 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable Articulated Object Reconstruction from Casually Captured RGBD Videos
Jun 10, 2025Articulated objects are prevalent in daily life. Understanding their kinematic structure and reconstructing them have numerous applications in embodied AI and robotics. However, current methods require carefully captured data for training or inference, preventing practical, scalable, and generalizable reconstruction of articulated objects. We focus on reconstruction of an articulated object from a casually captured RGBD video shot with a hand-held camera. A casually captured video of an interaction with an articulated object is easy to acquire at scale using smartphones. However, this setting is quite challenging, as the object and camera move simultaneously and there are significant occlusions as the person interacts with the object. To tackle these challenges, we introduce a coarse-to-fine framework that infers joint parameters and segments movable parts of the object from a dynamic RGBD video. To evaluate our method under this new setting, we build a 20$\times$ larger synthetic dataset of 784 videos containing 284 objects across 11 categories. We compare our approach with existing methods that also take video as input. Experiments show that our method can reconstruct synthetic and real articulated objects across different categories from dynamic RGBD videos, outperforming existing methods significantly.
TieBot: Learning to Knot a Tie from Visual Demonstration through a Real-to-Sim-to-Real Approach
Jul 03, 2024



The tie-knotting task is highly challenging due to the tie's high deformation and long-horizon manipulation actions. This work presents TieBot, a Real-to-Sim-to-Real learning from visual demonstration system for the robots to learn to knot a tie. We introduce the Hierarchical Feature Matching approach to estimate a sequence of tie's meshes from the demonstration video. With these estimated meshes used as subgoals, we first learn a teacher policy using privileged information. Then, we learn a student policy with point cloud observation by imitating teacher policy. Lastly, our pipeline learns a residual policy when the learned policy is applied to real-world execution, mitigating the Sim2Real gap. We demonstrate the effectiveness of TieBot in simulation and the real world. In the real-world experiment, a dual-arm robot successfully knots a tie, achieving 50% success rate among 10 trials. Videos can be found on our $\href{https://tiebots.github.io/}{\text{website}}$.
ManiFoundation Model for General-Purpose Robotic Manipulation of Contact Synthesis with Arbitrary Objects and Robots
May 11, 2024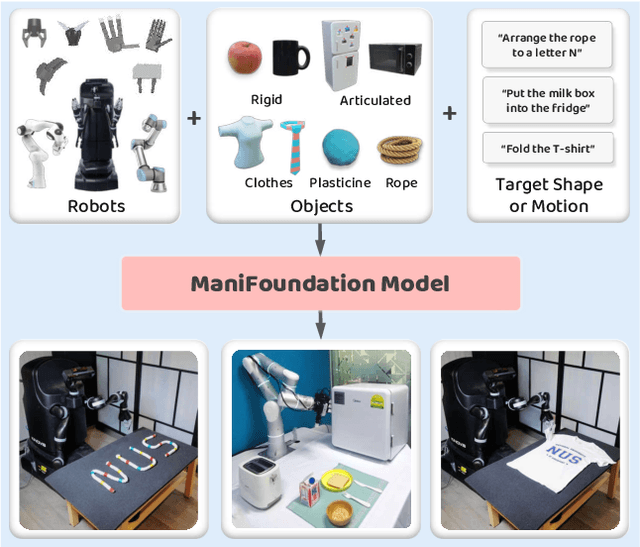


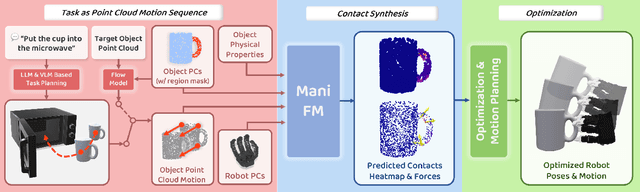
To substantially enhance robot intelligence, there is a pressing need to develop a large model that enables general-purpose robots to proficiently undertake a broad spectrum of manipulation tasks, akin to the versatile task-planning ability exhibited by LLMs. The vast diversity in objects, robots, and manipulation tasks presents huge challenges. Our work introduces a comprehensive framework to develop a foundation model for general robotic manipulation that formalizes a manipulation task as contact synthesis. Specifically, our model takes as input object and robot manipulator point clouds, object physical attributes, target motions, and manipulation region masks. It outputs contact points on the object and associated contact forces or post-contact motions for robots to achieve the desired manipulation task. We perform extensive experiments both in the simulation and real-world settings, manipulating articulated rigid objects, rigid objects, and deformable objects that vary in dimensionality, ranging from one-dimensional objects like ropes to two-dimensional objects like cloth and extending to three-dimensional objects such as plasticine. Our model achieves average success rates of around 90\%. Supplementary materials and videos are available on our project website at https://manifoundationmodel.github.io/.
Generalizable Long-Horizon Manipulations with Large Language Models
Oct 03, 2023This work introduces a framework harnessing the capabilities of Large Language Models (LLMs) to generate primitive task conditions for generalizable long-horizon manipulations with novel objects and unseen tasks. These task conditions serve as guides for the generation and adjustment of Dynamic Movement Primitives (DMP) trajectories for long-horizon task execution. We further create a challenging robotic manipulation task suite based on Pybullet for long-horizon task evaluation. Extensive experiments in both simulated and real-world environments demonstrate the effectiveness of our framework on both familiar tasks involving new objects and novel but related tasks, highlighting the potential of LLMs in enhancing robotic system versatility and adaptability. Project website: https://object814.github.io/Task-Condition-With-LLM/
ELIC: Efficient Learned Image Compression with Unevenly Grouped Space-Channel Contextual Adaptive Coding
Mar 29, 2022
Recently, learned image compression techniques have achieved remarkable performance, even surpassing the best manually designed lossy image coders. They are promising to be large-scale adopted. For the sake of practicality, a thorough investigation of the architecture design of learned image compression, regarding both compression performance and running speed, is essential. In this paper, we first propose uneven channel-conditional adaptive coding, motivated by the observation of energy compaction in learned image compression. Combining the proposed uneven grouping model with existing context models, we obtain a spatial-channel contextual adaptive model to improve the coding performance without damage to running speed. Then we study the structure of the main transform and propose an efficient model, ELIC, to achieve state-of-the-art speed and compression ability. With superior performance, the proposed model also supports extremely fast preview decoding and progressive decoding, which makes the coming application of learning-based image compression more promising.