 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Tree Inference Enabled by FDSOI Ferroelectric FETs
Apr 06, 2026Artificial intelligence applications in autonomous driving, medical diagnostics, and financial systems increasingly demand machine learning models that can provide robust uncertainty quantification, interpretability, and noise resilience. Bayesian decision trees (BDTs) are attractive for these tasks because they combine probabilistic reasoning, interpretable decision-making, and robustness to noise. However, existing hardware implementations of BDTs based on CPUs and GPUs are limited by memory bottlenecks and irregular processing patterns, while multi-platform solutions exploiting analog content-addressable memory (ACAM) and Gaussian random number generators (GRNGs) introduce integration complexity and energy overheads. Here we report a monolithic FDSOI-FeFET hardware platform that natively supports both ACAM and GRNG functionalities. The ferroelectric polarization of FeFETs enables compact, energy-efficient multi-bit storage for ACAM, and band-to-band tunneling in the gate-to-drain overlap region and subsequent hole storage in the floating body provides a high-quality entropy source for GRNG. System-level evaluations demonstrate that the proposed architecture provides robust uncertainty estimation, interpretability, and noise tolerance with high energy efficiency. Under both dataset noise and device variations, it achieves over 40% higher classification accuracy on MNIST compared to conventional decision trees. Moreover, it delivers more than two orders of magnitude speedup over CPU and GPU baselines and over four orders of magnitude improvement in energy efficiency, making it a scalable solution for deploying BDTs in resource-constrained and safety-critical environments.
Trustworthy Tree-based Machine Learning by $MoS_2$ Flash-based Analog CAM with Inherent Soft Boundaries
Jul 16, 2025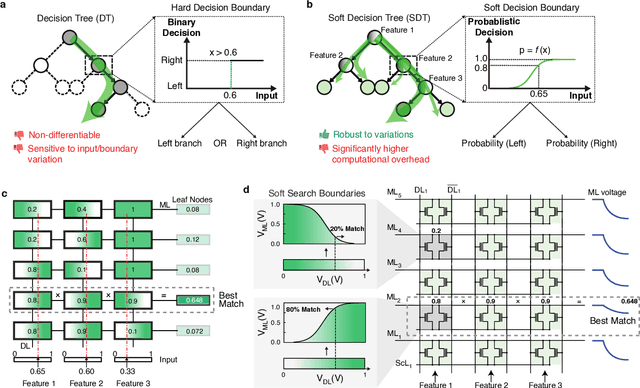
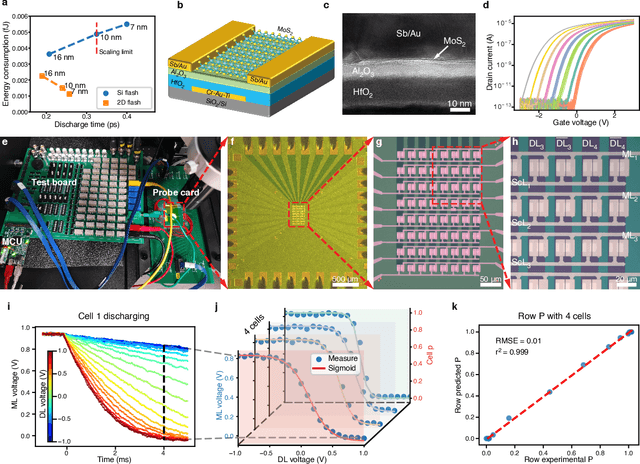
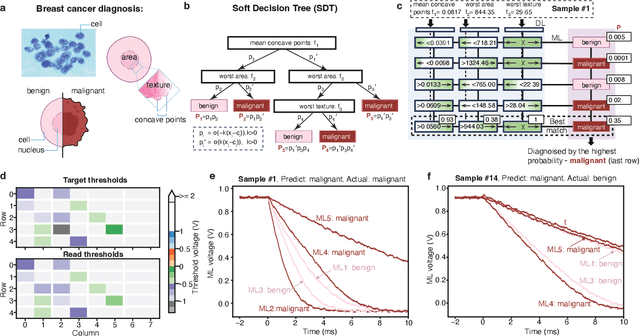
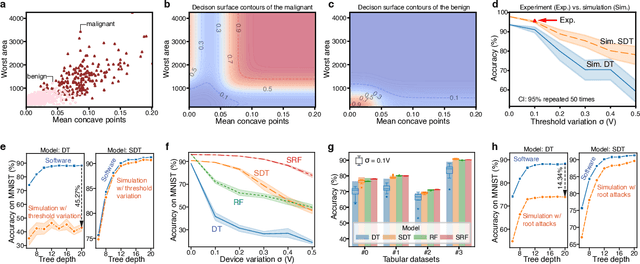
The rapid advancement of artificial intelligence has raised concerns regarding its trustworthiness, especially in terms of interpretability and robustness. Tree-based models like Random Forest and XGBoost excel in interpretability and accuracy for tabular data, but scaling them remains computationally expensive due to poor data locality and high data dependence. Previous efforts to accelerate these models with analog content addressable memory (CAM) have struggled, due to the fact that the difficult-to-implement sharp decision boundaries are highly susceptible to device variations, which leads to poor hardware performance and vulnerability to adversarial attacks. This work presents a novel hardware-software co-design approach using $MoS_2$ Flash-based analog CAM with inherent soft boundaries, enabling efficient inference with soft tree-based models. Our soft tree model inference experiments on $MoS_2$ analog CAM arrays show this method achieves exceptional robustness against device variation and adversarial attacks while achieving state-of-the-art accuracy. Specifically, our fabricated analog CAM arrays achieve $96\%$ accuracy on Wisconsin Diagnostic Breast Cancer (WDBC) database, while maintaining decision explainability. Our experimentally calibrated model validated only a $0.6\%$ accuracy drop on the MNIST dataset under $10\%$ device threshold variation, compared to a $45.3\%$ drop for traditional decision trees. This work paves the way for specialized hardware that enhances AI's trustworthiness and efficiency.
Tiny-Align: Bridging Automatic Speech Recognition and Large Language Model on the Edge
Nov 21, 2024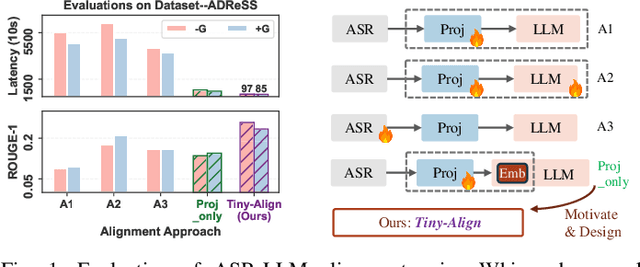
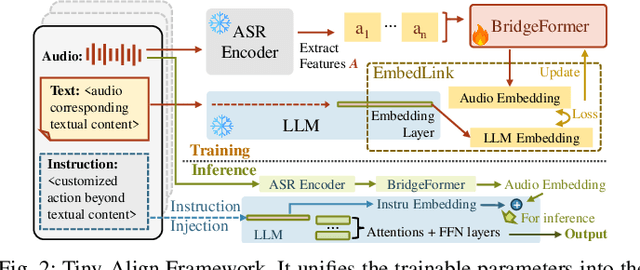
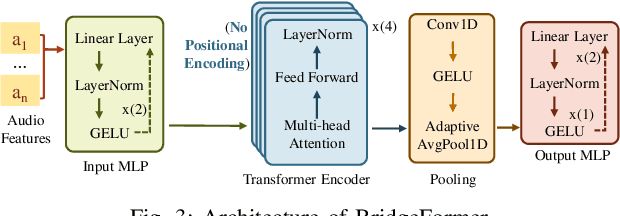
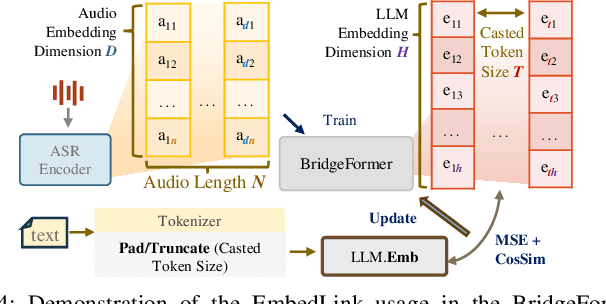
The combination of Large Language Models (LLM) and Automatic Speech Recognition (ASR), when deployed on edge devices (called edge ASR-LLM), can serve as a powerful personalized assistant to enable audio-based interaction for users. Compared to text-based interaction, edge ASR-LLM allows accessible and natural audio interactions. Unfortunately, existing ASR-LLM models are mainly trained in high-performance computing environments and produce substantial model weights, making them difficult to deploy on edge devices. More importantly, to better serve users' personalized needs, the ASR-LLM must be able to learn from each distinct user, given that audio input often contains highly personalized characteristics that necessitate personalized on-device training. Since individually fine-tuning the ASR or LLM often leads to suboptimal results due to modality-specific limitations, end-to-end training ensures seamless integration of audio features and language understanding (cross-modal alignment), ultimately enabling a more personalized and efficient adaptation on edge devices. However, due to the complex training requirements and substantial computational demands of existing approaches, cross-modal alignment between ASR audio and LLM can be challenging on edge devices. In this work, we propose a resource-efficient cross-modal alignment framework that bridges ASR and LLMs on edge devices to handle personalized audio input. Our framework enables efficient ASR-LLM alignment on resource-constrained devices like NVIDIA Jetson Orin (8GB RAM), achieving 50x training time speedup while improving the alignment quality by more than 50\%. To the best of our knowledge, this is the first work to study efficient ASR-LLM alignment on resource-constrained edge devices.
A 10.60 $μ$W 150 GOPS Mixed-Bit-Width Sparse CNN Accelerator for Life-Threatening Ventricular Arrhythmia Detection
Oct 22, 2024



This paper proposes an ultra-low power, mixed-bit-width sparse convolutional neural network (CNN) accelerator to accelerate ventricular arrhythmia (VA) detection. The chip achieves 50% sparsity in a quantized 1D CNN using a sparse processing element (SPE) architecture. Measurement on the prototype chip TSMC 40nm CMOS low-power (LP) process for the VA classification task demonstrates that it consumes 10.60 $\mu$W of power while achieving a performance of 150 GOPS and a diagnostic accuracy of 99.95%. The computation power density is only 0.57 $\mu$W/mm$^2$, which is 14.23X smaller than state-of-the-art works, making it highly suitable for implantable and wearable medical devices.
Efficient approximation of Earth Mover's Distance Based on Nearest Neighbor Search
Jan 20, 2024



Earth Mover's Distance (EMD) is an important similarity measure between two distributions, used in computer vision and many other application domains. However, its exact calculation is computationally and memory intensive, which hinders its scalability and applicability for large-scale problems. Various approximate EMD algorithms have been proposed to reduce computational costs, but they suffer lower accuracy and may require additional memory usage or manual parameter tuning. In this paper, we present a novel approach, NNS-EMD, to approximate EMD using Nearest Neighbor Search (NNS), in order to achieve high accuracy, low time complexity, and high memory efficiency. The NNS operation reduces the number of data points compared in each NNS iteration and offers opportunities for parallel processing. We further accelerate NNS-EMD via vectorization on GPU, which is especially beneficial for large datasets. We compare NNS-EMD with both the exact EMD and state-of-the-art approximate EMD algorithms on image classification and retrieval tasks. We also apply NNS-EMD to calculate transport mapping and realize color transfer between images. NNS-EMD can be 44x to 135x faster than the exact EMD implementation, and achieves superior accuracy, speedup, and memory efficiency over existing approximate EMD methods.
Data-Driven Deep Supervision for Skin Lesion Classification
Sep 04, 2022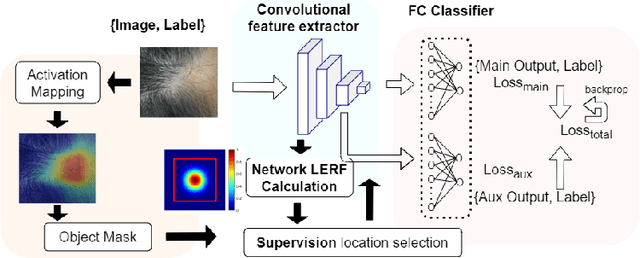
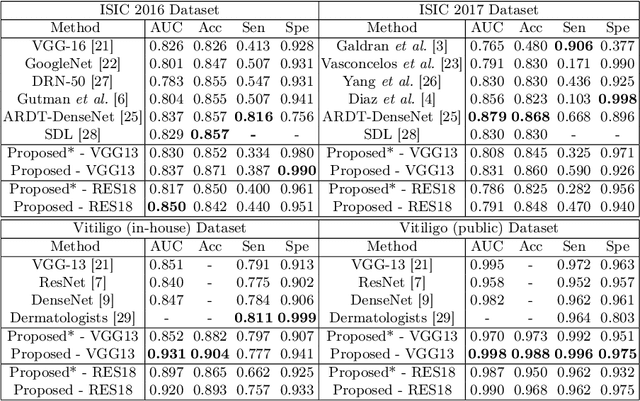
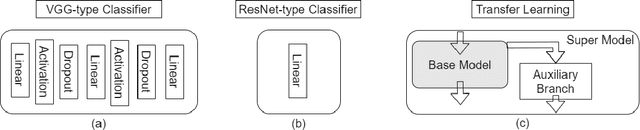

Automatic classification of pigmented, non-pigmented, and depigmented non-melanocytic skin lesions have garnered lots of attention in recent years. However, imaging variations in skin texture, lesion shape, depigmentation contrast, lighting condition, etc. hinder robust feature extraction, affecting classification accuracy. In this paper, we propose a new deep neural network that exploits input data for robust feature extraction. Specifically, we analyze the convolutional network's behavior (field-of-view) to find the location of deep supervision for improved feature extraction. To achieve this, first, we perform activation mapping to generate an object mask, highlighting the input regions most critical for classification output generation. Then the network layer whose layer-wise effective receptive field matches the approximated object shape in the object mask is selected as our focus for deep supervision. Utilizing different types of convolutional feature extractors and classifiers on three melanoma detection datasets and two vitiligo detection datasets, we verify the effectiveness of our new method.
Associative Memory Based Experience Replay for Deep Reinforcement Learning
Jul 16, 2022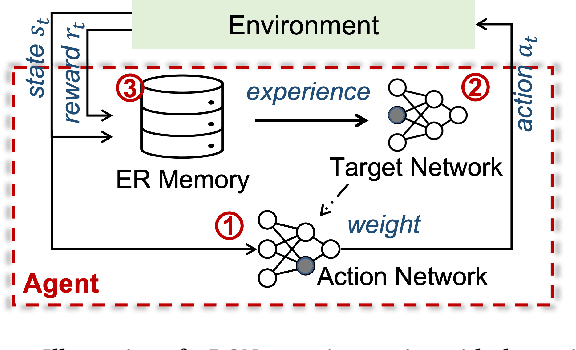
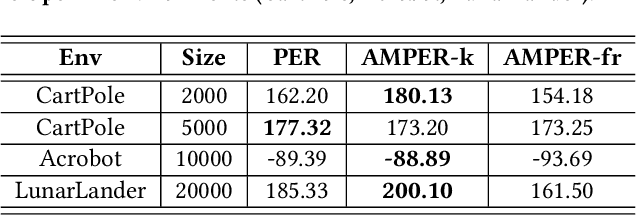
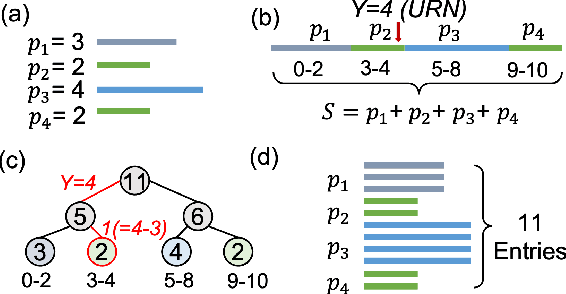
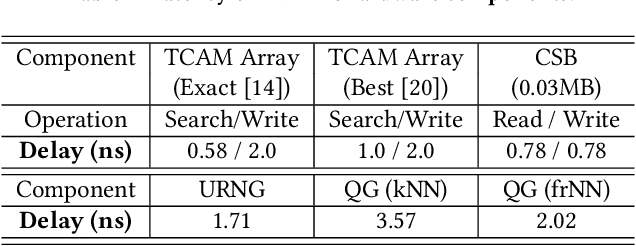
Experience replay is an essential component in deep reinforcement learning (DRL), which stores the experiences and generates experiences for the agent to learn in real time. Recently, prioritized experience replay (PER) has been proven to be powerful and widely deployed in DRL agents. However, implementing PER on traditional CPU or GPU architectures incurs significant latency overhead due to its frequent and irregular memory accesses. This paper proposes a hardware-software co-design approach to design an associative memory (AM) based PER, AMPER, with an AM-friendly priority sampling operation. AMPER replaces the widely-used time-costly tree-traversal-based priority sampling in PER while preserving the learning performance. Further, we design an in-memory computing hardware architecture based on AM to support AMPER by leveraging parallel in-memory search operations. AMPER shows comparable learning performance while achieving 55x to 270x latency improvement when running on the proposed hardware compared to the state-of-the-art PER running on GPU.
Experimentally realized memristive memory augmented neural network
Apr 15, 2022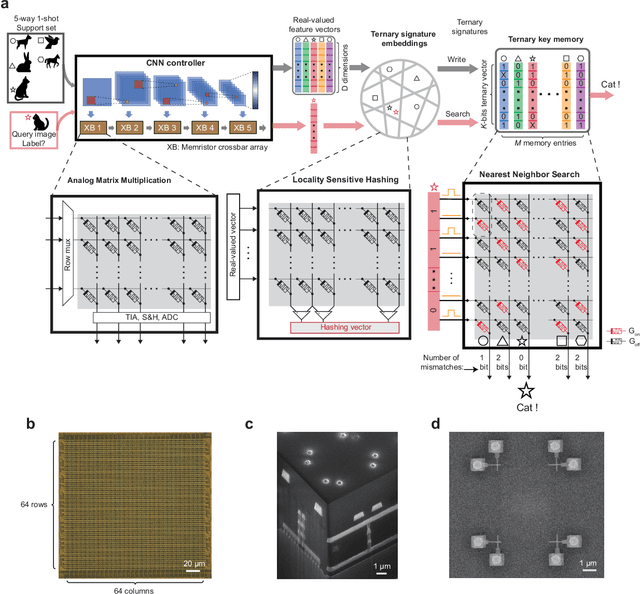
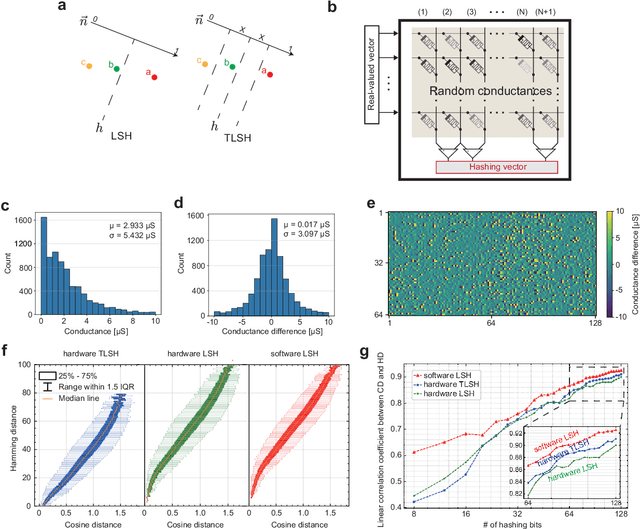
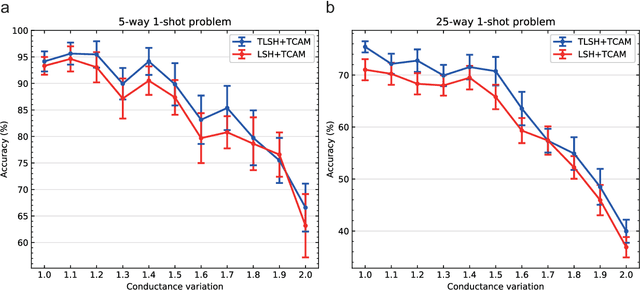
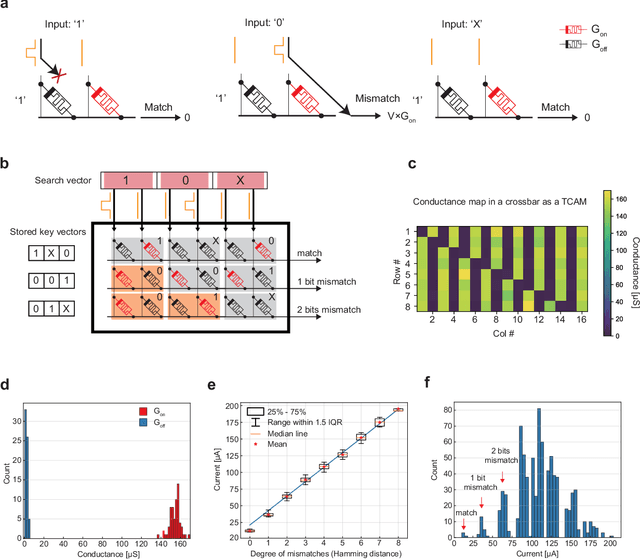
Lifelong on-device learning is a key challenge for machine intelligence, and this requires learning from few, often single, samples. Memory augmented neural network has been proposed to achieve the goal, but the memory module has to be stored in an off-chip memory due to its size. Therefore the practical use has been heavily limited. Previous works on emerging memory-based implementation have difficulties in scaling up because different modules with various structures are difficult to integrate on the same chip and the small sense margin of the content addressable memory for the memory module heavily limited the degree of mismatch calculation. In this work, we implement the entire memory augmented neural network architecture in a fully integrated memristive crossbar platform and achieve an accuracy that closely matches standard software on digital hardware for the Omniglot dataset. The successful demonstration is supported by implementing new functions in crossbars in addition to widely reported matrix multiplications. For example, the locality-sensitive hashing operation is implemented in crossbar arrays by exploiting the intrinsic stochasticity of memristor devices. Besides, the content-addressable memory module is realized in crossbars, which also supports the degree of mismatches. Simulations based on experimentally validated models show such an implementation can be efficiently scaled up for one-shot learning on the Mini-ImageNet dataset. The successful demonstration paves the way for practical on-device lifelong learning and opens possibilities for novel attention-based algorithms not possible in conventional hardware.
Image Complexity Guided Network Compression for Biomedical Image Segmentation
Jul 06, 2021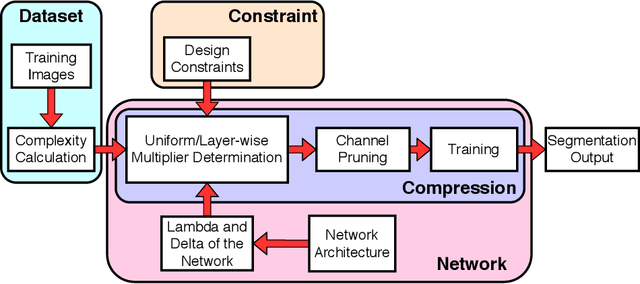
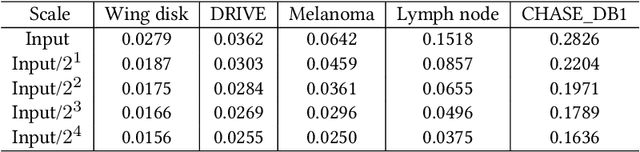
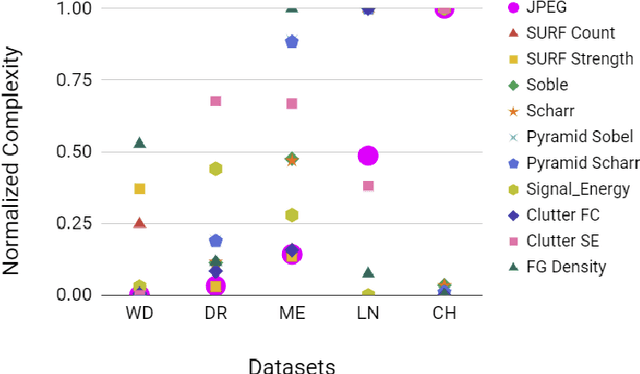
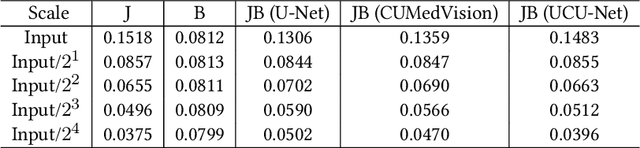
Compression is a standard procedure for making convolutional neural networks (CNNs) adhere to some specific computing resource constraints. However, searching for a compressed architecture typically involves a series of time-consuming training/validation experiments to determine a good compromise between network size and performance accuracy. To address this, we propose an image complexity-guided network compression technique for biomedical image segmentation. Given any resource constraints, our framework utilizes data complexity and network architecture to quickly estimate a compressed model which does not require network training. Specifically, we map the dataset complexity to the target network accuracy degradation caused by compression. Such mapping enables us to predict the final accuracy for different network sizes, based on the computed dataset complexity. Thus, one may choose a solution that meets both the network size and segmentation accuracy requirements. Finally, the mapping is used to determine the convolutional layer-wise multiplicative factor for generating a compressed network. We conduct experiments using 5 datasets, employing 3 commonly-used CNN architectures for biomedical image segmentation as representative networks. Our proposed framework is shown to be effective for generating compressed segmentation networks, retaining up to $\approx 95\%$ of the full-sized network segmentation accuracy, and at the same time, utilizing $\approx 32x$ fewer network trainable weights (average reduction) of the full-sized networks.
Objective-Dependent Uncertainty Driven Retinal Vessel Segmentation
Apr 17, 2021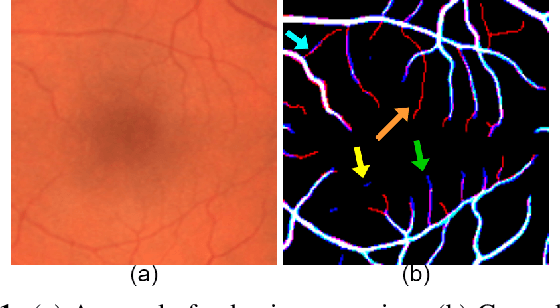
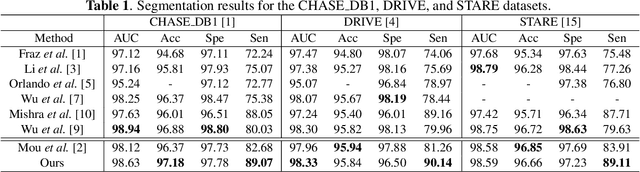
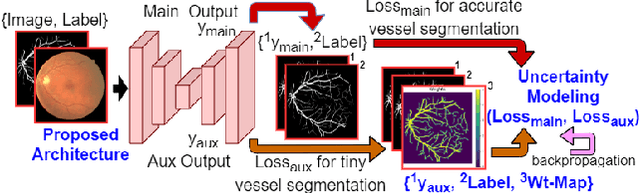
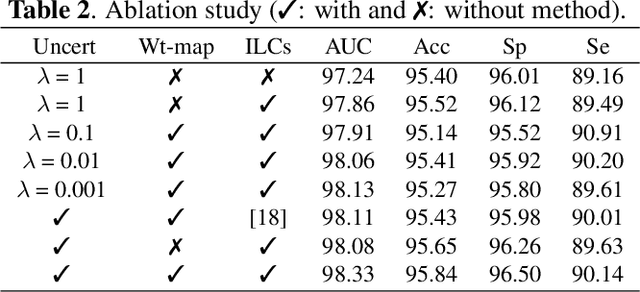
From diagnosing neovascular diseases to detecting white matter lesions, accurate tiny vessel segmentation in fundus images is critical. Promising results for accurate vessel segmentation have been known. However, their effectiveness in segmenting tiny vessels is still limited. In this paper, we study retinal vessel segmentation by incorporating tiny vessel segmentation into our framework for the overall accurate vessel segmentation. To achieve this, we propose a new deep convolutional neural network (CNN) which divides vessel segmentation into two separate objectives. Specifically, we consider the overall accurate vessel segmentation and tiny vessel segmentation as two individual objectives. Then, by exploiting the objective-dependent (homoscedastic) uncertainty, we enable the network to learn both objectives simultaneously. Further, to improve the individual objectives, we propose: (a) a vessel weight map based auxiliary loss for enhancing tiny vessel connectivity (i.e., improving tiny vessel segmentation), and (b) an enhanced encoder-decoder architecture for improved localization (i.e., for accurate vessel segmentation). Using 3 public retinal vessel segmentation datasets (CHASE_DB1, DRIVE, and STARE), we verify the superiority of our proposed framework in segmenting tiny vessels (8.3% average improvement in sensitivity) while achieving better area under the receiver operating characteristic curve (AUC) compared to state-of-the-art methods.