 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Tree Inference Enabled by FDSOI Ferroelectric FETs
Apr 06, 2026Artificial intelligence applications in autonomous driving, medical diagnostics, and financial systems increasingly demand machine learning models that can provide robust uncertainty quantification, interpretability, and noise resilience. Bayesian decision trees (BDTs) are attractive for these tasks because they combine probabilistic reasoning, interpretable decision-making, and robustness to noise. However, existing hardware implementations of BDTs based on CPUs and GPUs are limited by memory bottlenecks and irregular processing patterns, while multi-platform solutions exploiting analog content-addressable memory (ACAM) and Gaussian random number generators (GRNGs) introduce integration complexity and energy overheads. Here we report a monolithic FDSOI-FeFET hardware platform that natively supports both ACAM and GRNG functionalities. The ferroelectric polarization of FeFETs enables compact, energy-efficient multi-bit storage for ACAM, and band-to-band tunneling in the gate-to-drain overlap region and subsequent hole storage in the floating body provides a high-quality entropy source for GRNG. System-level evaluations demonstrate that the proposed architecture provides robust uncertainty estimation, interpretability, and noise tolerance with high energy efficiency. Under both dataset noise and device variations, it achieves over 40% higher classification accuracy on MNIST compared to conventional decision trees. Moreover, it delivers more than two orders of magnitude speedup over CPU and GPU baselines and over four orders of magnitude improvement in energy efficiency, making it a scalable solution for deploying BDTs in resource-constrained and safety-critical environments.
A Unified Memory Perspective for Probabilistic Trustworthy AI
Mar 26, 2026Trustworthy artificial intelligence increasingly relies on probabilistic computation to achieve robustness, interpretability, security and privacy. In practical systems, such workloads interleave deterministic data access with repeated stochastic sampling across models, data paths and system functions, shifting performance bottlenecks from arithmetic units to memory systems that must deliver both data and randomness. Here we present a unified data-access perspective in which deterministic access is treated as a limiting case of stochastic sampling, enabling both modes to be analyzed within a common framework. This view reveals that increasing stochastic demand reduces effective data-access efficiency and can drive systems into entropy-limited operation. Based on this insight, we define memory-level evaluation criteria, including unified operation, distribution programmability, efficiency, robustness to hardware non-idealities and parallel compatibility. Using these criteria, we analyze limitations of conventional architectures and examine emerging probabilistic compute-in-memory approaches that integrate sampling with memory access, outlining pathways toward scalable hardware for trustworthy AI.
A 65 nm Bayesian Neural Network Accelerator with 360 fJ/Sample In-Word GRNG for AI Uncertainty Estimation
Jan 08, 2025



Uncertainty estimation is an indispensable capability for AI-enabled, safety-critical applications, e.g. autonomous vehicles or medical diagnosis. Bayesian neural networks (BNNs) use Bayesian statistics to provide both classification predictions and uncertainty estimation, but they suffer from high computational overhead associated with random number generation and repeated sample iterations. Furthermore, BNNs are not immediately amenable to acceleration through compute-in-memory architectures due to the frequent memory writes necessary after each RNG operation. To address these challenges, we present an ASIC that integrates 360 fJ/Sample Gaussian RNG directly into the SRAM memory words. This integration reduces RNG overhead and enables fully-parallel compute-in-memory operations for BNNs. The prototype chip achieves 5.12 GSa/s RNG throughput and 102 GOp/s neural network throughput while occupying 0.45 mm2, bringing AI uncertainty estimation to edge computation.
LaMAGIC: Language-Model-based Topology Generation for Analog Integrated Circuits
Jul 19, 2024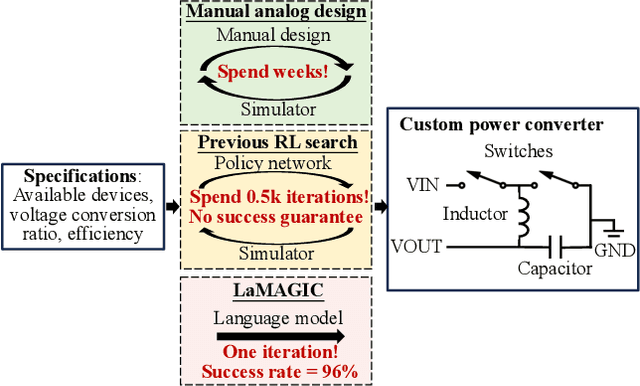
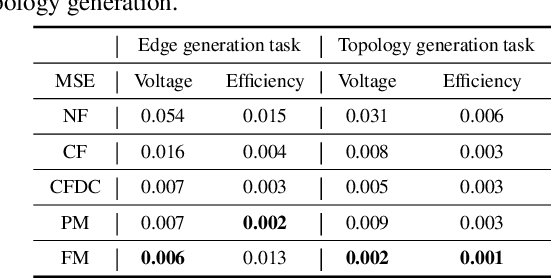
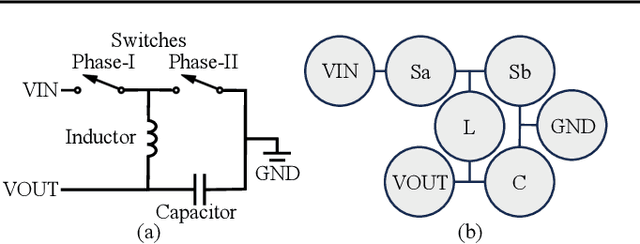
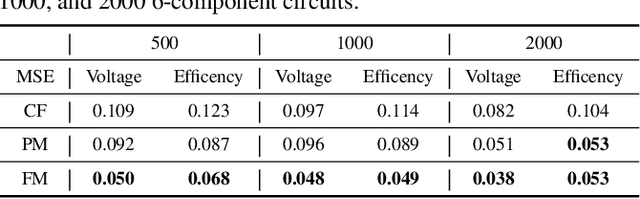
In the realm of electronic and electrical engineering, automation of analog circuit is increasingly vital given the complexity and customized requirements of modern applications. However, existing methods only develop search-based algorithms that require many simulation iterations to design a custom circuit topology, which is usually a time-consuming process. To this end, we introduce LaMAGIC, a pioneering language model-based topology generation model that leverages supervised finetuning for automated analog circuit design. LaMAGIC can efficiently generate an optimized circuit design from the custom specification in a single pass. Our approach involves a meticulous development and analysis of various input and output formulations for circuit. These formulations can ensure canonical representations of circuits and align with the autoregressive nature of LMs to effectively addressing the challenges of representing analog circuits as graphs. The experimental results show that LaMAGIC achieves a success rate of up to 96\% under a strict tolerance of 0.01. We also examine the scalability and adaptability of LaMAGIC, specifically testing its performance on more complex circuits. Our findings reveal the enhanced effectiveness of our adjacency matrix-based circuit formulation with floating-point input, suggesting its suitability for handling intricate circuit designs. This research not only demonstrates the potential of language models in graph generation, but also builds a foundational framework for future explorations in automated analog circuit design.
Robust Implementation of Retrieval-Augmented Generation on Edge-based Computing-in-Memory Architectures
May 07, 2024



Large Language Models (LLMs) deployed on edge devices learn through fine-tuning and updating a certain portion of their parameters. Although such learning methods can be optimized to reduce resource utilization, the overall required resources remain a heavy burden on edge devices. Instead, Retrieval-Augmented Generation (RAG), a resource-efficient LLM learning method, can improve the quality of the LLM-generated content without updating model parameters. However, the RAG-based LLM may involve repetitive searches on the profile data in every user-LLM interaction. This search can lead to significant latency along with the accumulation of user data. Conventional efforts to decrease latency result in restricting the size of saved user data, thus reducing the scalability of RAG as user data continuously grows. It remains an open question: how to free RAG from the constraints of latency and scalability on edge devices? In this paper, we propose a novel framework to accelerate RAG via Computing-in-Memory (CiM) architectures. It accelerates matrix multiplications by performing in-situ computation inside the memory while avoiding the expensive data transfer between the computing unit and memory. Our framework, Robust CiM-backed RAG (RoCR), utilizing a novel contrastive learning-based training method and noise-aware training, can enable RAG to efficiently search profile data with CiM. To the best of our knowledge, this is the first work utilizing CiM to accelerate RAG.
Hardware-aware Pruning of DNNs using LFSR-Generated Pseudo-Random Indices
Nov 09, 2019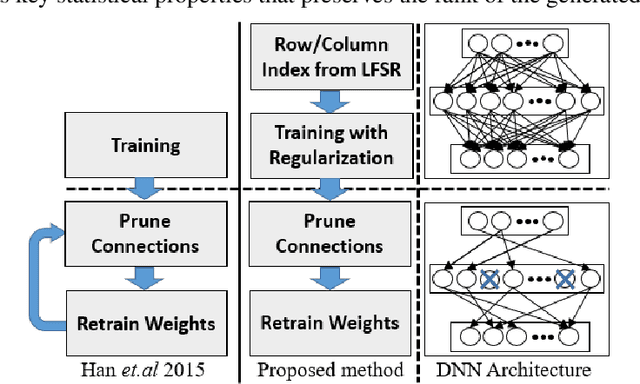
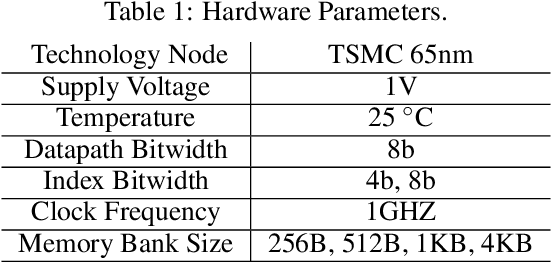
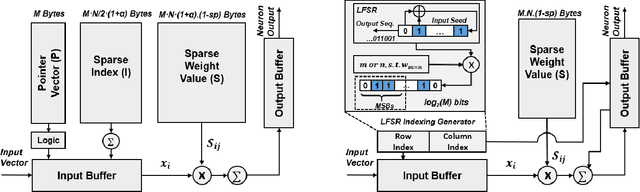
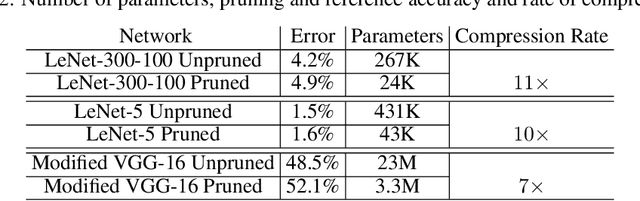
Deep neural networks (DNNs) have been emerged as the state-of-the-art algorithms in broad range of applications. To reduce the memory foot-print of DNNs, in particular for embedded applications, sparsification techniques have been proposed. Unfortunately, these techniques come with a large hardware overhead. In this paper, we present a hardware-aware pruning method where the locations of non-zero weights are derived in real-time from a Linear Feedback Shift Registers (LFSRs). Using the proposed method, we demonstrate a total saving of energy and area up to 63.96% and 64.23% for VGG-16 network on down-sampled ImageNet, respectively for iso-compression-rate and iso-accuracy.
A Light-powered, Always-On, Smart Camera with Compressed Domain Gesture Detection
Aug 16, 2016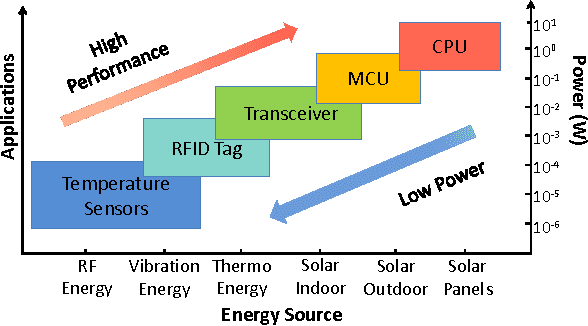

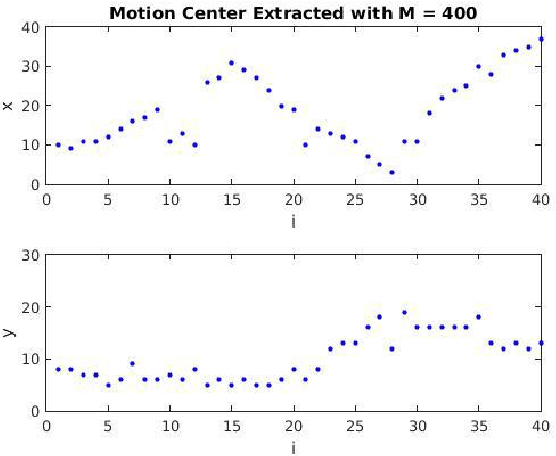
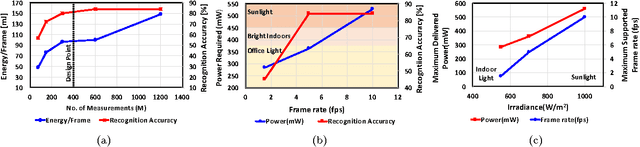
In this paper we propose an energy-efficient camera-based gesture recognition system powered by light energy for "always on" applications. Low energy consumption is achieved by directly extracting gesture features from the compressed measurements, which are the block averages and the linear combinations of the image sensor's pixel values. The gestures are recognized using a nearest-neighbour (NN) classifier followed by Dynamic Time Warping (DTW). The system has been implemented on an Analog Devices Black Fin ULP vision processor and powered by PV cells whose output is regulated by TI's DC-DC buck converter with Maximum Power Point Tracking (MPPT). Measured data reveals that with only 400 compressed measurements (768x compression ratio) per frame, the system is able to recognize key wake-up gestures with greater than 80% accuracy and only 95mJ of energy per frame. Owing to its fully self-powered operation, the proposed system can find wide applications in "always-on" vision systems such as in surveillance, robotics and consumer electronics with touch-less operation.