 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKETM:A Knowledge-Enhanced Text Matching method
Aug 11, 2023Text matching is the task of matching two texts and determining the relationship between them, which has extensive applications in natural language processing tasks such as reading comprehension, and Question-Answering systems. The mainstream approach is to compute text representations or to interact with the text through attention mechanism, which is effective in text matching tasks. However, the performance of these models is insufficient for texts that require commonsense knowledge-based reasoning. To this end, in this paper, We introduce a new model for text matching called the Knowledge Enhanced Text Matching model (KETM), to enrich contextual representations with real-world common-sense knowledge from external knowledge sources to enhance our model understanding and reasoning. First, we use Wiktionary to retrieve the text word definitions as our external knowledge. Secondly, we feed text and knowledge to the text matching module to extract their feature vectors. The text matching module is used as an interaction module by integrating the encoder layer, the co-attention layer, and the aggregation layer. Specifically, the interaction process is iterated several times to obtain in-depth interaction information and extract the feature vectors of text and knowledge by multi-angle pooling. Then, we fuse text and knowledge using a gating mechanism to learn the ratio of text and knowledge fusion by a neural network that prevents noise generated by knowledge. After that, experimental validation on four datasets are carried out, and the experimental results show that our proposed model performs well on all four datasets, and the performance of our method is improved compared to the base model without adding external knowledge, which validates the effectiveness of our proposed method. The code is available at https://github.com/1094701018/KETM
Experimentally realized memristive memory augmented neural network
Apr 15, 2022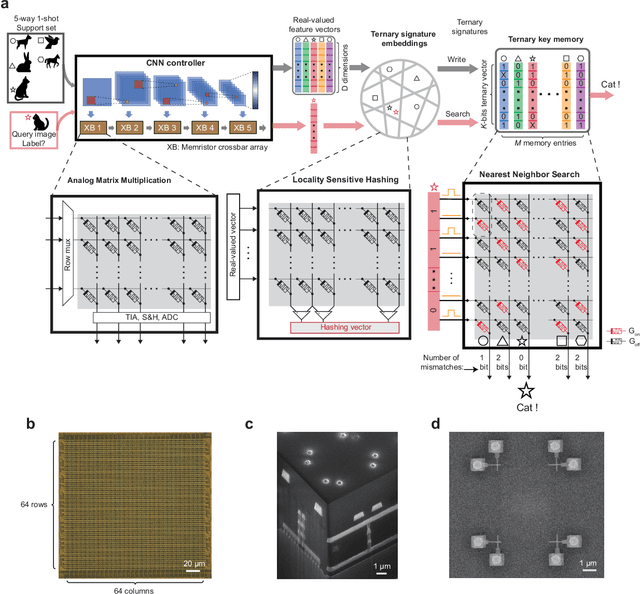
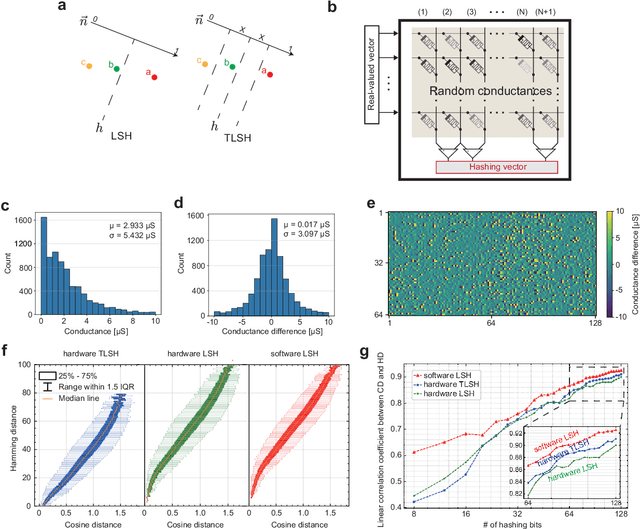
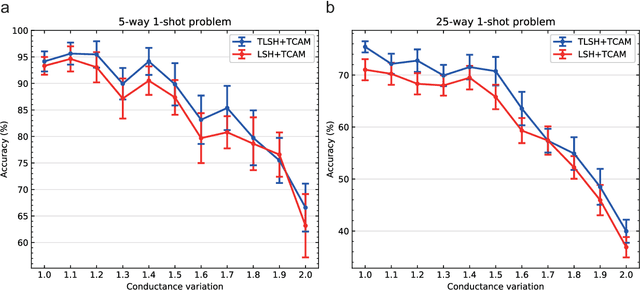
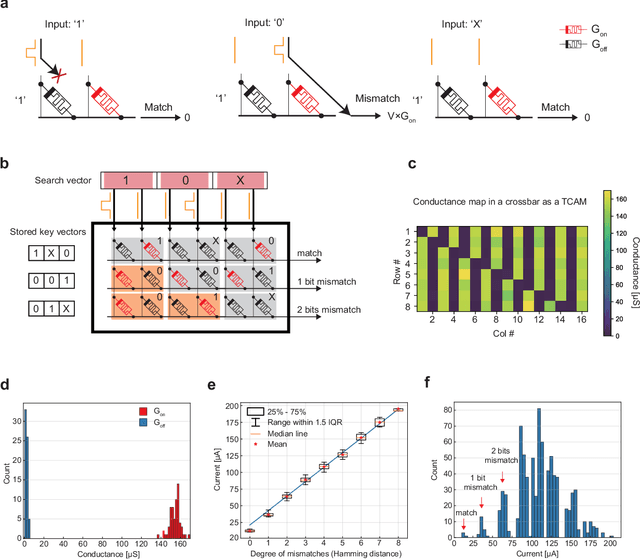
Lifelong on-device learning is a key challenge for machine intelligence, and this requires learning from few, often single, samples. Memory augmented neural network has been proposed to achieve the goal, but the memory module has to be stored in an off-chip memory due to its size. Therefore the practical use has been heavily limited. Previous works on emerging memory-based implementation have difficulties in scaling up because different modules with various structures are difficult to integrate on the same chip and the small sense margin of the content addressable memory for the memory module heavily limited the degree of mismatch calculation. In this work, we implement the entire memory augmented neural network architecture in a fully integrated memristive crossbar platform and achieve an accuracy that closely matches standard software on digital hardware for the Omniglot dataset. The successful demonstration is supported by implementing new functions in crossbars in addition to widely reported matrix multiplications. For example, the locality-sensitive hashing operation is implemented in crossbar arrays by exploiting the intrinsic stochasticity of memristor devices. Besides, the content-addressable memory module is realized in crossbars, which also supports the degree of mismatches. Simulations based on experimentally validated models show such an implementation can be efficiently scaled up for one-shot learning on the Mini-ImageNet dataset. The successful demonstration paves the way for practical on-device lifelong learning and opens possibilities for novel attention-based algorithms not possible in conventional hardware.
DEIM: An effective deep encoding and interaction model for sentence matching
Mar 20, 2022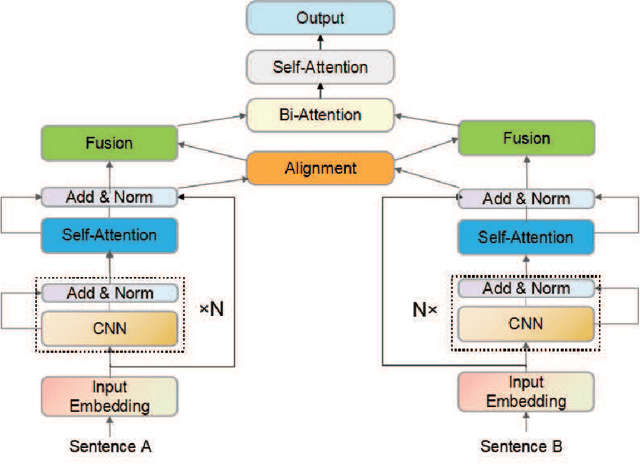
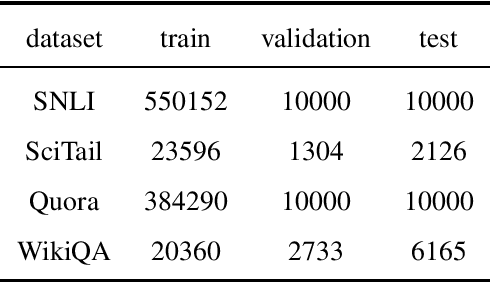


Natural language sentence matching is the task of comparing two sentences and identifying the relationship between them.It has a wide range of applications in natural language processing tasks such as reading comprehension, question and answer systems. The main approach is to compute the interaction between text representations and sentence pairs through an attention mechanism, which can extract the semantic information between sentence pairs well. However,this kind of method can not gain satisfactory results when dealing with complex semantic features. To solve this problem, we propose a sentence matching method based on deep encoding and interaction to extract deep semantic information. In the encoder layer,we refer to the information of another sentence in the process of encoding a single sentence, and later use a heuristic algorithm to fuse the information. In the interaction layer, we use a bidirectional attention mechanism and a self-attention mechanism to obtain deep semantic information.Finally, we perform a pooling operation and input it to the MLP for classification. we evaluate our model on three tasks: recognizing textual entailment, paraphrase recognition, and answer selection. We conducted experiments on the SNLI and SciTail datasets for the recognizing textual entailment task, the Quora dataset for the paraphrase recognition task, and the WikiQA dataset for the answer selection task. The experimental results show that the proposed algorithm can effectively extract deep semantic features that verify the effectiveness of the algorithm on sentence matching tasks.
DTWSSE: Data Augmentation with a Siamese Encoder for Time Series
Aug 23, 2021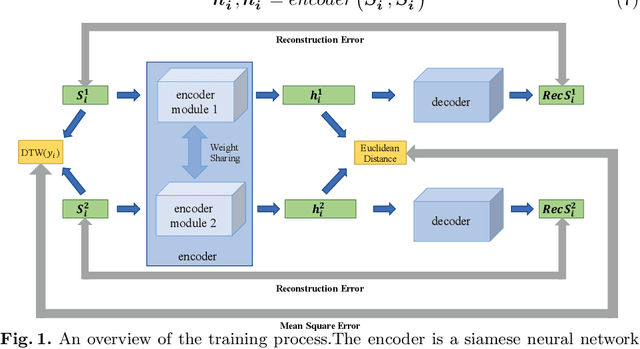
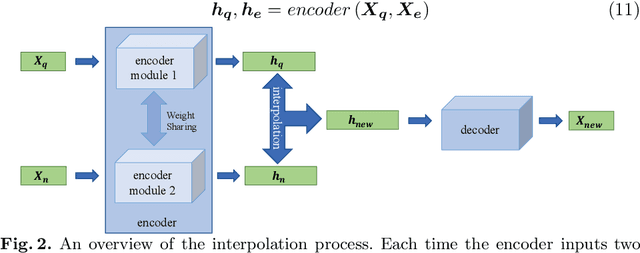

Access to labeled time series data is often limited in the real world, which constrains the performance of deep learning models in the field of time series analysis. Data augmentation is an effective way to solve the problem of small sample size and imbalance in time series datasets. The two key factors of data augmentation are the distance metric and the choice of interpolation method. SMOTE does not perform well on time series data because it uses a Euclidean distance metric and interpolates directly on the object. Therefore, we propose a DTW-based synthetic minority oversampling technique using siamese encoder for interpolation named DTWSSE. In order to reasonably measure the distance of the time series, DTW, which has been verified to be an effective method forts, is employed as the distance metric. To adapt the DTW metric, we use an autoencoder trained in an unsupervised self-training manner for interpolation. The encoder is a Siamese Neural Network for mapping the time series data from the DTW hidden space to the Euclidean deep feature space, and the decoder is used to map the deep feature space back to the DTW hidden space. We validate the proposed methods on a number of different balanced or unbalanced time series datasets. Experimental results show that the proposed method can lead to better performance of the downstream deep learning model.