 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssociative Memory Based Experience Replay for Deep Reinforcement Learning
Jul 16, 2022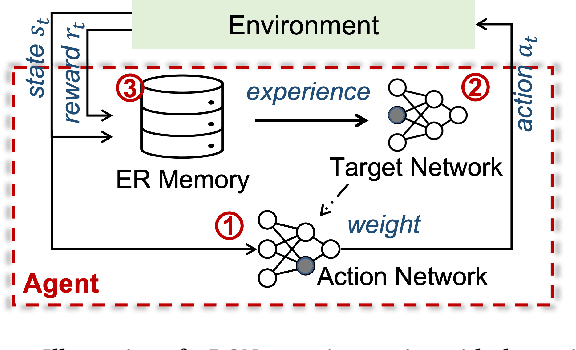
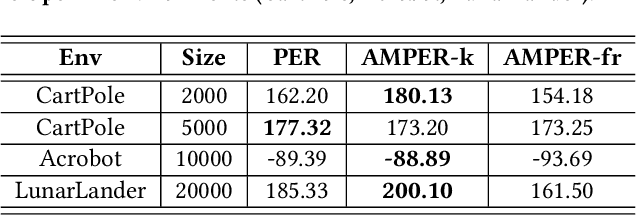
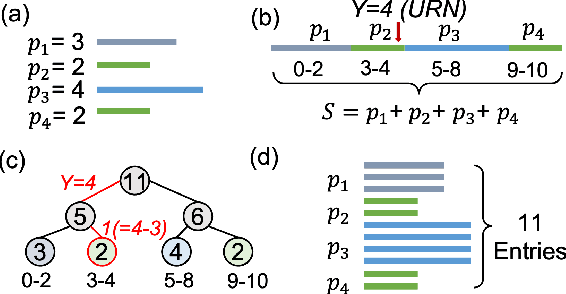
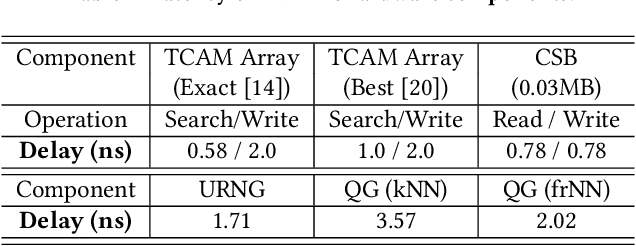
Experience replay is an essential component in deep reinforcement learning (DRL), which stores the experiences and generates experiences for the agent to learn in real time. Recently, prioritized experience replay (PER) has been proven to be powerful and widely deployed in DRL agents. However, implementing PER on traditional CPU or GPU architectures incurs significant latency overhead due to its frequent and irregular memory accesses. This paper proposes a hardware-software co-design approach to design an associative memory (AM) based PER, AMPER, with an AM-friendly priority sampling operation. AMPER replaces the widely-used time-costly tree-traversal-based priority sampling in PER while preserving the learning performance. Further, we design an in-memory computing hardware architecture based on AM to support AMPER by leveraging parallel in-memory search operations. AMPER shows comparable learning performance while achieving 55x to 270x latency improvement when running on the proposed hardware compared to the state-of-the-art PER running on GPU.
Experimentally realized memristive memory augmented neural network
Apr 15, 2022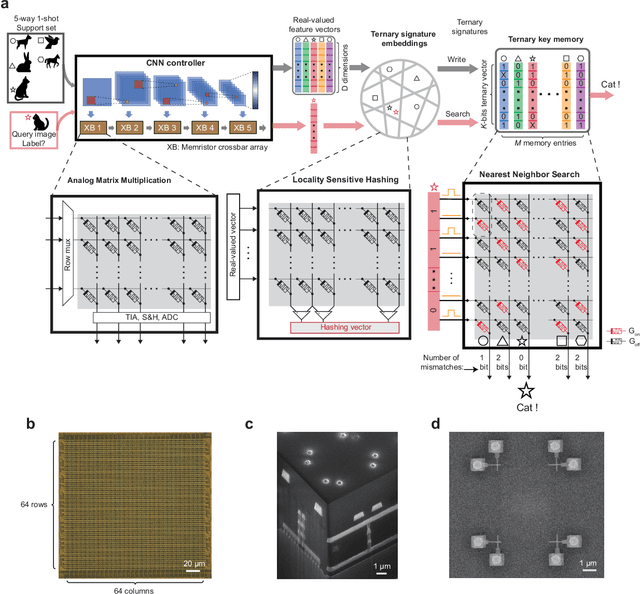
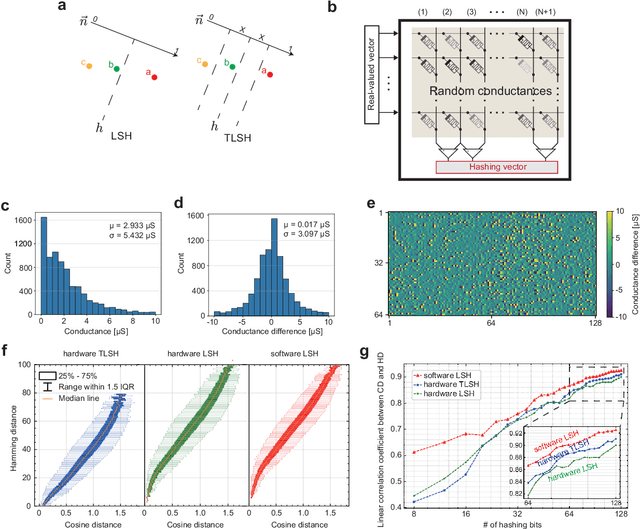
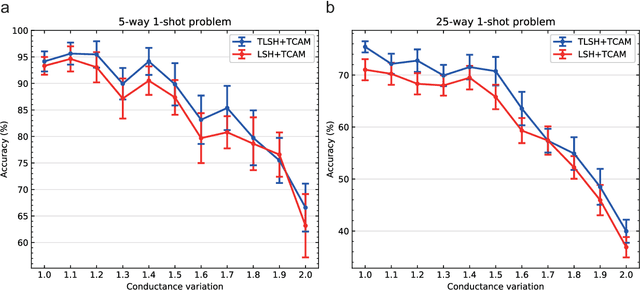
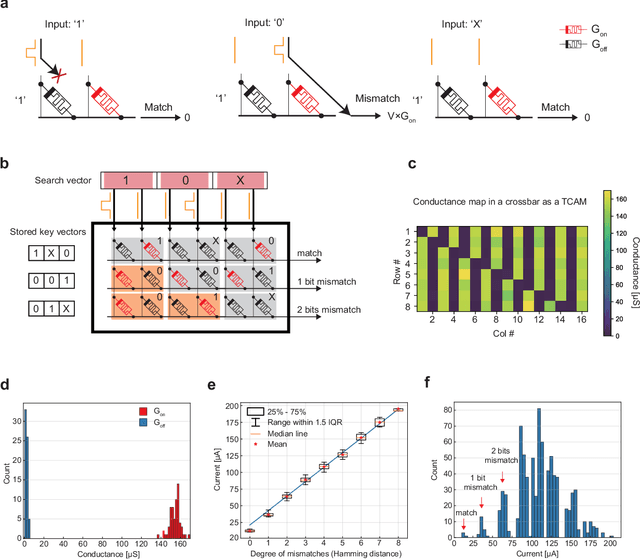
Lifelong on-device learning is a key challenge for machine intelligence, and this requires learning from few, often single, samples. Memory augmented neural network has been proposed to achieve the goal, but the memory module has to be stored in an off-chip memory due to its size. Therefore the practical use has been heavily limited. Previous works on emerging memory-based implementation have difficulties in scaling up because different modules with various structures are difficult to integrate on the same chip and the small sense margin of the content addressable memory for the memory module heavily limited the degree of mismatch calculation. In this work, we implement the entire memory augmented neural network architecture in a fully integrated memristive crossbar platform and achieve an accuracy that closely matches standard software on digital hardware for the Omniglot dataset. The successful demonstration is supported by implementing new functions in crossbars in addition to widely reported matrix multiplications. For example, the locality-sensitive hashing operation is implemented in crossbar arrays by exploiting the intrinsic stochasticity of memristor devices. Besides, the content-addressable memory module is realized in crossbars, which also supports the degree of mismatches. Simulations based on experimentally validated models show such an implementation can be efficiently scaled up for one-shot learning on the Mini-ImageNet dataset. The successful demonstration paves the way for practical on-device lifelong learning and opens possibilities for novel attention-based algorithms not possible in conventional hardware.
Deep Random Forest with Ferroelectric Analog Content Addressable Memory
Oct 06, 2021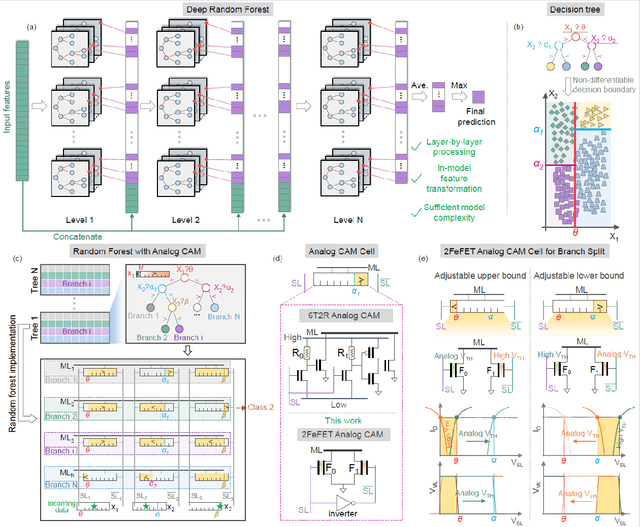
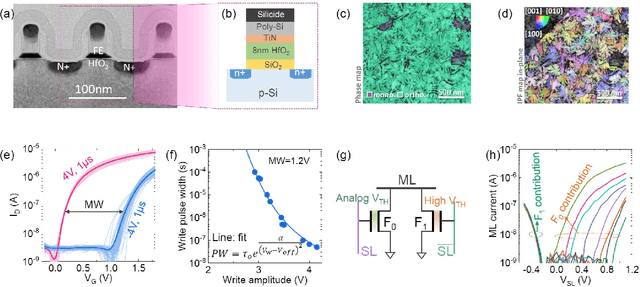
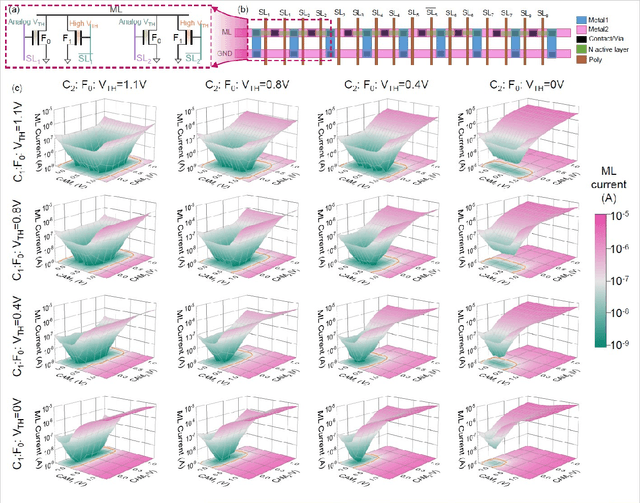
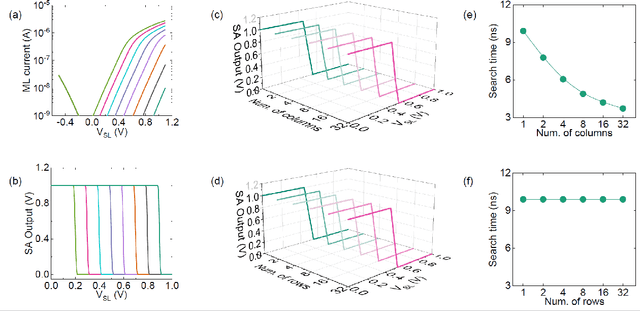
Deep random forest (DRF), which incorporates the core features of deep learning and random forest (RF), exhibits comparable classification accuracy, interpretability, and low memory and computational overhead when compared with deep neural networks (DNNs) in various information processing tasks for edge intelligence. However, the development of efficient hardware to accelerate DRF is lagging behind its DNN counterparts. The key for hardware acceleration of DRF lies in efficiently realizing the branch-split operation at decision nodes when traversing a decision tree. In this work, we propose to implement DRF through simple associative searches realized with ferroelectric analog content addressable memory (ACAM). Utilizing only two ferroelectric field effect transistors (FeFETs), the ultra-compact ACAM cell can perform a branch-split operation with an energy-efficient associative search by storing the decision boundaries as the analog polarization states in an FeFET. The DRF accelerator architecture and the corresponding mapping of the DRF model to the ACAM arrays are presented. The functionality, characteristics, and scalability of the FeFET ACAM based DRF and its robustness against FeFET device non-idealities are validated both in experiments and simulations. Evaluation results show that the FeFET ACAM DRF accelerator exhibits 10^6x/16x and 10^6x/2.5x improvements in terms of energy and latency when compared with other deep random forest hardware implementations on the state-of-the-art CPU/ReRAM, respectively.
In-Memory Nearest Neighbor Search with FeFET Multi-Bit Content-Addressable Memories
Nov 13, 2020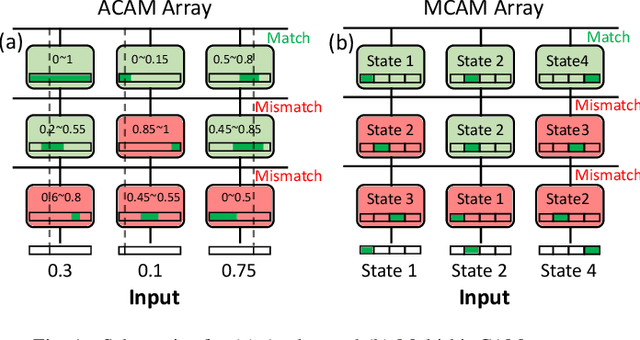
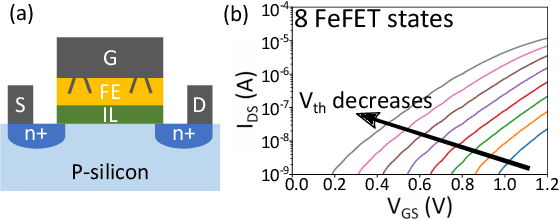
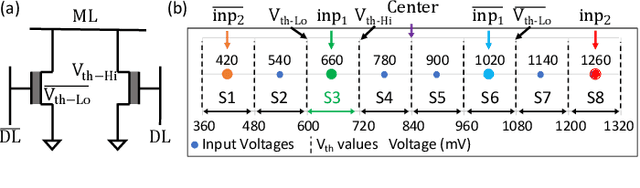
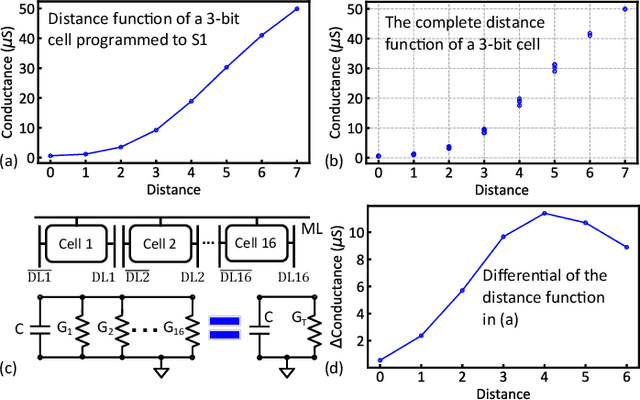
Nearest neighbor (NN) search is an essential operation in many applications, such as one/few-shot learning and image classification. As such, fast and low-energy hardware support for accurate NN search is highly desirable. Ternary content-addressable memories (TCAMs) have been proposed to accelerate NN search for few-shot learning tasks by implementing $L_\infty$ and Hamming distance metrics, but they cannot achieve software-comparable accuracies. This paper proposes a novel distance function that can be natively evaluated with multi-bit content-addressable memories (MCAMs) based on ferroelectric FETs (FeFETs) to perform a single-step, in-memory NN search. Moreover, this approach achieves accuracies comparable to floating-point precision implementations in software for NN classification and one/few-shot learning tasks. As an example, the proposed method achieves a 98.34% accuracy for a 5-way, 5-shot classification task for the Omniglot dataset (only 0.8% lower than software-based implementations) with a 3-bit MCAM. This represents a 13% accuracy improvement over state-of-the-art TCAM-based implementations at iso-energy and iso-delay. The presented distance function is resilient to the effects of FeFET device-to-device variations. Furthermore, this work experimentally demonstrates a 2-bit implementation of FeFET MCAM using AND arrays from GLOBALFOUNDRIES to further validate proof of concept.