 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Workflow for Materials Discovery Bridging the Gap Between Experimental Databases and Graph Neural Networks
Jan 31, 2026Incorporating Machine Learning (ML) into material property prediction has become a crucial step in accelerating materials discovery. A key challenge is the severe lack of training data, as many properties are too complicated to calculate with high-throughput first principles techniques. To address this, recent research has created experimental databases from information extracted from scientific literature. However, most existing experimental databases do not provide full atomic coordinate information, which prevents them from supporting advanced ML architectures such as Graph Neural Networks (GNNs). In this work, we propose to bridge this gap through an alignment process between experimental databases and Crystallographic Information Files (CIF) from the Inorganic Crystal Structure Database (ICSD). Our approach enables the creation of a database that can fully leverage state-of-the-art model architectures for material property prediction. It also opens the door to utilizing transfer learning to improve prediction accuracy. To validate our approach, we align NEMAD with the ICSD and compare models trained on the resulting database to those trained on NEMAD originally. We demonstrate significant improvements in both Mean Absolute Error (MAE) and Correct Classification Rate (CCR) in predicting the ordering temperatures and magnetic ground states of magnetic materials, respectively.
MaskOpt: A Large-Scale Mask Optimization Dataset to Advance AI in Integrated Circuit Manufacturing
Dec 18, 2025As integrated circuit (IC) dimensions shrink below the lithographic wavelength, optical lithography faces growing challenges from diffraction and process variability. Model-based optical proximity correction (OPC) and inverse lithography technique (ILT) remain indispensable but computationally expensive, requiring repeated simulations that limit scalability. Although deep learning has been applied to mask optimization, existing datasets often rely on synthetic layouts, disregard standard-cell hierarchy, and neglect the surrounding contexts around the mask optimization targets, thereby constraining their applicability to practical mask optimization. To advance deep learning for cell- and context-aware mask optimization, we present MaskOpt, a large-scale benchmark dataset constructed from real IC designs at the 45$\mathrm{nm}$ node. MaskOpt includes 104,714 metal-layer tiles and 121,952 via-layer tiles. Each tile is clipped at a standard-cell placement to preserve cell information, exploiting repeated logic gate occurrences. Different context window sizes are supported in MaskOpt to capture the influence of neighboring shapes from optical proximity effects. We evaluate state-of-the-art deep learning models for IC mask optimization to build up benchmarks, and the evaluation results expose distinct trade-offs across baseline models. Further context size analysis and input ablation studies confirm the importance of both surrounding geometries and cell-aware inputs in achieving accurate mask generation.
Addressing the ID-Matching Challenge in Long Video Captioning
Oct 08, 2025Generating captions for long and complex videos is both critical and challenging, with significant implications for the growing fields of text-to-video generation and multi-modal understanding. One key challenge in long video captioning is accurately recognizing the same individuals who appear in different frames, which we refer to as the ID-Matching problem. Few prior works have focused on this important issue. Those that have, usually suffer from limited generalization and depend on point-wise matching, which limits their overall effectiveness. In this paper, unlike previous approaches, we build upon LVLMs to leverage their powerful priors. We aim to unlock the inherent ID-Matching capabilities within LVLMs themselves to enhance the ID-Matching performance of captions. Specifically, we first introduce a new benchmark for assessing the ID-Matching capabilities of video captions. Using this benchmark, we investigate LVLMs containing GPT-4o, revealing key insights that the performance of ID-Matching can be improved through two methods: 1) enhancing the usage of image information and 2) increasing the quantity of information of individual descriptions. Based on these insights, we propose a novel video captioning method called Recognizing Identities for Captioning Effectively (RICE). Extensive experiments including assessments of caption quality and ID-Matching performance, demonstrate the superiority of our approach. Notably, when implemented on GPT-4o, our RICE improves the precision of ID-Matching from 50% to 90% and improves the recall of ID-Matching from 15% to 80% compared to baseline. RICE makes it possible to continuously track different individuals in the captions of long videos.
Combating Partial Perception Deficit in Autonomous Driving with Multimodal LLM Commonsense
Mar 10, 2025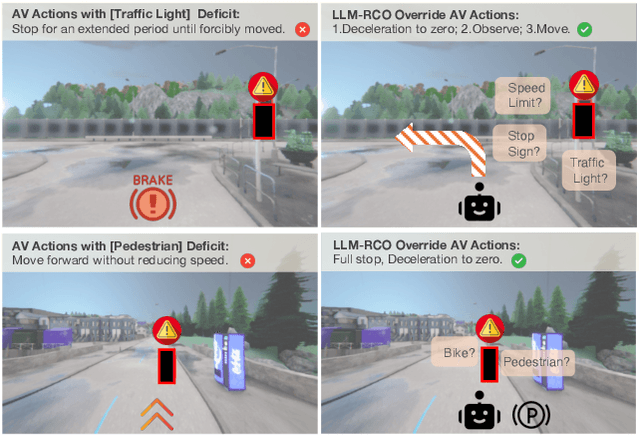
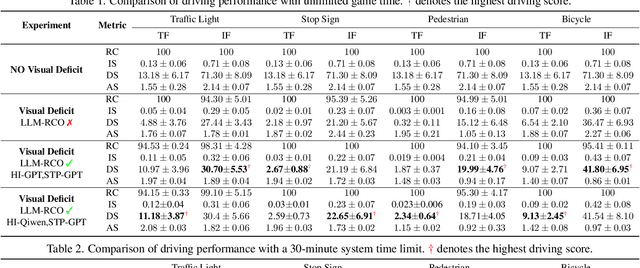
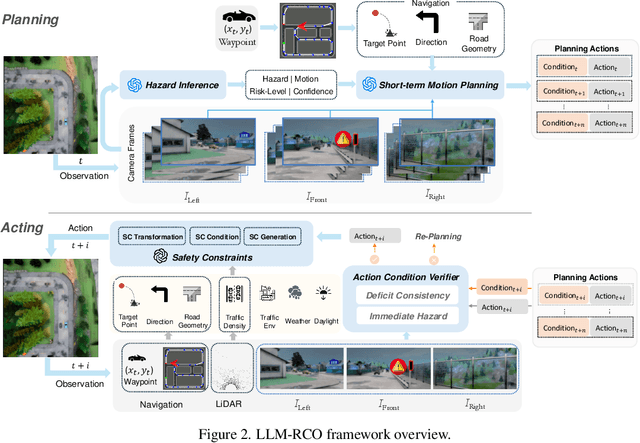

Partial perception deficits can compromise autonomous vehicle safety by disrupting environmental understanding. Current protocols typically respond with immediate stops or minimal-risk maneuvers, worsening traffic flow and lacking flexibility for rare driving scenarios. In this paper, we propose LLM-RCO, a framework leveraging large language models to integrate human-like driving commonsense into autonomous systems facing perception deficits. LLM-RCO features four key modules: hazard inference, short-term motion planner, action condition verifier, and safety constraint generator. These modules interact with the dynamic driving environment, enabling proactive and context-aware control actions to override the original control policy of autonomous agents. To improve safety in such challenging conditions, we construct DriveLM-Deficit, a dataset of 53,895 video clips featuring deficits of safety-critical objects, complete with annotations for LLM-based hazard inference and motion planning fine-tuning. Extensive experiments in adverse driving conditions with the CARLA simulator demonstrate that systems equipped with LLM-RCO significantly improve driving performance, highlighting its potential for enhancing autonomous driving resilience against adverse perception deficits. Our results also show that LLMs fine-tuned with DriveLM-Deficit can enable more proactive movements instead of conservative stops in the context of perception deficits.
Tiny-Align: Bridging Automatic Speech Recognition and Large Language Model on the Edge
Nov 21, 2024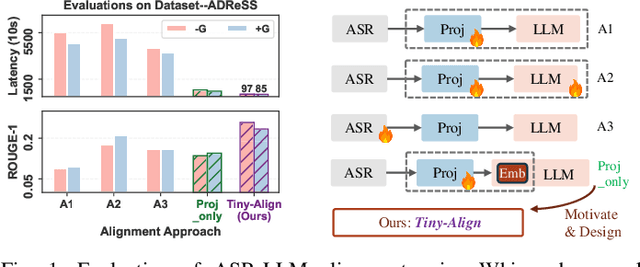
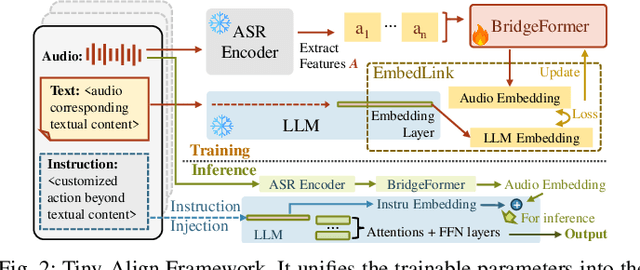
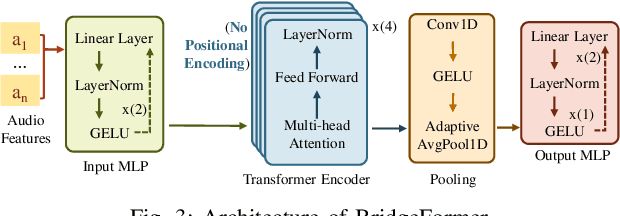
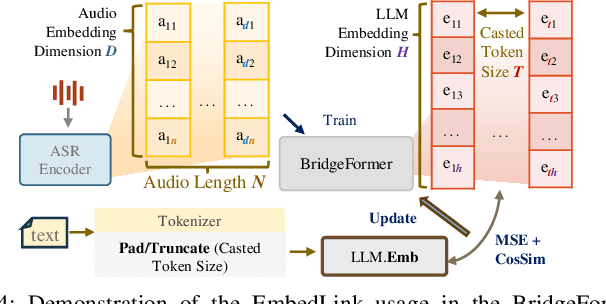
The combination of Large Language Models (LLM) and Automatic Speech Recognition (ASR), when deployed on edge devices (called edge ASR-LLM), can serve as a powerful personalized assistant to enable audio-based interaction for users. Compared to text-based interaction, edge ASR-LLM allows accessible and natural audio interactions. Unfortunately, existing ASR-LLM models are mainly trained in high-performance computing environments and produce substantial model weights, making them difficult to deploy on edge devices. More importantly, to better serve users' personalized needs, the ASR-LLM must be able to learn from each distinct user, given that audio input often contains highly personalized characteristics that necessitate personalized on-device training. Since individually fine-tuning the ASR or LLM often leads to suboptimal results due to modality-specific limitations, end-to-end training ensures seamless integration of audio features and language understanding (cross-modal alignment), ultimately enabling a more personalized and efficient adaptation on edge devices. However, due to the complex training requirements and substantial computational demands of existing approaches, cross-modal alignment between ASR audio and LLM can be challenging on edge devices. In this work, we propose a resource-efficient cross-modal alignment framework that bridges ASR and LLMs on edge devices to handle personalized audio input. Our framework enables efficient ASR-LLM alignment on resource-constrained devices like NVIDIA Jetson Orin (8GB RAM), achieving 50x training time speedup while improving the alignment quality by more than 50\%. To the best of our knowledge, this is the first work to study efficient ASR-LLM alignment on resource-constrained edge devices.
Automatic Screening for Children with Speech Disorder using Automatic Speech Recognition: Opportunities and Challenges
Oct 07, 2024



Speech is a fundamental aspect of human life, crucial not only for communication but also for cognitive, social, and academic development. Children with speech disorders (SD) face significant challenges that, if unaddressed, can result in lasting negative impacts. Traditionally, speech and language assessments (SLA) have been conducted by skilled speech-language pathologists (SLPs), but there is a growing need for efficient and scalable SLA methods powered by artificial intelligence. This position paper presents a survey of existing techniques suitable for automating SLA pipelines, with an emphasis on adapting automatic speech recognition (ASR) models for children's speech, an overview of current SLAs and their automated counterparts to demonstrate the feasibility of AI-enhanced SLA pipelines, and a discussion of practical considerations, including accessibility and privacy concerns, associated with the deployment of AI-powered SLAs.
Large Language Models have Intrinsic Self-Correction Ability
Jun 21, 2024
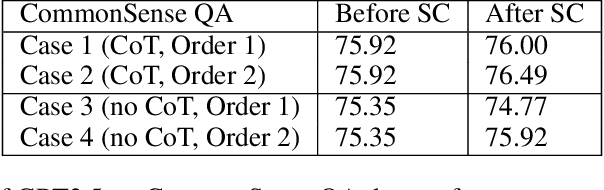
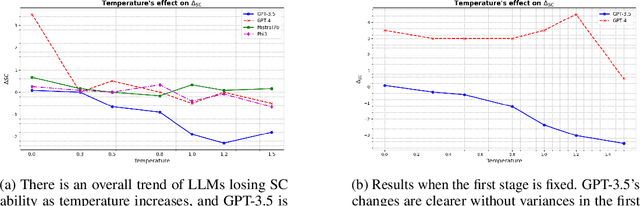
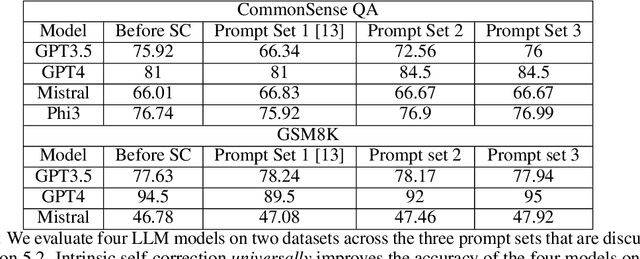
Large language models (LLMs) have attracted significant attention for their remarkable abilities in various natural language processing tasks, but they suffer from hallucinations that will cause performance degradation. One promising solution to improve the LLMs' performance is to ask LLMs to revise their answer after generation, a technique known as self-correction. Among the two types of self-correction, intrinsic self-correction is considered a promising direction because it does not utilize external knowledge. However, recent works doubt the validity of LLM's ability to conduct intrinsic self-correction. In this paper, we present a novel perspective on the intrinsic self-correction capabilities of LLMs through theoretical analyses and empirical experiments. In addition, we identify two critical factors for successful self-correction: zero temperature and fair prompts. Leveraging these factors, we demonstrate that intrinsic self-correction ability is exhibited across multiple existing LLMs. Our findings offer insights into the fundamental theories underlying the self-correction behavior of LLMs and remark on the importance of unbiased prompts and zero temperature settings in harnessing their full potential.
FL-NAS: Towards Fairness of NAS for Resource Constrained Devices via Large Language Models
Feb 09, 2024Neural Architecture Search (NAS) has become the de fecto tools in the industry in automating the design of deep neural networks for various applications, especially those driven by mobile and edge devices with limited computing resources. The emerging large language models (LLMs), due to their prowess, have also been incorporated into NAS recently and show some promising results. This paper conducts further exploration in this direction by considering three important design metrics simultaneously, i.e., model accuracy, fairness, and hardware deployment efficiency. We propose a novel LLM-based NAS framework, FL-NAS, in this paper, and show experimentally that FL-NAS can indeed find high-performing DNNs, beating state-of-the-art DNN models by orders-of-magnitude across almost all design considerations.
Distributionally Robust Optimization Efficiently Solves Offline Reinforcement Learning
May 22, 2023

Offline reinforcement learning aims to find the optimal policy from a pre-collected dataset without active exploration. This problem is faced with major challenges, such as a limited amount of data and distribution shift. Existing studies employ the principle of pessimism in face of uncertainty, and penalize rewards for less visited state-action pairs. In this paper, we directly model the uncertainty in the transition kernel using an uncertainty set, and then employ the approach of distributionally robust optimization that optimizes the worst-case performance over the uncertainty set. We first design a Hoeffding-style uncertainty set, which guarantees that the true transition kernel lies in the uncertainty set with high probability. We theoretically prove that it achieves an $\epsilon$-accuracy with a sample complexity of $\mathcal{O}\left((1-\gamma)^{-4}\epsilon^{-2}SC^{\pi^*} \right)$, where $\gamma$ is the discount factor, $C^{\pi^*}$ is the single-policy concentrability for any comparator policy $\pi^*$, and $S$ is the number of states. We further design a Bernstein-style uncertainty set, which does not necessarily guarantee the true transition kernel lies in the uncertainty set. We show an improved and near-optimal sample complexity of $\mathcal{O}\left((1-\gamma)^{-3}\epsilon^{-2}\left(SC^{\pi^*}+(\mu_{\min})^{-1}\right) \right)$, where $\mu_{\min}$ denotes the minimal non-zero entry of the behavior distribution. In addition, the computational complexity of our algorithms is the same as one of the LCB-based methods in the literature. Our results demonstrate that distributionally robust optimization method can also efficiently solve offline reinforcement learning.
Fabric Surface Characterization: Assessment of Deep Learning-based Texture Representations Using a Challenging Dataset
Mar 16, 2020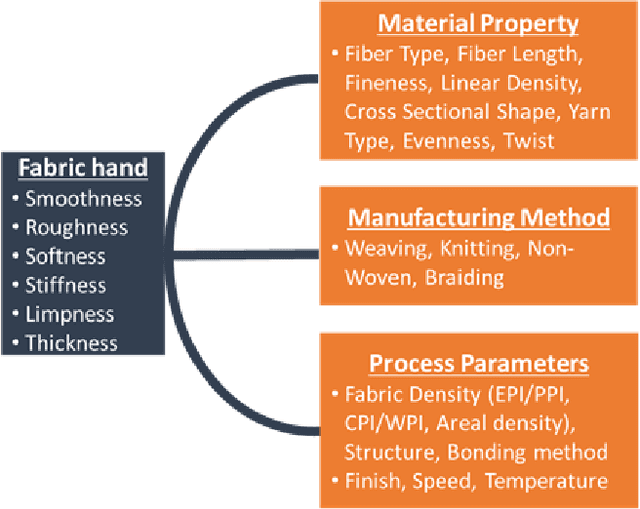
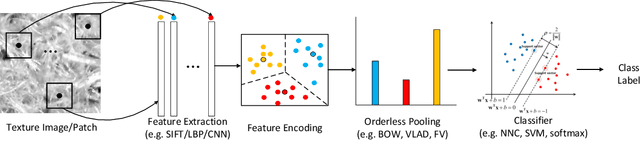


Tactile sensing or fabric hand plays a critical role in an individual's decision to buy a certain fabric from the range of available fabrics for a desired application. Therefore, textile and clothing manufacturers have long been in search of an objective method for assessing fabric hand, which can then be used to engineer fabrics with a desired hand. Recognizing textures and materials in real-world images has played an important role in object recognition and scene understanding. In this paper, we explore how to computationally characterize apparent or latent properties (e.g., surface smoothness) of materials, i.e., computational material surface characterization, which moves a step further beyond material recognition. We formulate the problem as a very fine-grained texture classification problem, and study how deep learning-based texture representation techniques can help tackle the task. We introduce a new, large-scale challenging microscopic material surface dataset (CoMMonS), geared towards an automated fabric quality assessment mechanism in an intelligent manufacturing system. We then conduct a comprehensive evaluation of state-of-the-art deep learning-based methods for texture classification using CoMMonS. Additionally, we propose a multi-level texture encoding and representation network (MuLTER), which simultaneously leverages low- and high-level features to maintain both texture details and spatial information in the texture representation. Our results show that, in comparison with the state-of-the-art deep texture descriptors, MuLTER yields higher accuracy not only on our CoMMonS dataset for material characterization, but also on established datasets such as MINC-2500 and GTOS-mobile for material recognition.