 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombating Partial Perception Deficit in Autonomous Driving with Multimodal LLM Commonsense
Mar 10, 2025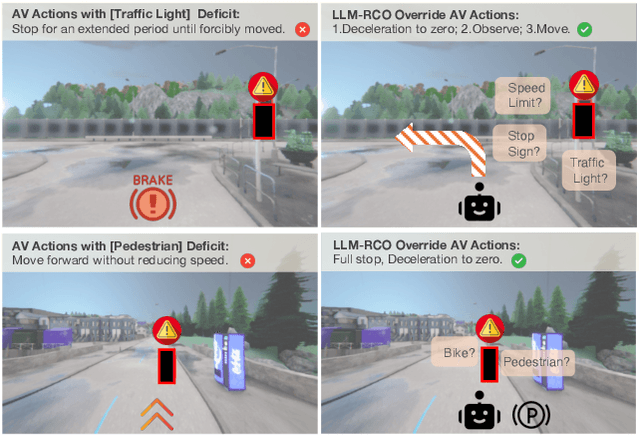
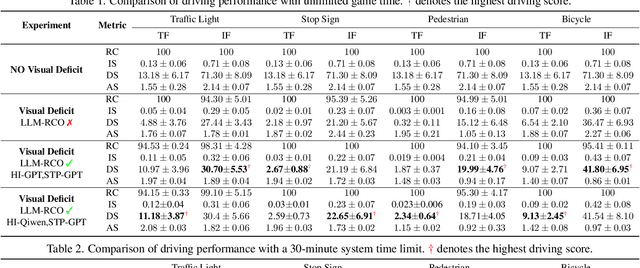
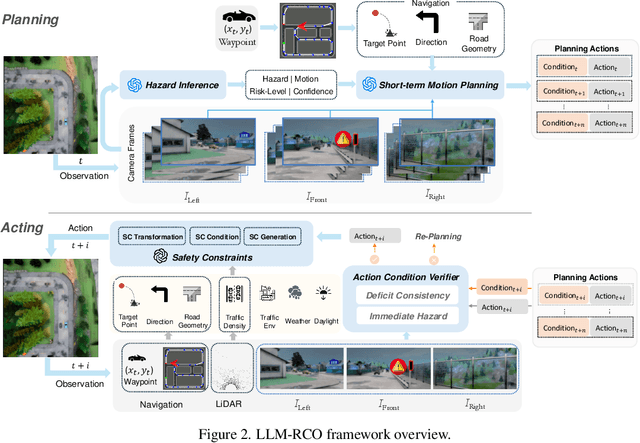

Partial perception deficits can compromise autonomous vehicle safety by disrupting environmental understanding. Current protocols typically respond with immediate stops or minimal-risk maneuvers, worsening traffic flow and lacking flexibility for rare driving scenarios. In this paper, we propose LLM-RCO, a framework leveraging large language models to integrate human-like driving commonsense into autonomous systems facing perception deficits. LLM-RCO features four key modules: hazard inference, short-term motion planner, action condition verifier, and safety constraint generator. These modules interact with the dynamic driving environment, enabling proactive and context-aware control actions to override the original control policy of autonomous agents. To improve safety in such challenging conditions, we construct DriveLM-Deficit, a dataset of 53,895 video clips featuring deficits of safety-critical objects, complete with annotations for LLM-based hazard inference and motion planning fine-tuning. Extensive experiments in adverse driving conditions with the CARLA simulator demonstrate that systems equipped with LLM-RCO significantly improve driving performance, highlighting its potential for enhancing autonomous driving resilience against adverse perception deficits. Our results also show that LLMs fine-tuned with DriveLM-Deficit can enable more proactive movements instead of conservative stops in the context of perception deficits.
Recognize Any Surgical Object: Unleashing the Power of Weakly-Supervised Data
Jan 25, 2025



We present RASO, a foundation model designed to Recognize Any Surgical Object, offering robust open-set recognition capabilities across a broad range of surgical procedures and object classes, in both surgical images and videos. RASO leverages a novel weakly-supervised learning framework that generates tag-image-text pairs automatically from large-scale unannotated surgical lecture videos, significantly reducing the need for manual annotations. Our scalable data generation pipeline gatherers to 2,200 surgical procedures and produces 3.6 million tag annotations across 2,066 unique surgical tags. Our experiments show that RASO achieves improvements of 2.9 mAP, 4.5 mAP, 10.6 mAP, and 7.2 mAP on four standard surgical benchmarks respectively in zero-shot settings, and surpasses state-of-the-art models in supervised surgical action recognition tasks. We will open-source our code, model, and dataset to facilitate further research.
Tiny-Align: Bridging Automatic Speech Recognition and Large Language Model on the Edge
Nov 21, 2024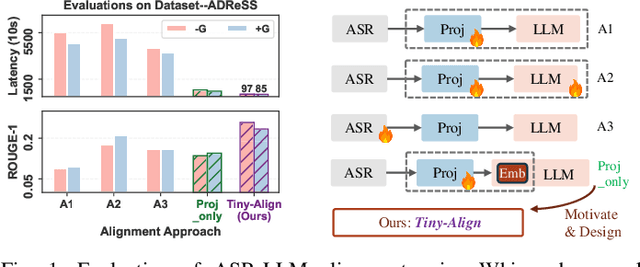
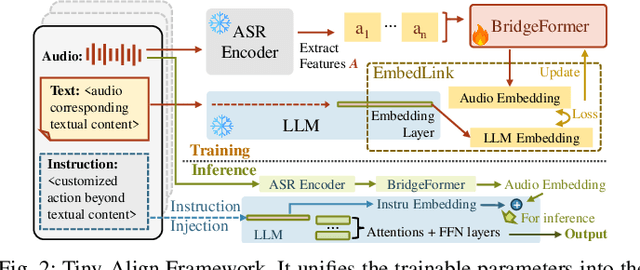
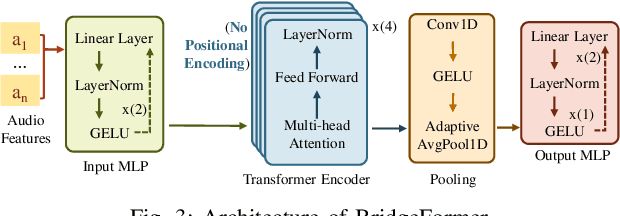
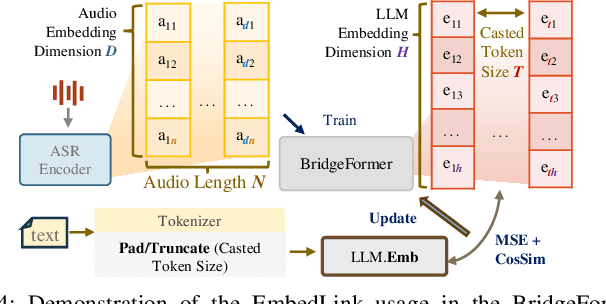
The combination of Large Language Models (LLM) and Automatic Speech Recognition (ASR), when deployed on edge devices (called edge ASR-LLM), can serve as a powerful personalized assistant to enable audio-based interaction for users. Compared to text-based interaction, edge ASR-LLM allows accessible and natural audio interactions. Unfortunately, existing ASR-LLM models are mainly trained in high-performance computing environments and produce substantial model weights, making them difficult to deploy on edge devices. More importantly, to better serve users' personalized needs, the ASR-LLM must be able to learn from each distinct user, given that audio input often contains highly personalized characteristics that necessitate personalized on-device training. Since individually fine-tuning the ASR or LLM often leads to suboptimal results due to modality-specific limitations, end-to-end training ensures seamless integration of audio features and language understanding (cross-modal alignment), ultimately enabling a more personalized and efficient adaptation on edge devices. However, due to the complex training requirements and substantial computational demands of existing approaches, cross-modal alignment between ASR audio and LLM can be challenging on edge devices. In this work, we propose a resource-efficient cross-modal alignment framework that bridges ASR and LLMs on edge devices to handle personalized audio input. Our framework enables efficient ASR-LLM alignment on resource-constrained devices like NVIDIA Jetson Orin (8GB RAM), achieving 50x training time speedup while improving the alignment quality by more than 50\%. To the best of our knowledge, this is the first work to study efficient ASR-LLM alignment on resource-constrained edge devices.
NVCiM-PT: An NVCiM-assisted Prompt Tuning Framework for Edge LLMs
Nov 12, 2024



Large Language Models (LLMs) deployed on edge devices, known as edge LLMs, need to continuously fine-tune their model parameters from user-generated data under limited resource constraints. However, most existing learning methods are not applicable for edge LLMs because of their reliance on high resources and low learning capacity. Prompt tuning (PT) has recently emerged as an effective fine-tuning method for edge LLMs by only modifying a small portion of LLM parameters, but it suffers from user domain shifts, resulting in repetitive training and losing resource efficiency. Conventional techniques to address domain shift issues often involve complex neural networks and sophisticated training, which are incompatible for PT for edge LLMs. Therefore, an open research question is how to address domain shift issues for edge LLMs with limited resources. In this paper, we propose a prompt tuning framework for edge LLMs, exploiting the benefits offered by non-volatile computing-in-memory (NVCiM) architectures. We introduce a novel NVCiM-assisted PT framework, where we narrow down the core operations to matrix-matrix multiplication, which can then be accelerated by performing in-situ computation on NVCiM. To the best of our knowledge, this is the first work employing NVCiM to improve the edge LLM PT performance.
An Adaptive System for Wearable Devices to Detect Stress Using Physiological Signals
Jul 21, 2024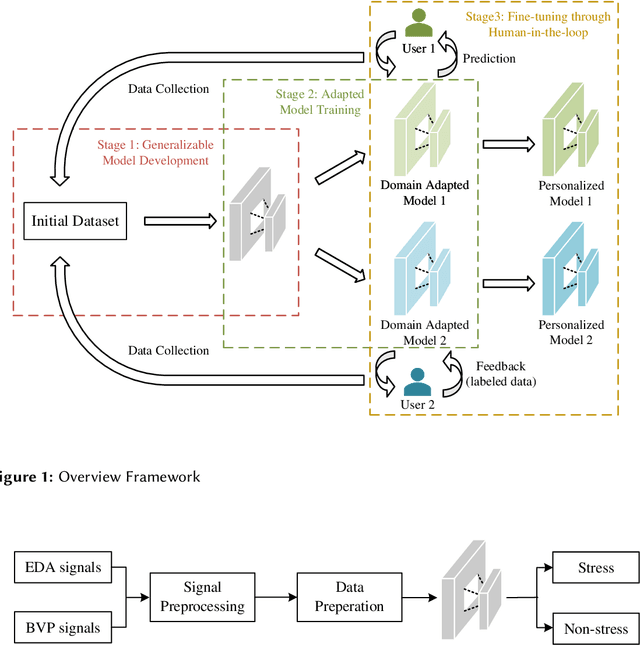

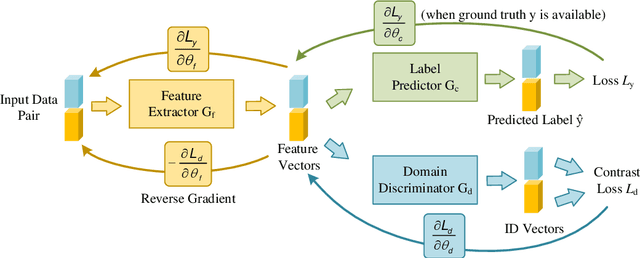
Timely stress detection is crucial for protecting vulnerable groups from long-term detrimental effects by enabling early intervention. Wearable devices, by collecting real-time physiological signals, offer a solution for accurate stress detection accommodating individual differences. This position paper introduces an adaptive framework for personalized stress detection using PPG and EDA signals. Unlike traditional methods that rely on a generalized model, which may suffer performance drops when applied to new users due to domain shifts, this framework aims to provide each user with a personalized model for higher stress detection accuracy. The framework involves three stages: developing a generalized model offline with an initial dataset, adapting the model to the user's unlabeled data, and fine-tuning it with a small set of labeled data obtained through user interaction. This approach not only offers a foundation for mobile applications that provide personalized stress detection and intervention but also has the potential to address a wider range of mental health issues beyond stress detection using physiological signals.
Empirical Guidelines for Deploying LLMs onto Resource-constrained Edge Devices
Jun 06, 2024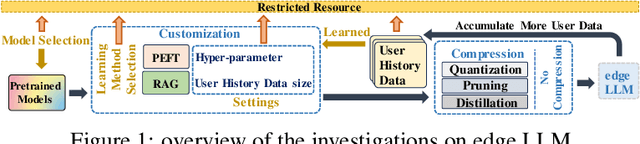
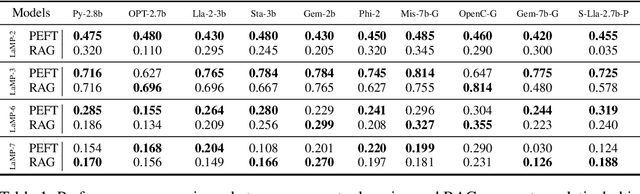
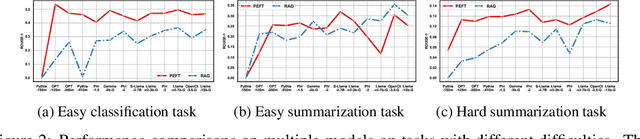

The scaling laws have become the de facto guidelines for designing large language models (LLMs), but they were studied under the assumption of unlimited computing resources for both training and inference. As LLMs are increasingly used as personalized intelligent assistants, their customization (i.e., learning through fine-tuning) and deployment onto resource-constrained edge devices will become more and more prevalent. An urging but open question is how a resource-constrained computing environment would affect the design choices for a personalized LLM. We study this problem empirically in this work. In particular, we consider the tradeoffs among a number of key design factors and their intertwined impacts on learning efficiency and accuracy. The factors include the learning methods for LLM customization, the amount of personalized data used for learning customization, the types and sizes of LLMs, the compression methods of LLMs, the amount of time afforded to learn, and the difficulty levels of the target use cases. Through extensive experimentation and benchmarking, we draw a number of surprisingly insightful guidelines for deploying LLMs onto resource-constrained devices. For example, an optimal choice between parameter learning and RAG may vary depending on the difficulty of the downstream task, the longer fine-tuning time does not necessarily help the model, and a compressed LLM may be a better choice than an uncompressed LLM to learn from limited personalized data.
Robust Implementation of Retrieval-Augmented Generation on Edge-based Computing-in-Memory Architectures
May 07, 2024



Large Language Models (LLMs) deployed on edge devices learn through fine-tuning and updating a certain portion of their parameters. Although such learning methods can be optimized to reduce resource utilization, the overall required resources remain a heavy burden on edge devices. Instead, Retrieval-Augmented Generation (RAG), a resource-efficient LLM learning method, can improve the quality of the LLM-generated content without updating model parameters. However, the RAG-based LLM may involve repetitive searches on the profile data in every user-LLM interaction. This search can lead to significant latency along with the accumulation of user data. Conventional efforts to decrease latency result in restricting the size of saved user data, thus reducing the scalability of RAG as user data continuously grows. It remains an open question: how to free RAG from the constraints of latency and scalability on edge devices? In this paper, we propose a novel framework to accelerate RAG via Computing-in-Memory (CiM) architectures. It accelerates matrix multiplications by performing in-situ computation inside the memory while avoiding the expensive data transfer between the computing unit and memory. Our framework, Robust CiM-backed RAG (RoCR), utilizing a novel contrastive learning-based training method and noise-aware training, can enable RAG to efficiently search profile data with CiM. To the best of our knowledge, this is the first work utilizing CiM to accelerate RAG.
FL-NAS: Towards Fairness of NAS for Resource Constrained Devices via Large Language Models
Feb 09, 2024Neural Architecture Search (NAS) has become the de fecto tools in the industry in automating the design of deep neural networks for various applications, especially those driven by mobile and edge devices with limited computing resources. The emerging large language models (LLMs), due to their prowess, have also been incorporated into NAS recently and show some promising results. This paper conducts further exploration in this direction by considering three important design metrics simultaneously, i.e., model accuracy, fairness, and hardware deployment efficiency. We propose a novel LLM-based NAS framework, FL-NAS, in this paper, and show experimentally that FL-NAS can indeed find high-performing DNNs, beating state-of-the-art DNN models by orders-of-magnitude across almost all design considerations.
Enabling On-Device Large Language Model Personalization with Self-Supervised Data Selection and Synthesis
Dec 02, 2023After a large language model (LLM) is deployed on edge devices, it is desirable for these devices to learn from user-generated conversation data to generate user-specific and personalized responses in real-time. However, user-generated data usually contains sensitive and private information, and uploading such data to the cloud for annotation is not preferred if not prohibited. While it is possible to obtain annotation locally by directly asking users to provide preferred responses, such annotations have to be sparse to not affect user experience. In addition, the storage of edge devices is usually too limited to enable large-scale fine-tuning with full user-generated data. It remains an open question how to enable on-device LLM personalization, considering sparse annotation and limited on-device storage. In this paper, we propose a novel framework to select and store the most representative data online in a self-supervised way. Such data has a small memory footprint and allows infrequent requests of user annotations for further fine-tuning. To enhance fine-tuning quality, multiple semantically similar pairs of question texts and expected responses are generated using the LLM. Our experiments show that the proposed framework achieves the best user-specific content-generating capability (accuracy) and fine-tuning speed (performance) compared with vanilla baselines. To the best of our knowledge, this is the very first on-device LLM personalization framework.
When Automated Assessment Meets Automated Content Generation: Examining Text Quality in the Era of GPTs
Sep 25, 2023The use of machine learning (ML) models to assess and score textual data has become increasingly pervasive in an array of contexts including natural language processing, information retrieval, search and recommendation, and credibility assessment of online content. A significant disruption at the intersection of ML and text are text-generating large-language models such as generative pre-trained transformers (GPTs). We empirically assess the differences in how ML-based scoring models trained on human content assess the quality of content generated by humans versus GPTs. To do so, we propose an analysis framework that encompasses essay scoring ML-models, human and ML-generated essays, and a statistical model that parsimoniously considers the impact of type of respondent, prompt genre, and the ML model used for assessment model. A rich testbed is utilized that encompasses 18,460 human-generated and GPT-based essays. Results of our benchmark analysis reveal that transformer pretrained language models (PLMs) more accurately score human essay quality as compared to CNN/RNN and feature-based ML methods. Interestingly, we find that the transformer PLMs tend to score GPT-generated text 10-15\% higher on average, relative to human-authored documents. Conversely, traditional deep learning and feature-based ML models score human text considerably higher. Further analysis reveals that although the transformer PLMs are exclusively fine-tuned on human text, they more prominently attend to certain tokens appearing only in GPT-generated text, possibly due to familiarity/overlap in pre-training. Our framework and results have implications for text classification settings where automated scoring of text is likely to be disrupted by generative AI.