Simulator-augmented data further boosts performance from 61.8% to 83.4%. The sim-to-real transfer to the LEAP Hand achieves a 85% success rate. Project website is at: https://webgrasp.github.io/.
DexSinGrasp: Learning a Unified Policy for Dexterous Object Singulation and Grasping in Cluttered Environments
Apr 06, 2025Grasping objects in cluttered environments remains a fundamental yet challenging problem in robotic manipulation. While prior works have explored learning-based synergies between pushing and grasping for two-fingered grippers, few have leveraged the high degrees of freedom (DoF) in dexterous hands to perform efficient singulation for grasping in cluttered settings. In this work, we introduce DexSinGrasp, a unified policy for dexterous object singulation and grasping. DexSinGrasp enables high-dexterity object singulation to facilitate grasping, significantly improving efficiency and effectiveness in cluttered environments. We incorporate clutter arrangement curriculum learning to enhance success rates and generalization across diverse clutter conditions, while policy distillation enables a deployable vision-based grasping strategy. To evaluate our approach, we introduce a set of cluttered grasping tasks with varying object arrangements and occlusion levels. Experimental results show that our method outperforms baselines in both efficiency and grasping success rate, particularly in dense clutter. Codes, appendix, and videos are available on our project website https://nus-lins-lab.github.io/dexsingweb/.
MetaFold: Language-Guided Multi-Category Garment Folding Framework via Trajectory Generation and Foundation Model
Mar 11, 2025
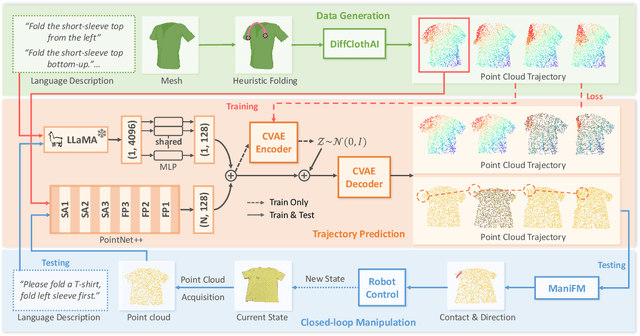
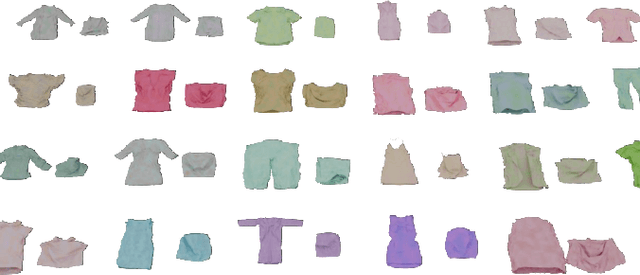

Garment folding is a common yet challenging task in robotic manipulation. The deformability of garments leads to a vast state space and complex dynamics, which complicates precise and fine-grained manipulation. Previous approaches often rely on predefined key points or demonstrations, limiting their generalization across diverse garment categories. This paper presents a framework, MetaFold, that disentangles task planning from action prediction, learning each independently to enhance model generalization. It employs language-guided point cloud trajectory generation for task planning and a low-level foundation model for action prediction. This structure facilitates multi-category learning, enabling the model to adapt flexibly to various user instructions and folding tasks. Experimental results demonstrate the superiority of our proposed framework. Supplementary materials are available on our website: https://meta-fold.github.io/.
TelePhantom: A User-Friendly Teleoperation System with Virtual Assistance for Enhanced Effectiveness
Dec 18, 2024



Dexterous manipulation is a critical area of robotics. In this field, teleoperation faces three key challenges: user-friendliness for novices, safety assurance, and transferability across different platforms. While collecting real robot dexterous manipulation data by teleoperation to train robots has shown impressive results on diverse tasks, due to the morphological differences between human and robot hands, it is not only hard for new users to understand the action mapping but also raises potential safety concerns during operation. To address these limitations, we introduce TelePhantom. This teleoperation system offers real-time visual feedback on robot actions based on human user inputs, with a total hardware cost of less than $1,000. TelePhantom allows the user to see a virtual robot that represents the outcome of the user's next movement. By enabling flexible switching between command visualization and actual execution, this system helps new users learn how to demonstrate quickly and safely. We demonstrate its superiority over other teleoperation systems across five tasks, emphasize its ease of use, and highlight its ease of deployment across diverse input sensors and robotic platforms. We will release our code and a deployment document on our website: https://telephantom.github.io/.
FLIP: Flow-Centric Generative Planning for General-Purpose Manipulation Tasks
Dec 11, 2024



We aim to develop a model-based planning framework for world models that can be scaled with increasing model and data budgets for general-purpose manipulation tasks with only language and vision inputs. To this end, we present FLow-centric generative Planning (FLIP), a model-based planning algorithm on visual space that features three key modules: 1. a multi-modal flow generation model as the general-purpose action proposal module; 2. a flow-conditioned video generation model as the dynamics module; and 3. a vision-language representation learning model as the value module. Given an initial image and language instruction as the goal, FLIP can progressively search for long-horizon flow and video plans that maximize the discounted return to accomplish the task. FLIP is able to synthesize long-horizon plans across objects, robots, and tasks with image flows as the general action representation, and the dense flow information also provides rich guidance for long-horizon video generation. In addition, the synthesized flow and video plans can guide the training of low-level control policies for robot execution. Experiments on diverse benchmarks demonstrate that FLIP can improve both the success rates and quality of long-horizon video plan synthesis and has the interactive world model property, opening up wider applications for future works.
$\mathcal{D(R,O)}$ Grasp: A Unified Representation of Robot and Object Interaction for Cross-Embodiment Dexterous Grasping
Oct 02, 2024



Dexterous grasping is a fundamental yet challenging skill in robotic manipulation, requiring precise interaction between robotic hands and objects. In this paper, we present $\mathcal{D(R,O)}$ Grasp, a novel framework that models the interaction between the robotic hand in its grasping pose and the object, enabling broad generalization across various robot hands and object geometries. Our model takes the robot hand's description and object point cloud as inputs and efficiently predicts kinematically valid and stable grasps, demonstrating strong adaptability to diverse robot embodiments and object geometries. Extensive experiments conducted in both simulated and real-world environments validate the effectiveness of our approach, with significant improvements in success rate, grasp diversity, and inference speed across multiple robotic hands. Our method achieves an average success rate of 87.53% in simulation in less than one second, tested across three different dexterous robotic hands. In real-world experiments using the LeapHand, the method also demonstrates an average success rate of 89%. $\mathcal{D(R,O)}$ Grasp provides a robust solution for dexterous grasping in complex and varied environments. The code, appendix, and videos are available on our project website at https://nus-lins-lab.github.io/drograspweb/.