 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFloorplanVLM: A Vision-Language Model for Floorplan Vectorization
Feb 06, 2026Converting raster floorplans into engineering-grade vector graphics is challenging due to complex topology and strict geometric constraints. To address this, we present FloorplanVLM, a unified framework that reformulates floorplan vectorization as an image-conditioned sequence modeling task. Unlike pixel-based methods that rely on fragile heuristics or query-based transformers that generate fragmented rooms, our model directly outputs structured JSON sequences representing the global topology. This 'pixels-to-sequence' paradigm enables the precise and holistic constraint satisfaction of complex geometries, such as slanted walls and curved arcs. To support this data-hungry approach, we introduce a scalable data engine: we construct a large-scale dataset (Floorplan-2M) and a high-fidelity subset (Floorplan-HQ-300K) to balance geometric diversity and pixel-level precision. We then employ a progressive training strategy, using Supervised Fine-Tuning (SFT) for structural grounding and quality annealing, followed by Group Relative Policy Optimization (GRPO) for strict geometric alignment. To standardize evaluation on complex layouts, we establish and open-source FPBench-2K. Evaluated on this rigorous benchmark, FloorplanVLM demonstrates exceptional structural validity, achieving $\textbf{92.52%}$ external-wall IoU and robust generalization across non-Manhattan architectures.
Deep Learning Technology for Face Forgery Detection: A Survey
Sep 24, 2024



Currently, the rapid development of computer vision and deep learning has enabled the creation or manipulation of high-fidelity facial images and videos via deep generative approaches. This technology, also known as deepfake, has achieved dramatic progress and become increasingly popular in social media. However, the technology can generate threats to personal privacy and national security by spreading misinformation. To diminish the risks of deepfake, it is desirable to develop powerful forgery detection methods to distinguish fake faces from real faces. This paper presents a comprehensive survey of recent deep learning-based approaches for facial forgery detection. We attempt to provide the reader with a deeper understanding of the current advances as well as the major challenges for deepfake detection based on deep learning. We present an overview of deepfake techniques and analyse the characteristics of various deepfake datasets. We then provide a systematic review of different categories of deepfake detection and state-of-the-art deepfake detection methods. The drawbacks of existing detection methods are analyzed, and future research directions are discussed to address the challenges in improving both the performance and generalization of deepfake detection.
Large Language Models have Intrinsic Self-Correction Ability
Jun 21, 2024
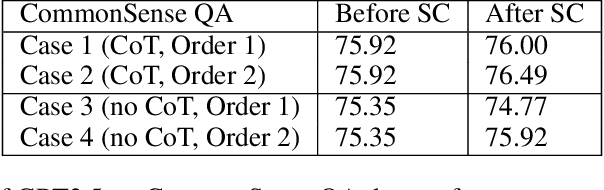
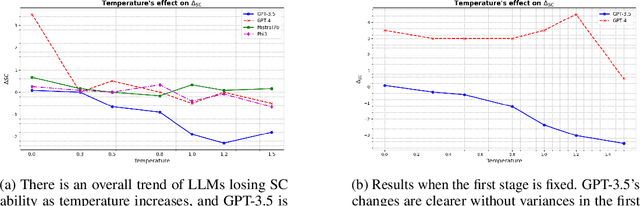
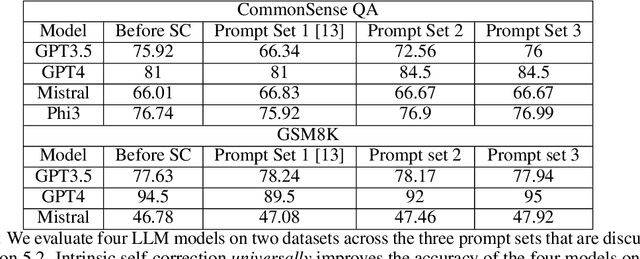
Large language models (LLMs) have attracted significant attention for their remarkable abilities in various natural language processing tasks, but they suffer from hallucinations that will cause performance degradation. One promising solution to improve the LLMs' performance is to ask LLMs to revise their answer after generation, a technique known as self-correction. Among the two types of self-correction, intrinsic self-correction is considered a promising direction because it does not utilize external knowledge. However, recent works doubt the validity of LLM's ability to conduct intrinsic self-correction. In this paper, we present a novel perspective on the intrinsic self-correction capabilities of LLMs through theoretical analyses and empirical experiments. In addition, we identify two critical factors for successful self-correction: zero temperature and fair prompts. Leveraging these factors, we demonstrate that intrinsic self-correction ability is exhibited across multiple existing LLMs. Our findings offer insights into the fundamental theories underlying the self-correction behavior of LLMs and remark on the importance of unbiased prompts and zero temperature settings in harnessing their full potential.
TALL: Thumbnail Layout for Deepfake Video Detection
Jul 14, 2023The growing threats of deepfakes to society and cybersecurity have raised enormous public concerns, and increasing efforts have been devoted to this critical topic of deepfake video detection. Existing video methods achieve good performance but are computationally intensive. This paper introduces a simple yet effective strategy named Thumbnail Layout (TALL), which transforms a video clip into a pre-defined layout to realize the preservation of spatial and temporal dependencies. Specifically, consecutive frames are masked in a fixed position in each frame to improve generalization, then resized to sub-images and rearranged into a pre-defined layout as the thumbnail. TALL is model-agnostic and extremely simple by only modifying a few lines of code. Inspired by the success of vision transformers, we incorporate TALL into Swin Transformer, forming an efficient and effective method TALL-Swin. Extensive experiments on intra-dataset and cross-dataset validate the validity and superiority of TALL and SOTA TALL-Swin. TALL-Swin achieves 90.79$\%$ AUC on the challenging cross-dataset task, FaceForensics++ $\to$ Celeb-DF. The code is available at https://github.com/rainy-xu/TALL4Deepfake.
Heterogeneous Face Recognition via Face Synthesis with Identity-Attribute Disentanglement
Jun 10, 2022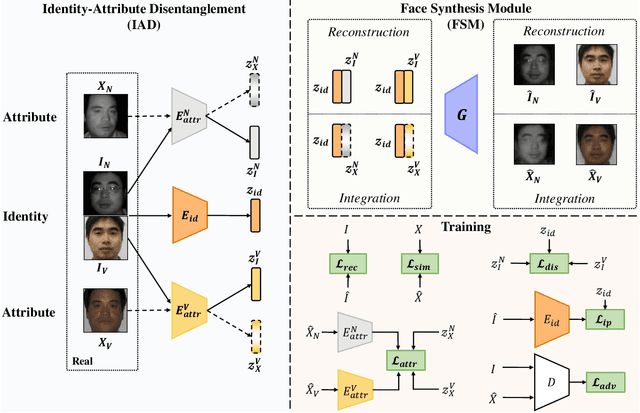


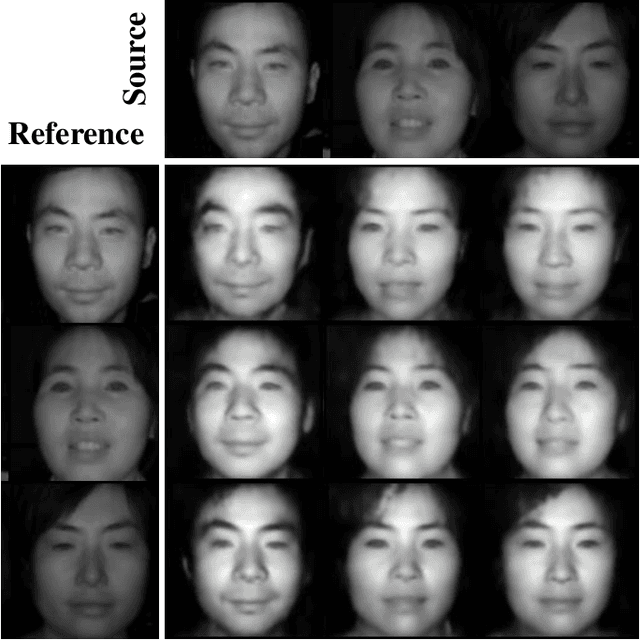
Heterogeneous Face Recognition (HFR) aims to match faces across different domains (e.g., visible to near-infrared images), which has been widely applied in authentication and forensics scenarios. However, HFR is a challenging problem because of the large cross-domain discrepancy, limited heterogeneous data pairs, and large variation of facial attributes. To address these challenges, we propose a new HFR method from the perspective of heterogeneous data augmentation, named Face Synthesis with Identity-Attribute Disentanglement (FSIAD). Firstly, the identity-attribute disentanglement (IAD) decouples face images into identity-related representations and identity-unrelated representations (called attributes), and then decreases the correlation between identities and attributes. Secondly, we devise a face synthesis module (FSM) to generate a large number of images with stochastic combinations of disentangled identities and attributes for enriching the attribute diversity of synthetic images. Both the original images and the synthetic ones are utilized to train the HFR network for tackling the challenges and improving the performance of HFR. Extensive experiments on five HFR databases validate that FSIAD obtains superior performance than previous HFR approaches. Particularly, FSIAD obtains 4.8% improvement over state of the art in terms of VR@FAR=0.01% on LAMP-HQ, the largest HFR database so far.
* Accepted for publication in IEEE Transactions on Information Forensics and Security (TIFS)
PO-ELIC: Perception-Oriented Efficient Learned Image Coding
May 28, 2022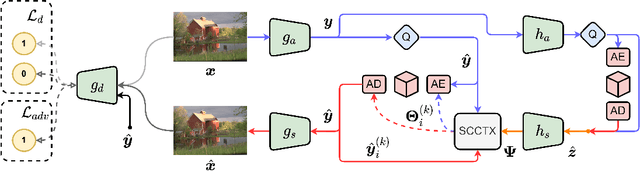

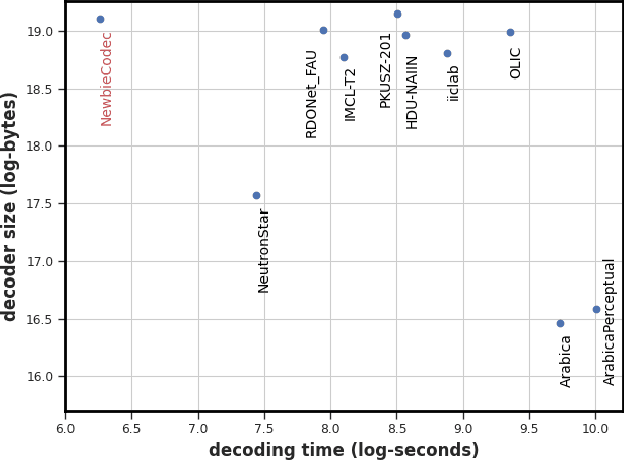

In the past years, learned image compression (LIC) has achieved remarkable performance. The recent LIC methods outperform VVC in both PSNR and MS-SSIM. However, the low bit-rate reconstructions of LIC suffer from artifacts such as blurring, color drifting and texture missing. Moreover, those varied artifacts make image quality metrics correlate badly with human perceptual quality. In this paper, we propose PO-ELIC, i.e., Perception-Oriented Efficient Learned Image Coding. To be specific, we adapt ELIC, one of the state-of-the-art LIC models, with adversarial training techniques. We apply a mixture of losses including hinge-form adversarial loss, Charbonnier loss, and style loss, to finetune the model towards better perceptual quality. Experimental results demonstrate that our method achieves comparable perceptual quality with HiFiC with much lower bitrate.
ELIC: Efficient Learned Image Compression with Unevenly Grouped Space-Channel Contextual Adaptive Coding
Mar 29, 2022
Recently, learned image compression techniques have achieved remarkable performance, even surpassing the best manually designed lossy image coders. They are promising to be large-scale adopted. For the sake of practicality, a thorough investigation of the architecture design of learned image compression, regarding both compression performance and running speed, is essential. In this paper, we first propose uneven channel-conditional adaptive coding, motivated by the observation of energy compaction in learned image compression. Combining the proposed uneven grouping model with existing context models, we obtain a spatial-channel contextual adaptive model to improve the coding performance without damage to running speed. Then we study the structure of the main transform and propose an efficient model, ELIC, to achieve state-of-the-art speed and compression ability. With superior performance, the proposed model also supports extremely fast preview decoding and progressive decoding, which makes the coming application of learning-based image compression more promising.
Post-Training Quantization for Cross-Platform Learned Image Compression
Feb 15, 2022



It has been witnessed that learned image compression has outperformed conventional image coding techniques and tends to be practical in industrial applications. One of the most critical issues that need to be considered is the non-deterministic calculation, which makes the probability prediction cross-platform inconsistent and frustrates successful decoding. We propose to solve this problem by introducing well-developed post-training quantization and making the model inference integer-arithmetic-only, which is much simpler than presently existing training and fine-tuning based approaches yet still keeps the superior rate-distortion performance of learned image compression. Based on that, we further improve the discretization of the entropy parameters and extend the deterministic inference to fit Gaussian mixture models. With our proposed methods, the current state-of-the-art image compression models can infer in a cross-platform consistent manner, which makes the further development and practice of learned image compression more promising.