 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Pretraining Robust ASR Foundation Model with Acoustic-Aware Data Augmentation
May 27, 2025Whisper's robust performance in automatic speech recognition (ASR) is often attributed to its massive 680k-hour training set, an impractical scale for most researchers. In this work, we examine how linguistic and acoustic diversity in training data affect the robustness of the ASR model and reveal that transcription generalization is primarily driven by acoustic variation rather than linguistic richness. We find that targeted acoustic augmentation methods could significantly improve the generalization ability of ASR models, reducing word-error rates by up to 19.24 percent on unseen datasets when training on the 960-hour Librispeech dataset. These findings highlight strategic acoustically focused data augmentation as a promising alternative to massive datasets for building robust ASR models, offering a potential solution to future foundation ASR models when massive human speech data is lacking.
FP64 is All You Need: Rethinking Failure Modes in Physics-Informed Neural Networks
May 16, 2025Physics Informed Neural Networks (PINNs) often exhibit failure modes in which the PDE residual loss converges while the solution error stays large, a phenomenon traditionally blamed on local optima separated from the true solution by steep loss barriers. We challenge this understanding by demonstrate that the real culprit is insufficient arithmetic precision: with standard FP32, the LBFGS optimizer prematurely satisfies its convergence test, freezing the network in a spurious failure phase. Simply upgrading to FP64 rescues optimization, enabling vanilla PINNs to solve PDEs without any failure modes. These results reframe PINN failure modes as precision induced stalls rather than inescapable local minima and expose a three stage training dynamic unconverged, failure, success whose boundaries shift with numerical precision. Our findings emphasize that rigorous arithmetic precision is the key to dependable PDE solving with neural networks.
Combating Partial Perception Deficit in Autonomous Driving with Multimodal LLM Commonsense
Mar 10, 2025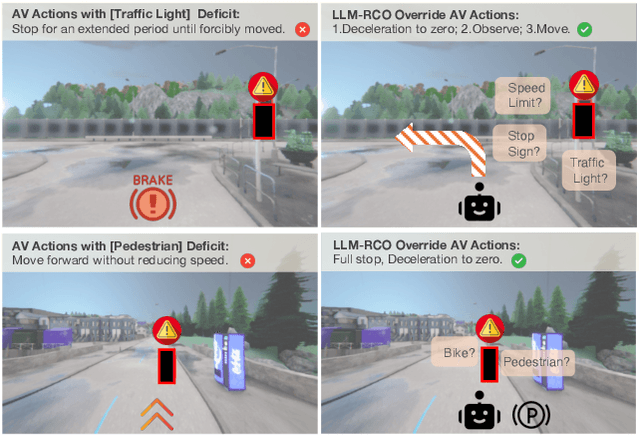
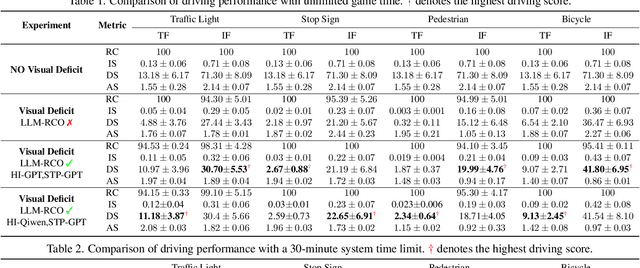
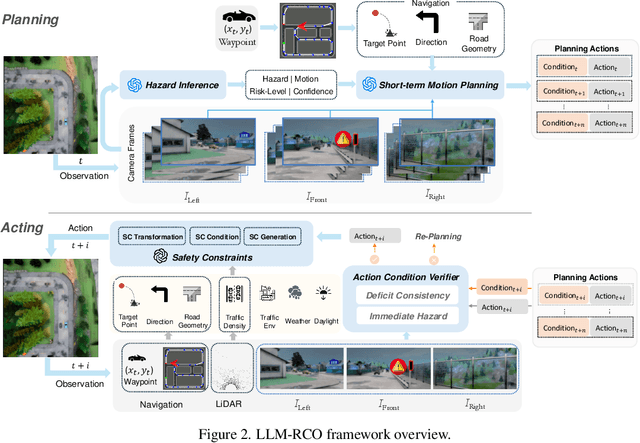

Partial perception deficits can compromise autonomous vehicle safety by disrupting environmental understanding. Current protocols typically respond with immediate stops or minimal-risk maneuvers, worsening traffic flow and lacking flexibility for rare driving scenarios. In this paper, we propose LLM-RCO, a framework leveraging large language models to integrate human-like driving commonsense into autonomous systems facing perception deficits. LLM-RCO features four key modules: hazard inference, short-term motion planner, action condition verifier, and safety constraint generator. These modules interact with the dynamic driving environment, enabling proactive and context-aware control actions to override the original control policy of autonomous agents. To improve safety in such challenging conditions, we construct DriveLM-Deficit, a dataset of 53,895 video clips featuring deficits of safety-critical objects, complete with annotations for LLM-based hazard inference and motion planning fine-tuning. Extensive experiments in adverse driving conditions with the CARLA simulator demonstrate that systems equipped with LLM-RCO significantly improve driving performance, highlighting its potential for enhancing autonomous driving resilience against adverse perception deficits. Our results also show that LLMs fine-tuned with DriveLM-Deficit can enable more proactive movements instead of conservative stops in the context of perception deficits.
Towards Understanding Multi-Round Large Language Model Reasoning: Approximability, Learnability and Generalizability
Mar 05, 2025Recent advancements in cognitive science and multi-round reasoning techniques for Large Language Models (LLMs) suggest that iterative thinking processes improve problem-solving performance in complex tasks. Inspired by this, approaches like Chain-of-Thought, debating, and self-refinement have been applied to auto-regressive LLMs, achieving significant successes in tasks such as mathematical reasoning, commonsense reasoning, and multi-hop question answering. Despite these successes, the theoretical basis for how multi-round reasoning enhances problem-solving abilities remains underexplored. In this work, we investigate the approximation, learnability, and generalization properties of multi-round auto-regressive models. We show that Transformers with finite context windows are universal approximators for steps of Turing-computable functions and can approximate any Turing-computable sequence-to-sequence function through multi-round reasoning. We extend PAC learning to sequence generation and demonstrate that multi-round generation is learnable even when the sequence length exceeds the model's context window. Finally, we examine how generalization error propagates across rounds, and show how the aforementioned approaches can help constrain this error, ensuring outputs stay within an expectation boundary. This work sheds light on the systemic theoretical foundations of multi-round sequence learning and reasoning, emphasizing its role in inference complexity.
Recognize Any Surgical Object: Unleashing the Power of Weakly-Supervised Data
Jan 25, 2025



We present RASO, a foundation model designed to Recognize Any Surgical Object, offering robust open-set recognition capabilities across a broad range of surgical procedures and object classes, in both surgical images and videos. RASO leverages a novel weakly-supervised learning framework that generates tag-image-text pairs automatically from large-scale unannotated surgical lecture videos, significantly reducing the need for manual annotations. Our scalable data generation pipeline gatherers to 2,200 surgical procedures and produces 3.6 million tag annotations across 2,066 unique surgical tags. Our experiments show that RASO achieves improvements of 2.9 mAP, 4.5 mAP, 10.6 mAP, and 7.2 mAP on four standard surgical benchmarks respectively in zero-shot settings, and surpasses state-of-the-art models in supervised surgical action recognition tasks. We will open-source our code, model, and dataset to facilitate further research.
Tiny-Align: Bridging Automatic Speech Recognition and Large Language Model on the Edge
Nov 21, 2024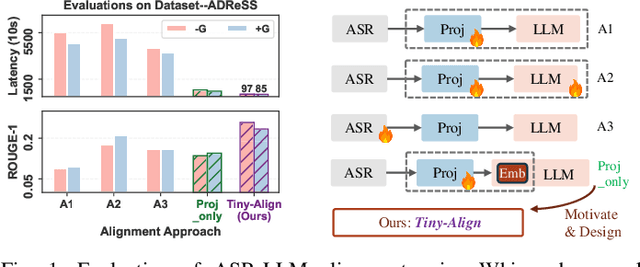
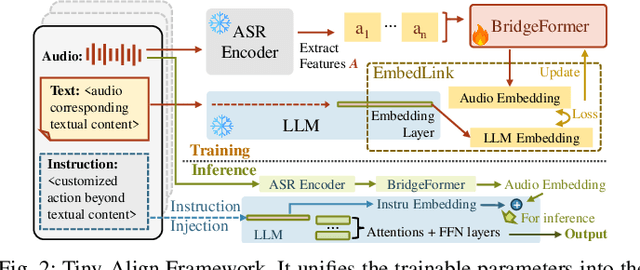
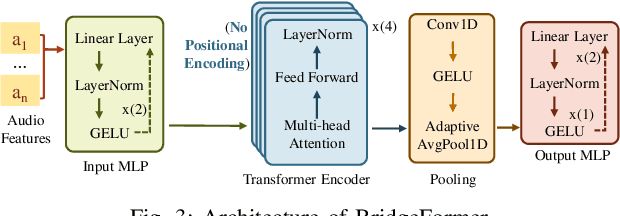
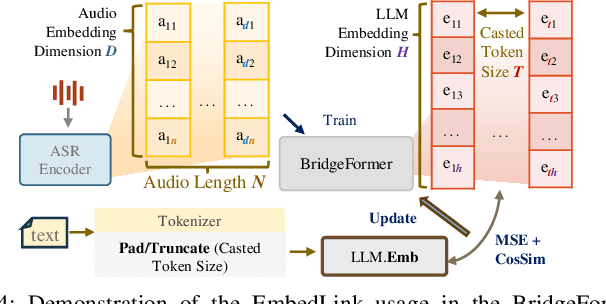
The combination of Large Language Models (LLM) and Automatic Speech Recognition (ASR), when deployed on edge devices (called edge ASR-LLM), can serve as a powerful personalized assistant to enable audio-based interaction for users. Compared to text-based interaction, edge ASR-LLM allows accessible and natural audio interactions. Unfortunately, existing ASR-LLM models are mainly trained in high-performance computing environments and produce substantial model weights, making them difficult to deploy on edge devices. More importantly, to better serve users' personalized needs, the ASR-LLM must be able to learn from each distinct user, given that audio input often contains highly personalized characteristics that necessitate personalized on-device training. Since individually fine-tuning the ASR or LLM often leads to suboptimal results due to modality-specific limitations, end-to-end training ensures seamless integration of audio features and language understanding (cross-modal alignment), ultimately enabling a more personalized and efficient adaptation on edge devices. However, due to the complex training requirements and substantial computational demands of existing approaches, cross-modal alignment between ASR audio and LLM can be challenging on edge devices. In this work, we propose a resource-efficient cross-modal alignment framework that bridges ASR and LLMs on edge devices to handle personalized audio input. Our framework enables efficient ASR-LLM alignment on resource-constrained devices like NVIDIA Jetson Orin (8GB RAM), achieving 50x training time speedup while improving the alignment quality by more than 50\%. To the best of our knowledge, this is the first work to study efficient ASR-LLM alignment on resource-constrained edge devices.
NVCiM-PT: An NVCiM-assisted Prompt Tuning Framework for Edge LLMs
Nov 12, 2024



Large Language Models (LLMs) deployed on edge devices, known as edge LLMs, need to continuously fine-tune their model parameters from user-generated data under limited resource constraints. However, most existing learning methods are not applicable for edge LLMs because of their reliance on high resources and low learning capacity. Prompt tuning (PT) has recently emerged as an effective fine-tuning method for edge LLMs by only modifying a small portion of LLM parameters, but it suffers from user domain shifts, resulting in repetitive training and losing resource efficiency. Conventional techniques to address domain shift issues often involve complex neural networks and sophisticated training, which are incompatible for PT for edge LLMs. Therefore, an open research question is how to address domain shift issues for edge LLMs with limited resources. In this paper, we propose a prompt tuning framework for edge LLMs, exploiting the benefits offered by non-volatile computing-in-memory (NVCiM) architectures. We introduce a novel NVCiM-assisted PT framework, where we narrow down the core operations to matrix-matrix multiplication, which can then be accelerated by performing in-situ computation on NVCiM. To the best of our knowledge, this is the first work employing NVCiM to improve the edge LLM PT performance.
Automatic Screening for Children with Speech Disorder using Automatic Speech Recognition: Opportunities and Challenges
Oct 07, 2024



Speech is a fundamental aspect of human life, crucial not only for communication but also for cognitive, social, and academic development. Children with speech disorders (SD) face significant challenges that, if unaddressed, can result in lasting negative impacts. Traditionally, speech and language assessments (SLA) have been conducted by skilled speech-language pathologists (SLPs), but there is a growing need for efficient and scalable SLA methods powered by artificial intelligence. This position paper presents a survey of existing techniques suitable for automating SLA pipelines, with an emphasis on adapting automatic speech recognition (ASR) models for children's speech, an overview of current SLAs and their automated counterparts to demonstrate the feasibility of AI-enhanced SLA pipelines, and a discussion of practical considerations, including accessibility and privacy concerns, associated with the deployment of AI-powered SLAs.
Towards Precision Characterization of Communication Disorders using Models of Perceived Pragmatic Similarity
Sep 13, 2024



The diagnosis and treatment of individuals with communication disorders offers many opportunities for the application of speech technology, but research so far has not adequately considered: the diversity of conditions, the role of pragmatic deficits, and the challenges of limited data. This paper explores how a general-purpose model of perceived pragmatic similarity may overcome these limitations. It explains how it might support several use cases for clinicians and clients, and presents evidence that a simple model can provide value, and in particular can capture utterance aspects that are relevant to diagnoses of autism and specific language impairment.
FASA: a Flexible and Automatic Speech Aligner for Extracting High-quality Aligned Children Speech Data
Jun 25, 2024

Automatic Speech Recognition (ASR) for adults' speeches has made significant progress by employing deep neural network (DNN) models recently, but improvement in children's speech is still unsatisfactory due to children's speech's distinct characteristics. DNN models pre-trained on adult data often struggle in generalizing children's speeches with fine tuning because of the lack of high-quality aligned children's speeches. When generating datasets, human annotations are not scalable, and existing forced-alignment tools are not usable as they make impractical assumptions about the quality of the input transcriptions. To address these challenges, we propose a new forced-alignment tool, FASA, as a flexible and automatic speech aligner to extract high-quality aligned children's speech data from many of the existing noisy children's speech data. We demonstrate its usage on the CHILDES dataset and show that FASA can improve data quality by 13.6$\times$ over human annotations.